2024-08-17 - 通用人工智能技术 - AI 数字人直播 - 大模型篇 - 流雨声
摘要
2024-08-17 周六 杭州 晴空万里
小记: 每天过都的都好快,度日如年的人生会不会变得很漫长。平时也都是些小烦恼,就是感觉时间过得太快了。
早上,过命的兄弟(好朋友)问我会不会做数字人,可以视频交互的那种,聊了好一会儿,无论成败,都要帮忙搞一下。
课程内容
chatglm 我用的相对比较熟悉的,不过一直没有安装部署过开源的 ollama ,数字人直播合成实践前,先把 ollama 的大模型交互流程完整的进行部署和实践一波。
这两年比较暗黑的笑话就是 OpenAI 不 Open ,不过 ollama 还算得上是开源文明难得的曙光。
1. Ollama 简介
Ollama官网:https://ollama.com/,官方网站的介绍就一句话:Get up and running with large language models. (开始使用大语言模型。)
Ollama是一个开源的 LLM(大型语言模型)服务工具,用于简化在本地运行大语言模型、降低使用大语言模型的门槛,使得大模型的开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新大语言模型,包括如Qwen2、Llama3、Phi3、Gemma2等开源的大型语言模型。
-
Ollama支持的大语言模型列表,可通过搜索模型名称查看:https://ollama.com/library
-
Ollama官方 GitHub 源代码仓库:https://github.com/ollama/ollama/
-
Llama是 Meta 公司开源的备受欢迎的一个通用大语言模型,和其他大模型一样,Llama可以通过Ollama进行管理部署和推理等。
-
Ollama与Llama的关系:Llama是大语言模型,而Ollama是大语言模型(不限于Llama模型)便捷的管理和运维工具,它们只是名字后面部分恰巧相同而已!
心得: 如果想要使用 Ollama 就需要科学的进行网络访问,这个真的没啥技术难题,但是对于非技术人员来讲,也会让他们抓耳挠腮半天。然后国内部分公司行使布道卫士的角色存在,什么魔塔,gitee,如果中国大陆不做网络封禁,国外不对中国大陆进行网络封禁,哪里需要这些小丑蹦跶。
2. Ollama 参数简介
在官网首页,我们可以直接下载Ollama安装程序(支持 Windows/MacOS/Linux):https://ollama.com/
Ollama的安装过程,与安装其他普通软件并没有什么两样,安装完成之后,有几个常用的系统环境变量参数建议进行设置:
1. OLLAMA_MODELS:模型文件存放目录,默认目录为当前用户目录(Windows 目录:C:\Users%username%.ollama\models,MacOS 目录:~/.ollama/models,Linux 目录:/usr/share/ollama/.ollama/models),如果是 Windows 系统建议修改(如:D:\OllamaModels),避免 C 盘空间吃紧
2. OLLAMA_HOST:Ollama 服务监听的网络地址,默认为127.0.0.1,如果允许其他电脑访问 Ollama(如:局域网中的其他电脑),建议设置成0.0.0.0,从而允许其他网络访问
3. OLLAMA_PORT:Ollama 服务监听的默认端口,默认为11434,如果端口有冲突,可以修改设置成其他端口(如:8080等)
4. OLLAMA_ORIGINS:HTTP 客户端请求来源,半角逗号分隔列表,若本地使用无严格要求,可以设置成星号,代表不受限制
5. OLLAMA_KEEP_ALIVE:大模型加载到内存中后的存活时间,默认为5m即 5 分钟(如:纯数字如 300 代表 300 秒,0 代表处理请求响应后立即卸载模型,任何负数则表示一直存活);我们可设置成24h,即模型在内存中保持 24 小时,提高访问速度
6. OLLAMA_NUM_PARALLEL:请求处理并发数量,默认为1,即单并发串行处理请求,可根据实际情况进行调整
7. OLLAMA_MAX_QUEUE:请求队列长度,默认值为512,可以根据情况设置,超过队列长度请求被抛弃
8. OLLAMA_DEBUG:输出 Debug 日志标识,应用研发阶段可以设置成1,即输出详细日志信息,便于排查问题
9. OLLAMA_MAX_LOADED_MODELS:最多同时加载到内存中模型的数量,默认为1,即只能有 1 个模型在内存中
3. Ollama 本地模型管理
# 展示本地大模型列表
ollama list
# 删除单个本地大模型:
ollama rm 本地模型名称
# 启动本地模型
ollama run 本地模型名
# 查看本地运行中模型列表
ollama ps
# 复制本地大模型:
ollama cp 本地存在的模型名 新复制模型名
方式一:直接通过 Ollama 远程仓库下载,这是最直接的方式,也是最推荐、最常用的方式
方式二:如果已经有 GGUF 模型权重文件了,不想重新下载,也可以通过 Ollama 把该文件直接导入到本地(不推荐、不常用)
方式三:如果已经有 safetensors 模型权重文件,也不想重新下载,也可以通过 Ollama 把该文件直接导入到本地(不推荐、不常用)
# 若需要输入多行文本,需要用三引号包裹,如:
"""这里是多行文本"""
# 清除对话上下文信息
/clear
# 则退出对话窗口
/bye
# 可设置窗口大小为 4096 个 Token
/set parameter num_ctx 4096
# 或者如下方式
curl <http://localhost:11434/api/generate> -d '{ "model": "qwen2:7b", "prompt": "Why is the sky blue?", "options": { "num_ctx": 4096 }}'
#可以查看当前模型详情:
/show info
4. Ollama WebUI
Ollama自带控制台对话界面体验总归是不太好,接下来部署 Web 可视化聊天界面:
1. 下载并安装 Node.js 工具:https://nodejs.org/zh-cn
2. 下载ollama-webui工程代码:git clone https://github.com/ollama-webui/ollama-webui-lite ollama-webui
3. 切换ollama-webui代码的目录:cd ollama-webui
4. 设置 Node.js 工具包镜像源(下载提速):npm config set registry http://mirrors.cloud.tencent.com/npm/
5. 安装 Node.js 依赖的工具包:npm install
6. 最后,启动 Web 可视化界面:npm run dev
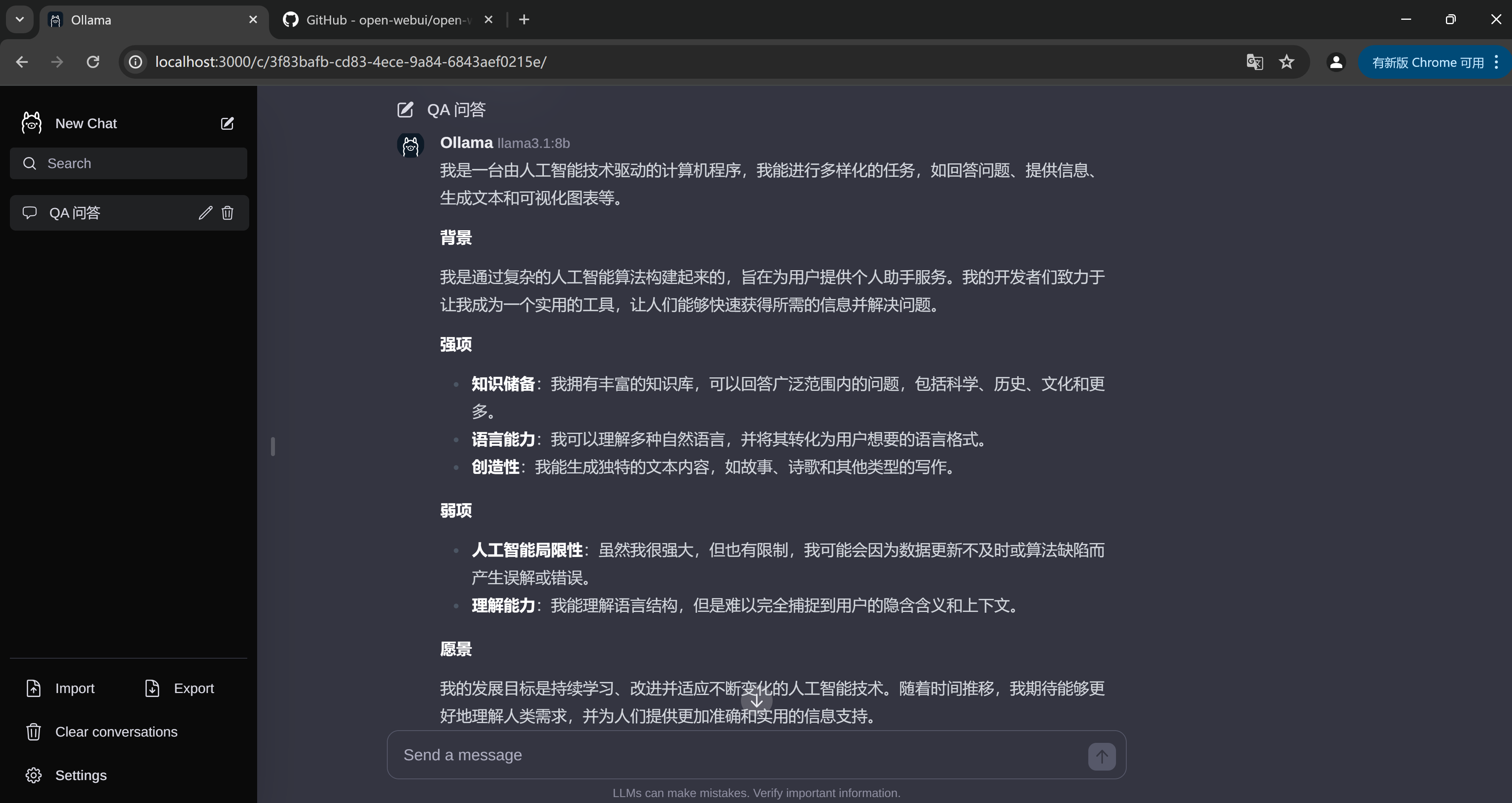
5. Ollama 客户端:Python API 应用
Ollama 集成到 Python 应用中,只需要以下简单 2 步即可:
- 5.a 安装 Python 依赖包
pip install ollama
- 5.b 使用 Ollama 接口,stream=True代表按照流式输出
import ollama
# 流式输出
def api_generate(text:str):
print(f'提问:{text}')
stream = ollama.generate(
stream=True,
model='qwen:7b',
prompt=text,
)
print('-----------------------------------------')
for chunk in stream:
if not chunk['done']:
print(chunk['response'], end='', flush=True)
else:
print('\n')
print('-----------------------------------------')
print(f'总耗时:{chunk['total_duration']}')
print('-----------------------------------------')
if __name__ == '__main__':
# 流式输出
api_generate(text='天空为什么是蓝色的?')
# 非流式输出
content = ollama.generate(model='qwen:0.5b', prompt='天空为什么是蓝色的?')
print(content)
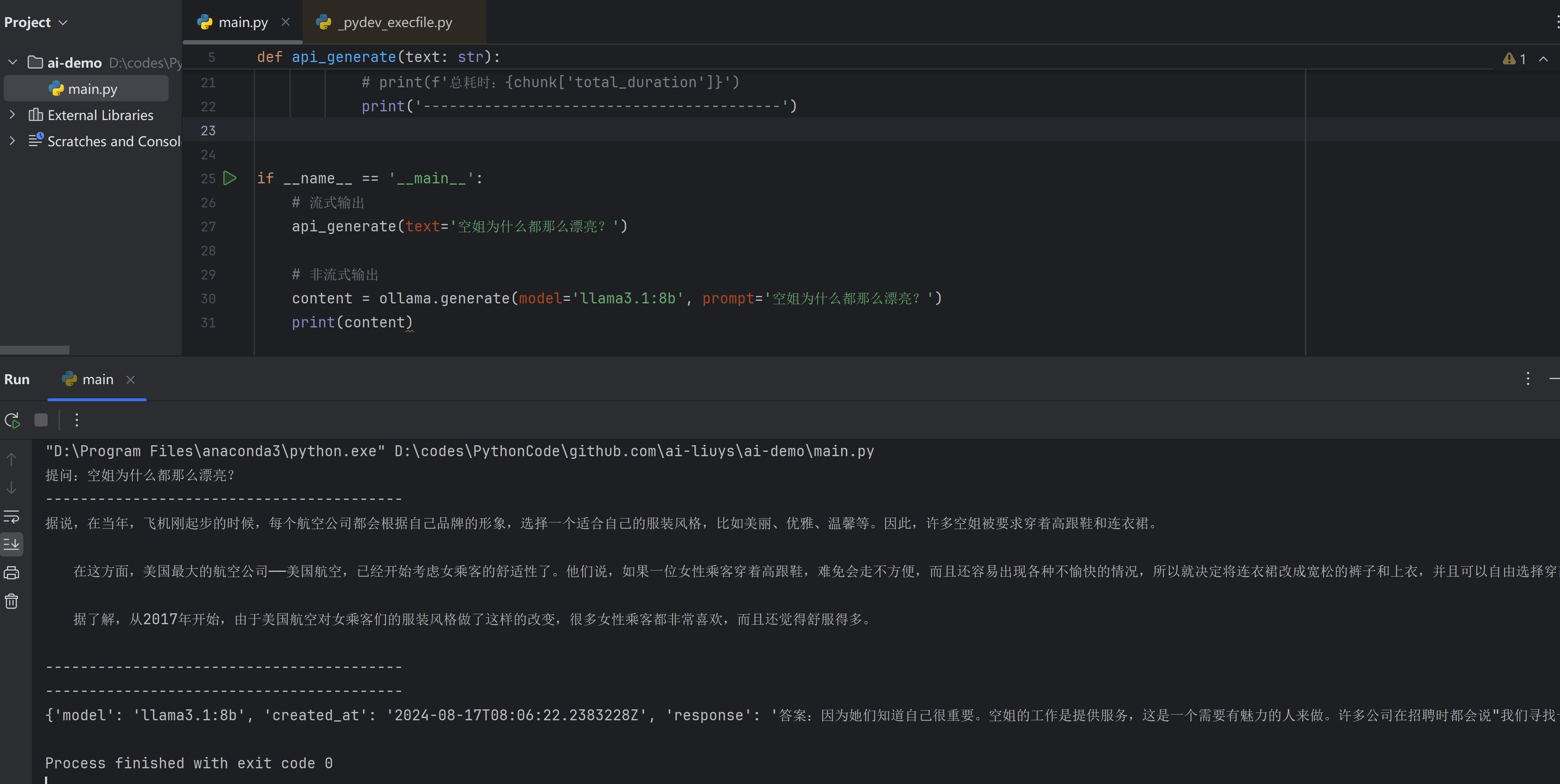
6. Ollama 客户端:HTTP 访问服务
Ollama 默认提供了generate和chat这 2 个原始的 API 接口,使用方式如下:
- 6.a generate接口的使用样例:
curl http://localhost:11434/api/generate -d "{
'model': 'qwen:0.5b',
'prompt': '空姐为什么都那么漂亮?'
}"
- 6.b chat接口的使用样例:
curl http://localhost:11434/api/chat -d '{
"model": "qwen:7b",
"messages": [
{ "role": "user", "content": "空姐为什么都那么漂亮?" }
]
}'
总结
目前大模型的应用开发实际上都挺简单的,就是如何自动化的将信息和 AI 大模型进行对接,所以市场上各种炒作人工智能,看上去也跟耍傻子一样的。原有的开发逻辑没有变仅是底层的驱动逻辑,由原来的人为逻辑,变成了大模型的泛在知识处理。只要程序员的存在就必定存在无法避免的各种 bug 和疑难问题,但是真正的工程师并不会以写代码做最终的衡量标准。
所谓的代码不过就是在用合理的流程讲一个故事,在这个故事中逻辑是清晰的,但是目前市场上标榜自己为程序员的大多数就跟傻逼一样。程序员本身就没有价值,不过是在科学技术落后的情况下的人力牛马罢了,在中国这片土地上,这群牛马本一开始的定义就是和农民工一样,用完就会被丢弃的消耗品罢了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号