402-电影天堂
0.说明
本次是加深对正则表达式与逻辑判断的一次训练
如有错误请指出
学习网站为:https://www.bilibili.com/video/BV1i54y1h75W
使用网址为:https://www.dytt89.com/
1.安全验证
需要在get请求内加上(domain,verify=False),如果不加,电影天堂会认为你的访问是不安全的,从而拒绝你的访问
2.字符集
resp.encoding = 'gb2312' # 自己选定编码方式
Python默认字符集是utf-8,但是电影天堂的字符集是gb2312,如果字符集不匹配就会出现乱码,所以需要修改python内的requests的所使用的字符集
3.匹配首页的大项
截图1如下
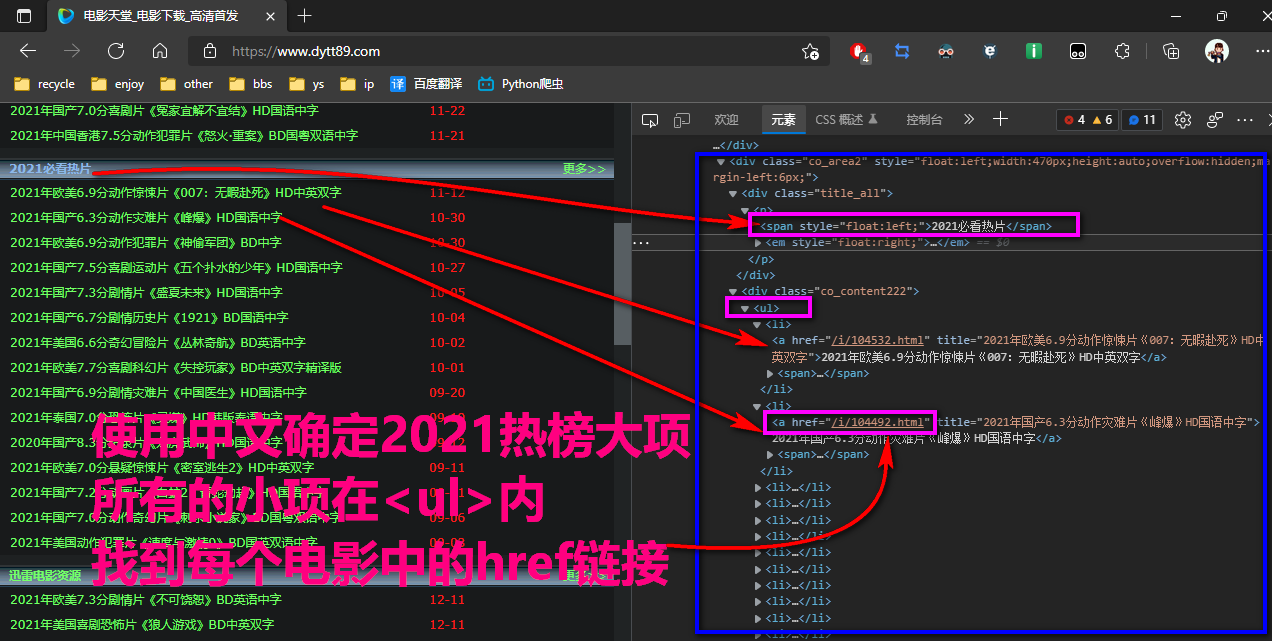
图内为首页的大项的html内容,使用正则获取蓝框内容,这个正则不难
re2 = re.compile(r"2021必看热片.*?<ul>(?P<ull>.*?)</ul>",re.S)
iter2 = re2.finditer(html_text)
整个大项的内容就都存在于iter2这个迭代器内
4.获取子页面href
使用一个列表用来存放最后要访问的href
child_href_list = []
child_href_list.append(child_href)
刚刚说所有的信息在iter2这个迭代器内,将数据取得
bkrp = i2.group("ull")
再启用一个新的正则,得到里面的href链接,然后将其拼接,其中又可能需要加上上坡斜杠,可以使用调试进行打印查看
re3 = re.compile(r"<li><a href='(?P<href>.*?)'",re.S)
iter3 = re3.finditer(bkrp)
for i3 in iter3:
child_href = domain + i3.group("href").strip("/")
print(child_href)
child_href_list.append(child_href)
5.获取影名与链接
截图2如下
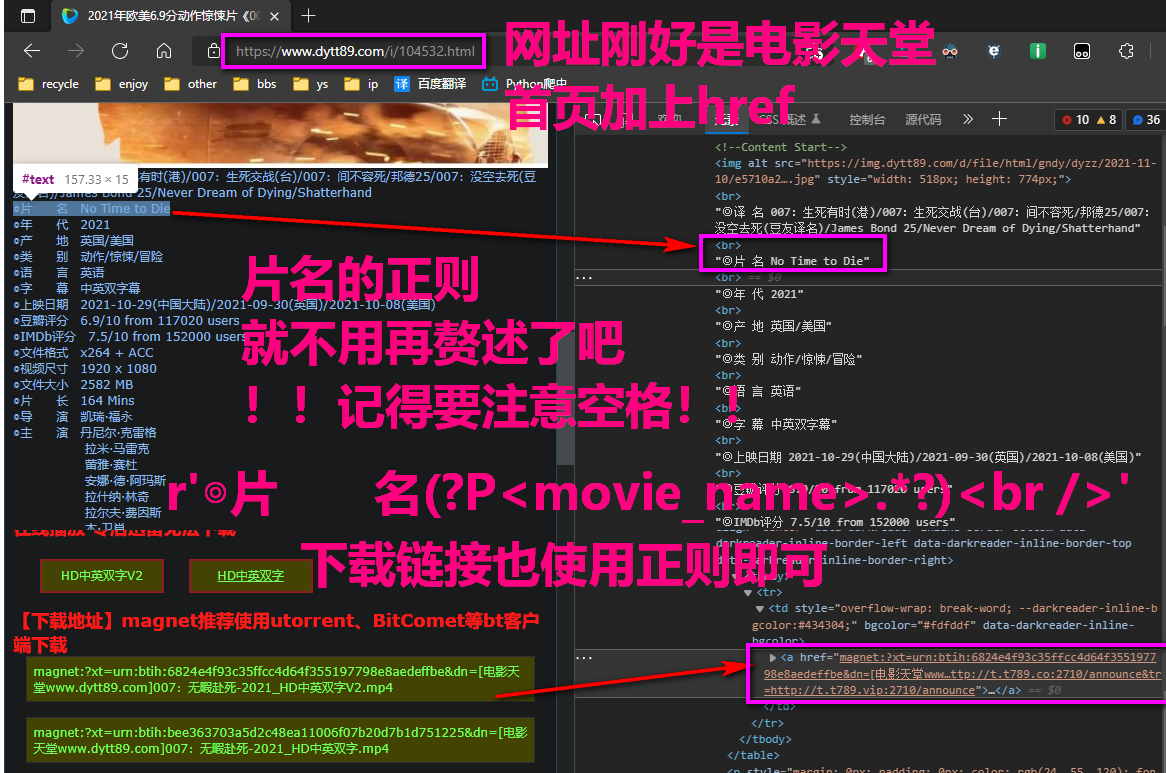
子页面的网址已经存放在child_href_list内,然后使用resp进行访问,注意编码方式与空格
re4 = re.compile(r'◎片 名(?P<movie_name>.*?)<br />'
r'.*?<div id="downlist".*?<a href=.*?>(?P<download_link>.*?)</a>'
,re.S)
6.结果截图(不完全)
截图3如下
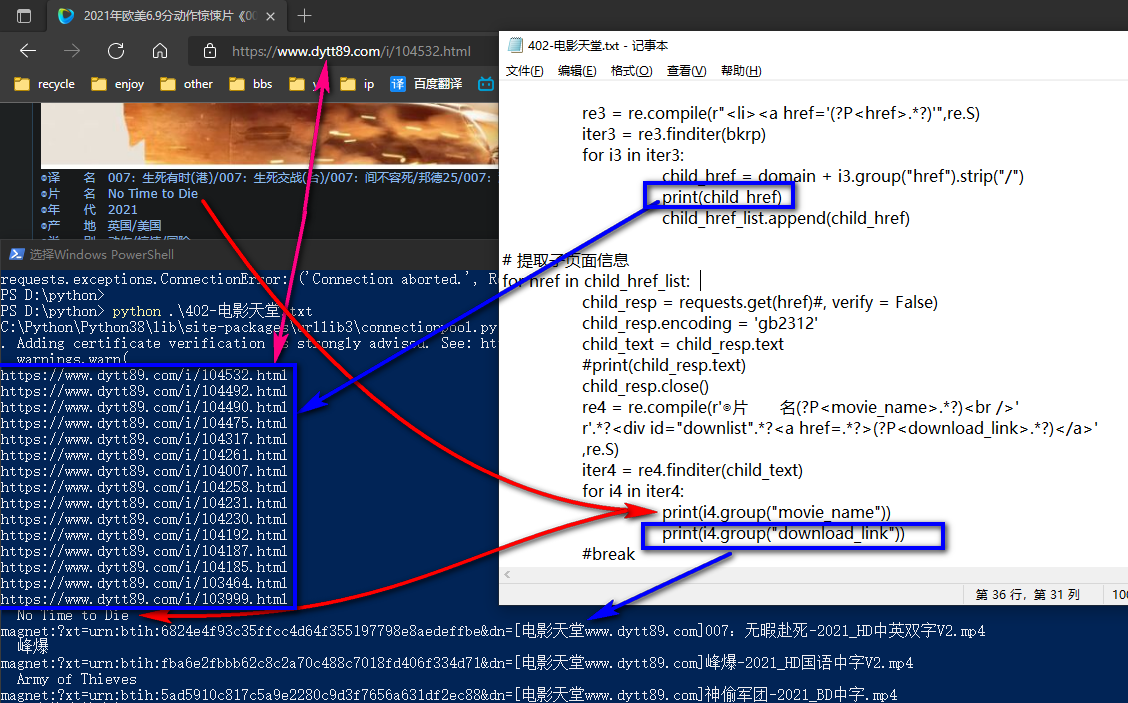
7.全部代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号