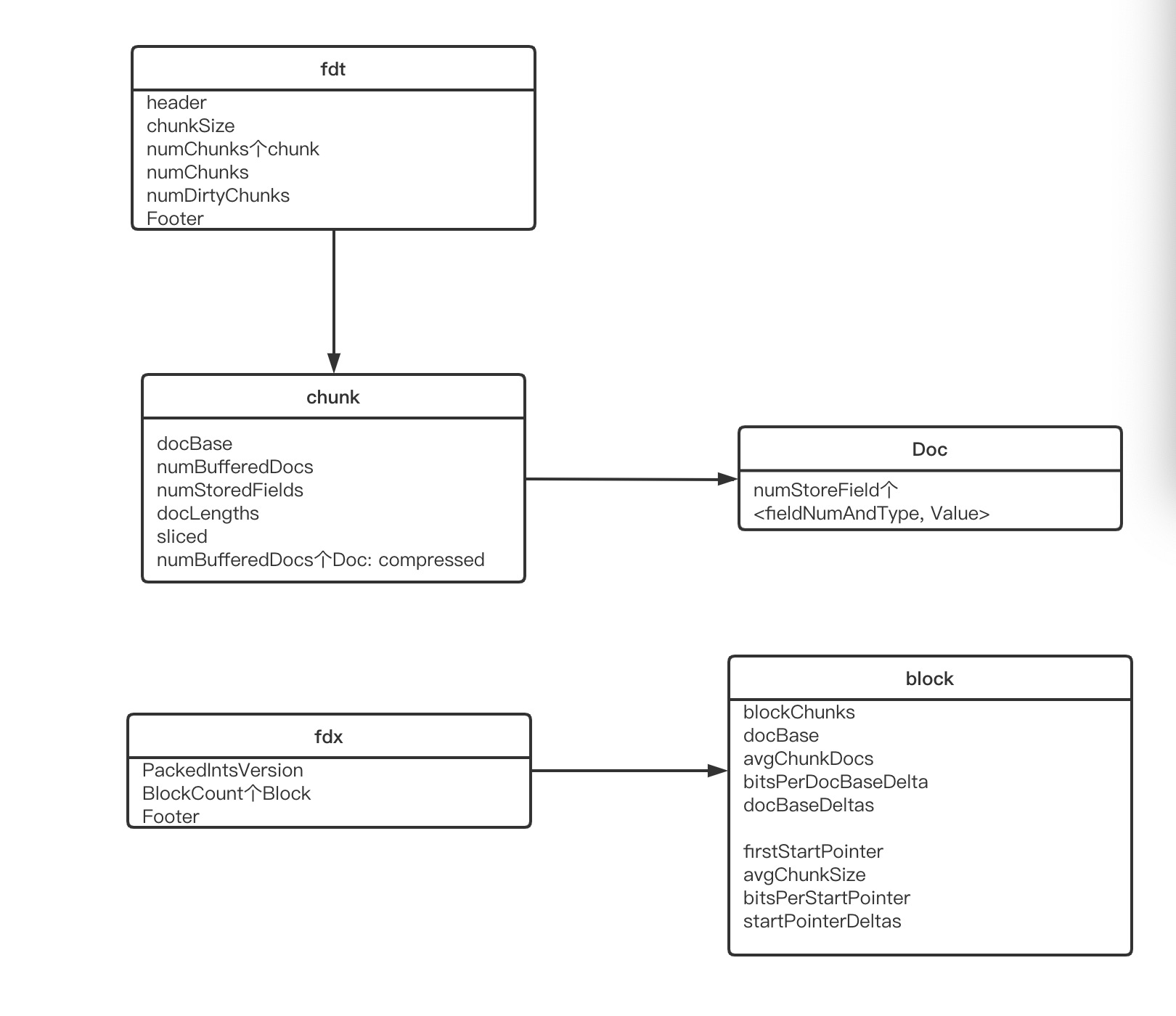
storedField涉及的主要文件有fdt, fdx. fdt用来分chunk存储数据, fdx来索引这些chunk。
fdt分析
fdt写入由CompressingStoredFieldsWriter实现。
主要field如下
chunkSize: 16K(1 << 14), Lucene50StoredFieldsFormat传入。
maxDocsPerChunk: 128, Lucene50StoredFieldsFormat传入。
bufferedDocs: chunk的docs数据,length大于等于chunkSize时, triggerFlush. bufferedDocs压缩存储, length >= 2chunkSize时,slice: 每chunkSize独立压缩。
numBufferedDocs: bufferedDocs num大于等于maxDocsPerChunk时, triggerFlush. docBase + numBufferedDocs == current docID.
docBase: segment当前要写的chunk的first docID. 直接使用numBufferedDocs计算,所以merge时,会去除deleted docs, 改变docID。
numStoredFields: chunk中, 每个doc的storedField数量(DocFieldCounts, doc writeField时统计)。当chunk只有一个doc时,直接写该doc的storedField数量。
否则,写bitsRequired和counts:counts都相等时,bitsRequired为0,写一个count。counts不等时,bitsRequired记录最大的count所需的bits,写counts数组,每个count都填充到bitsRequired存储。
numStoredFieldsInDoc:当前doc的storeFields数量。
endOffsets: chunk中,每个doc的结束position(计算DocLengths,写入方式同DocDieldCounts)。
numChunks:该segment已经flush的ChunkCount(包括numDirtyChunks)。
numDirtyChunks:未达到chunkSize,maxDocsPerChunk的triggerFlush。而是达到整个segment的flush条件,或其他调用flush,触发的过早flush引起的写chunk次数。
flush segment时写入的numDirtyChunks只能是1或0,merge时,numDirtyChunks可能增加。
segment:用segment name确定fdt,fdx文件output。
indexWriter:写fdx。
fieldsStream:写fdt。
fieldsStream写fdt步骤
初始化时(new segment),写header, chunkSize等。
writeField:
写当前doc的一个storedField到bufferedDocs。
numStoredFieldsInDoc++
infoAndBits:写FieldNumAndType。
写Bytes(先写length),String,Int,Long,Float,Double等。
finishDocument
设置bufferedDocs,numBufferedDocs,numStoredFields,endOffsets,达到triggerFlush时,flush一个chunk。
flush
写一个chunk。
写fdx索引该chunk。
chunk docs的endOffsets转成lengths。
写header: docBase, numBufferedDocs(ChunkDocs), numStoredFields(DocFieldCounts), lengths(DocLengths), sliced(chunk bufferedDocs length >= 2chunkSize)
写bufferedDocs:压缩bufferedDocs,写入fdt。如果sliced,每16K独立压缩。
设置docBase(+= numBufferedDocs).
finish
flush fdt,ftx,写完整segment信息。
flush segment时引起flush chunk。
未达到triggerFlush写chunk,numDirtyChunks(DirtyChunkCount)++。
写numChunks,numDirtyChunks,写Footer。
fdx分析
fdx写入由CompressingStoredFieldsIndexWriter实现。
主要field如下
blockSize: 1024, 由Lucene50StoredFieldsFormat传入.
blockChunks: 当前block索引的chunk数量,达到blockSize时writeBlock.
docBaseDeltas: length 1024, 记录每个chunk实际docBase相对avgChunkDocs * chunkNumber的delta.
startPointerDeltas: length 1024, 记录每个chunk实际startPointer相对avgChunkBytes * chunkNumber的delta.
firstStartPointer: 一个block的第一个chunk的startPointer.
maxStartPointer: 一个block的最后一个chunk的startPointer.
blockDocs: 一个block所有chunk的doc数量.
totalDocs: 一个segment所有block的doc数量, 用于计算当前block的docBase(totalDocs - blockDocs).
fieldsIndexOut写步骤
writeIndex
fdt写入一个chunk数据之前, 传递chunkDocs, startPointer, 索引该chunk.
docBaseDelta初始记录为chunkDocs, startPointerDelta初始记录为上个chunk的size(startPointer-maxStartPointer, first chunk为0).
writeBlock
blockChunks达到1024, 或flush segment时, writeBlock.
write blockChunks: 小于等于1024.
write docBase.
avgChunkDocs: chunks平均doc数量的计算, 不考虑最后一个chunk.
for1: 计算maxDeltaDocBase, bitsPerDocBase, 构造写docBaseDeltas的writer.
for2: 计算每个chunk的docBaseDelta, 写入writer.
docBaseDelta = chunk实际docBase - avgChunkDocs * chunkNumber.
write firstStartPointer.
avgChunkSize: chunks平均size的计算, 不考虑最后一个chunk.
for3: 计算maxDeltaStartPointer, bitsPerStartPointer, 构造写startPointerDeltas的writer.
for4: 计算每个chunk的startPointerDelta, 写入writer.
startPointerDelta = chunk实际startPointer - avgChunkSize * chunkNumber.
finish
flush fdt,ftx,写完整segment信息。
flush segment时引起writeBlock。
写end marker,最后一个chunk的startPointer,Footer。
根据docID读取storedField算法
docBase(chunk(n)) = docBase + avgChunkDocs * n + docBaseDeltas[n].
startPointer(chunk(n)) = startPointerBase + avgChunkSize * n + startPointerDeltas[n].
fdx结构加载到内存后, 查找任何docID所在chunk的startPointer流程如下:
二分block的docBase, 找到docID所在的block; 二分chunk的docBase, 找到docID所在的chunk; 计算chunk的startPointer.
fdt,fdx文件结构如下图:
![]()
参考:
lucene8.4.1
Lucene50StoredFieldsFormat, CompressingStoredFieldsWriter, CompressingStoredFieldsIndexWriter.
https://issues.apache.org/jira/browse/LUCENE-4512
目的: 通过deltas代替实际docBases, startPointers节省内存.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号