2024-02-06 - 目标检测新范式Glip模型 - 卢菁
摘要
2024-02-05 周一 桑梓地 阴
小记: 多模态大模型搞的脑子有点炸呀!!!
课程内容
1. 基础常识
- Transformers 在视觉领域中的应用

- 模型 detr
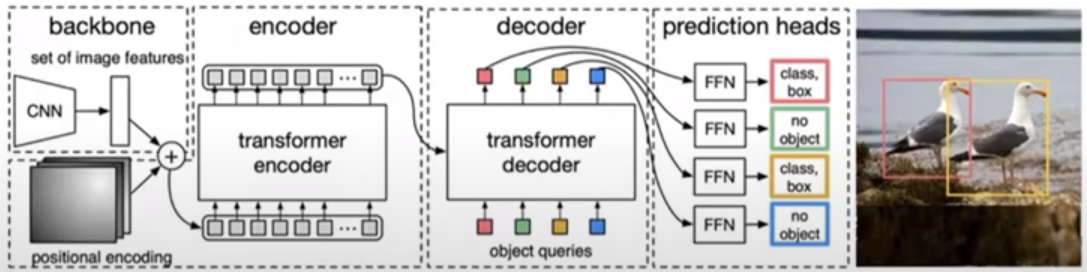
- 目标检测
目标: 目标检测
优点: zero-shot,目标检测的类就可以不在训练样本中出现;
yolos和detr共同的缺点: 模型训练一定要事先知道所有的类别。
- 模型出发点
对于对于一个图片和一段图片匹配的文字,找到文字当中指定的短语所对应的图片当中的检测框。对应到了一种短语和图片当中的细粒度匹配关系。
关键点: 图片上的内容和文本上的内容是可以对应起来的。

- 通过匹配的方式可以进行 0 样本学习

- 损失函数 v1.0
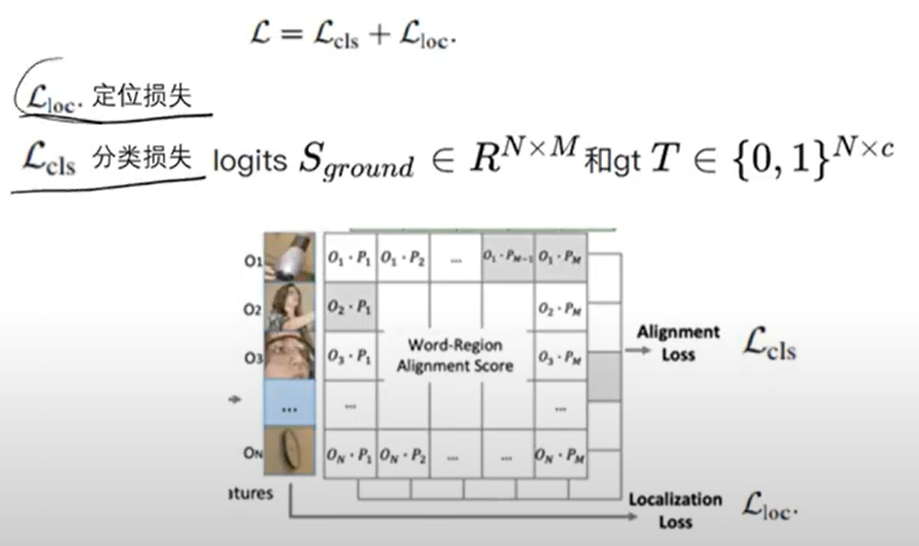
- 损失函数 v2.0



2. 小结
- CNN 架构: 经典目标检测 yolov1-yolov5
- Transformers 架构: yolos,detr 容易和 nlp 结合
问题: 但是上述两种均存在无法检测,训练集中没有出现的类别,因为没有理解类别的语义,只是把类别当作 one-hot 处理;
- Glip
a. 使用 Transformer 架构(clip 提取特征)
b. 视觉和文本信息交互 Fusion
克服上述两种方法的缺点,把分类问题转变为匹配问题,理解类别的语义,进行匹配。
总结
心得: 什么是多模态,就是文本和图片识别进行了深度融合,对于高等智慧体的理解或许不用拟人化,他们可以感知和识别,但不用人类一样需要眼睛或者耳朵。
后会无期,未来可期!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号