SSD(single shot multibox detector)
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法,截至目前是主要的检测框架之一,相比Faster RCNN有明显的速度优势,相比YOLO又有明显的mAP优势(不过已经被CVPR 2017的YOLO9000超越)
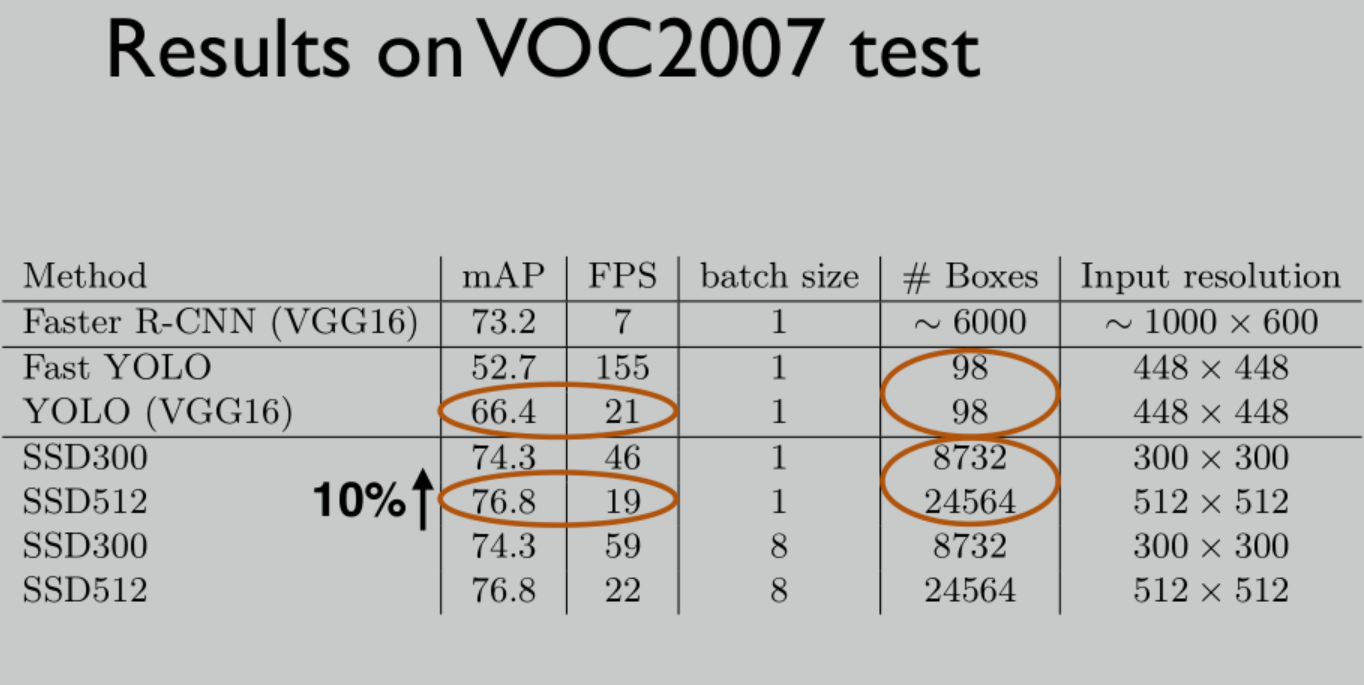
在VOC2007上,SSD300比Faster R-CNN的FPS高了6.6倍

在VOC2007上,SSD300比YOLP的mAP高了10%
1.SSD网络结构
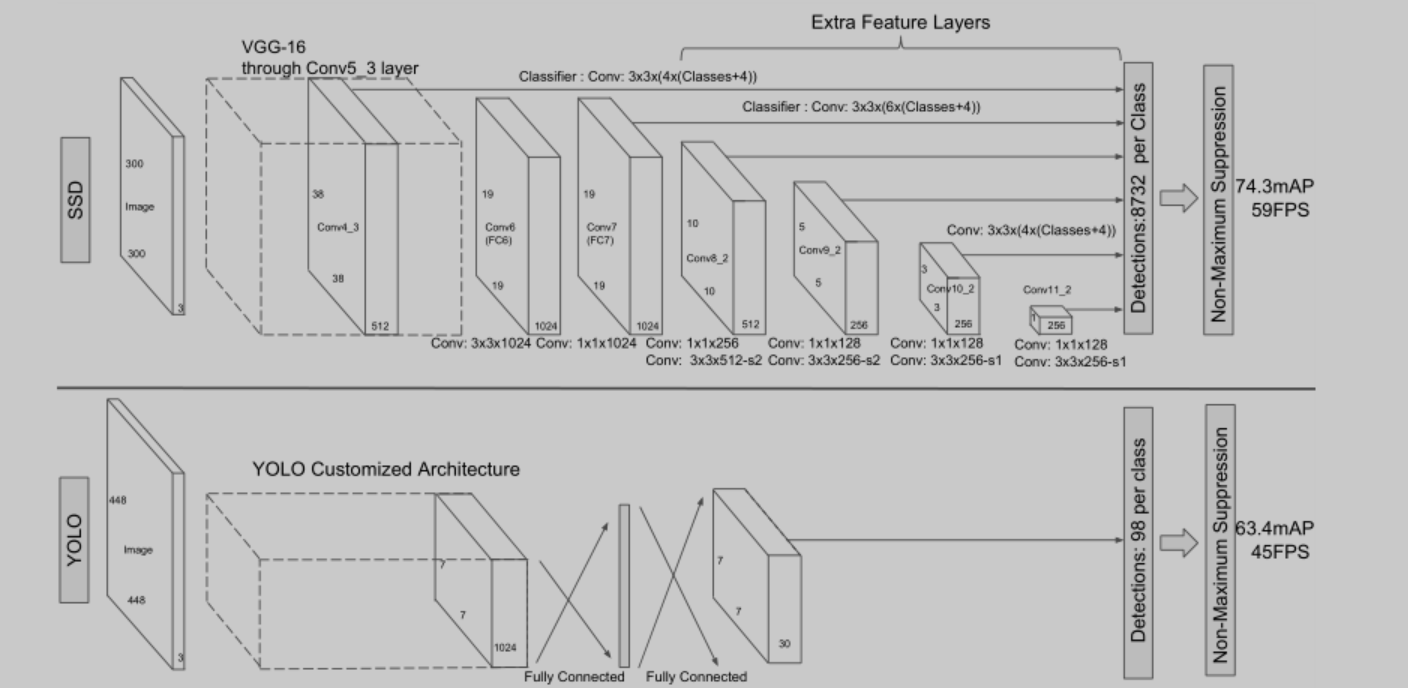

SSD网络最前边使用了VGG16的前5个层,使用Conv4_3做边框回归和分类;然后把VGG16的2个全连接层FC6、FC7改成了卷积层Conv6、Conv7,使用Conv7做边框回归和分类;之后自己添加了Conv8、Conv9、Conv10、Conv11,并选取其中的Conv8_2、Conv9_2、Conv10_2、Conv11_2做边框回归和分类。
通过分析SSD网络的结构,我们知道了SSD网络是在哪个特征图上做边框回归和分类,接着看下怎么在这些特征图上圈一个框出来。
2.Default Boxs
假设网络经过卷积,生成了8*8和4*4的feature map
在8*8和4*4的feature map上分割生成一些网格,这些网格称为feature map cell,如下图所示
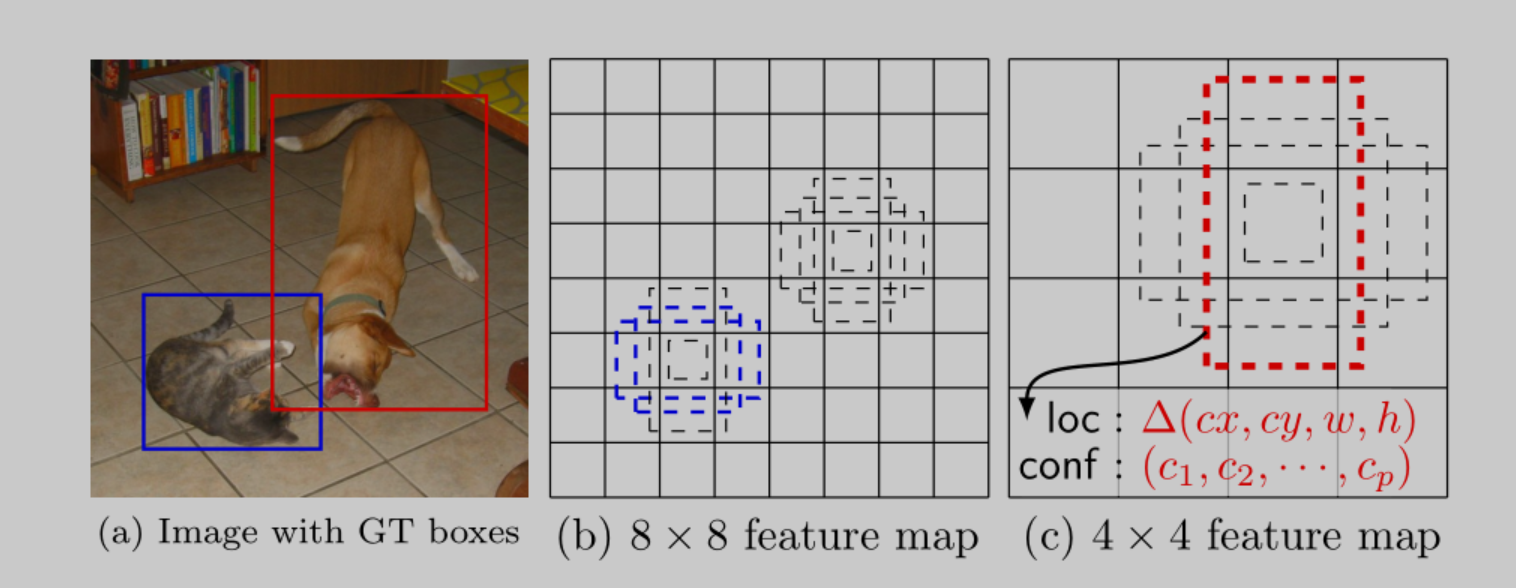
使用一个3*3卷积核在图像上滑动,每一个卷积核滑动的位置,生成一系列default box
由于网络前边的feature map尺寸较大(8*8),使用3*3的卷积核可以圈出小物体;网络后边的feature map尺寸较小(4*4),使用3*3的卷积核可以圈出大物体,这样就解决了在YOLO中容易漏掉小物体的问题(如果YOLO划分的网格中有2个小物体的中心都在同一个网格,那么YOLO只能检测出一个物体)
default box的大小用scale和aspect ratios表示,使用如下公式计算:
scale
$s_k = s_{min} + {s_{max}- s_{min} \over m -1}(k - 1) ,k \in [1,m]$
其中$s_{min} = 0.2,s_{max = 0.9}$
aspect ratios

$w_k^a表示的是盒子的宽,h_k^a表示盒子的长$
当aspect ratios为1时,scale为s`
3.特征向量生成
有了default box后就需要生成特征向量进行框回归和分类。
对于边框回归,只需要4维向量即可,分别代表边框缩放尺度(坐标轴两个方向)和平移向量(坐标轴两个方向)。对于分类,SSD网络采取为每个类别进行打分的策略,也就是说对于每个Default Box,SSD网络会计算出相应的每个类别的分数。假设数据集类别数为c,加上背景,那么总的类别数就是c+1类。SSD网络采用了c+1维向量来分别代表该Default Box对于每个类别所得到的分数。这里,假设是VOC数据集,那么每个Default Box将生成一个20 + 1 + 4 = 25维的特征向量。同样,以Conv9输出特征图5x5为例。
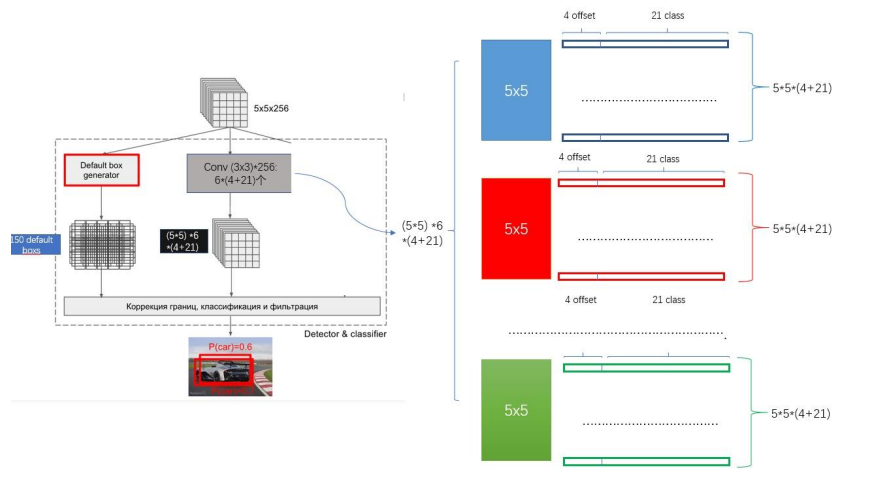
在5*5的特征图上使用1*1的卷积核滑动,即每个格子生成6个default box,一共5*5*6 = 150个default box
每个盒子要生成25个特征向量,最后会产生5*5*6*25 = 3750个输出
SSD源码中并不会使用所有的default box,而是在每张feature map中使用部分default box,源码中叫prior box
conv4_3(4),fc7(6),conv6_2(6),conv7_2(6),conv8_2(4),conv9_2(4)括号中的数字是每张feature map使用的prior box数
所以SSD300的prior box总数是38*38*4+19*19*6+10*10*6+5*5*6+3*3*4+1*1*4=8732
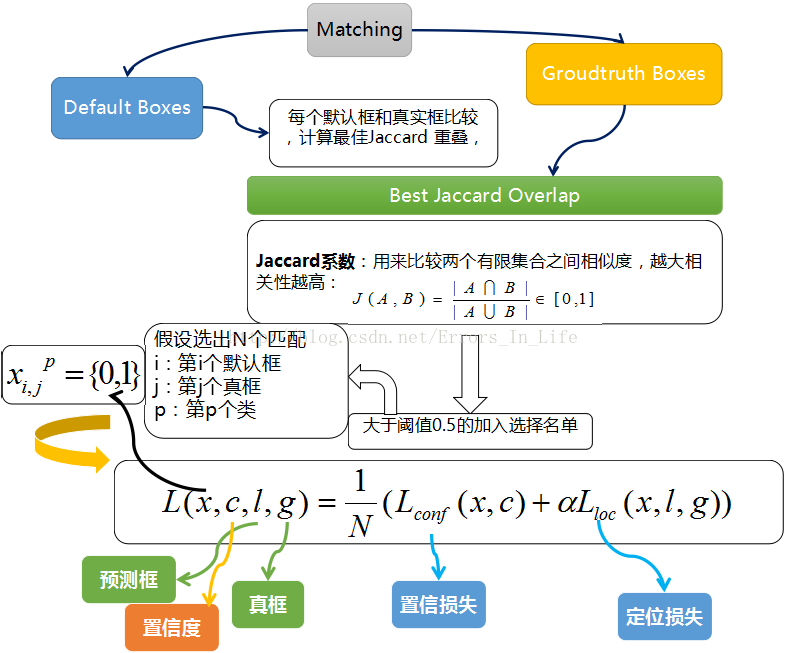
4.损失函数
这8732个prior box不会全部计算损失函数,而是通过计算Jaccard overlap计算和Groudtruth box重叠的比例,大于0.5的计算损失,损失的计算公式如下,具体的可以参考reference论文中的公式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号