2024-02-04-大模型微调实战之GPU原理详解 -卢菁
摘要
2024-02-04 周日 老家 阴
小记: 继续学习机器学习相关的知识
课程内容
1. 数据的位宽

- 32bit float 可以作为弱基线;
- 对于训练使用 FP16,BF16,TF32;
- 推理 CV 任务以 int8 为主,NLP 以 FP16 为主,大模型 int8/FP16混合;
2. 计算分解

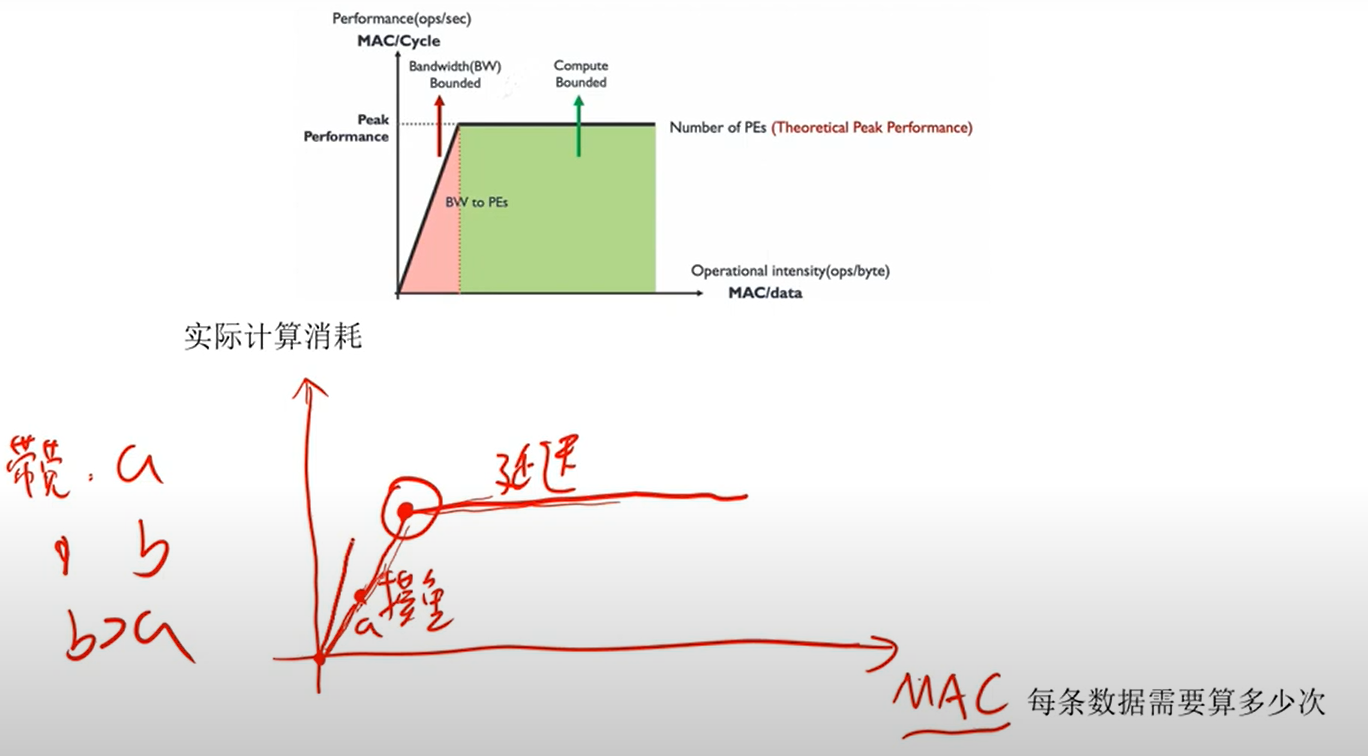
3. 数据计算强度
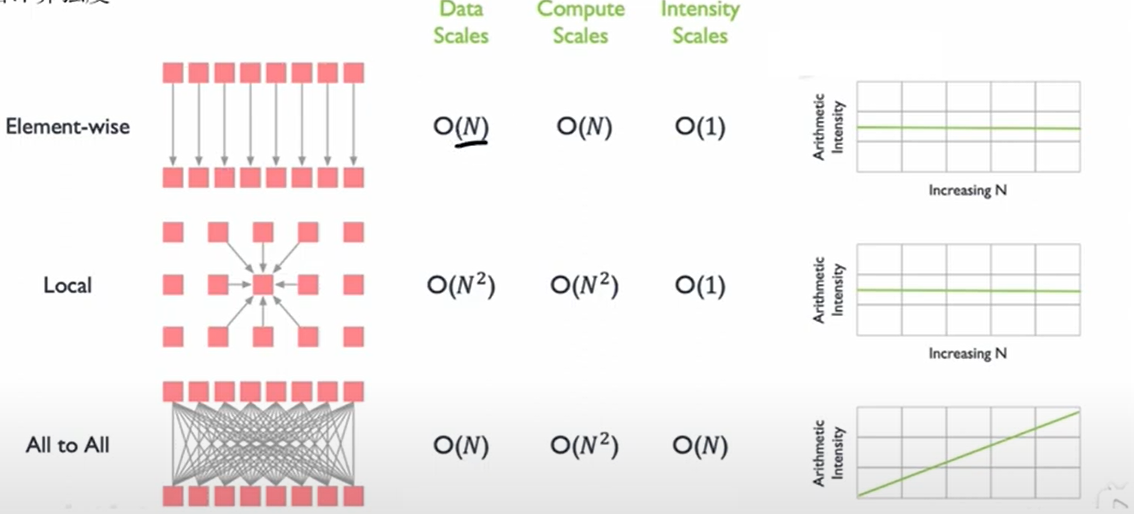
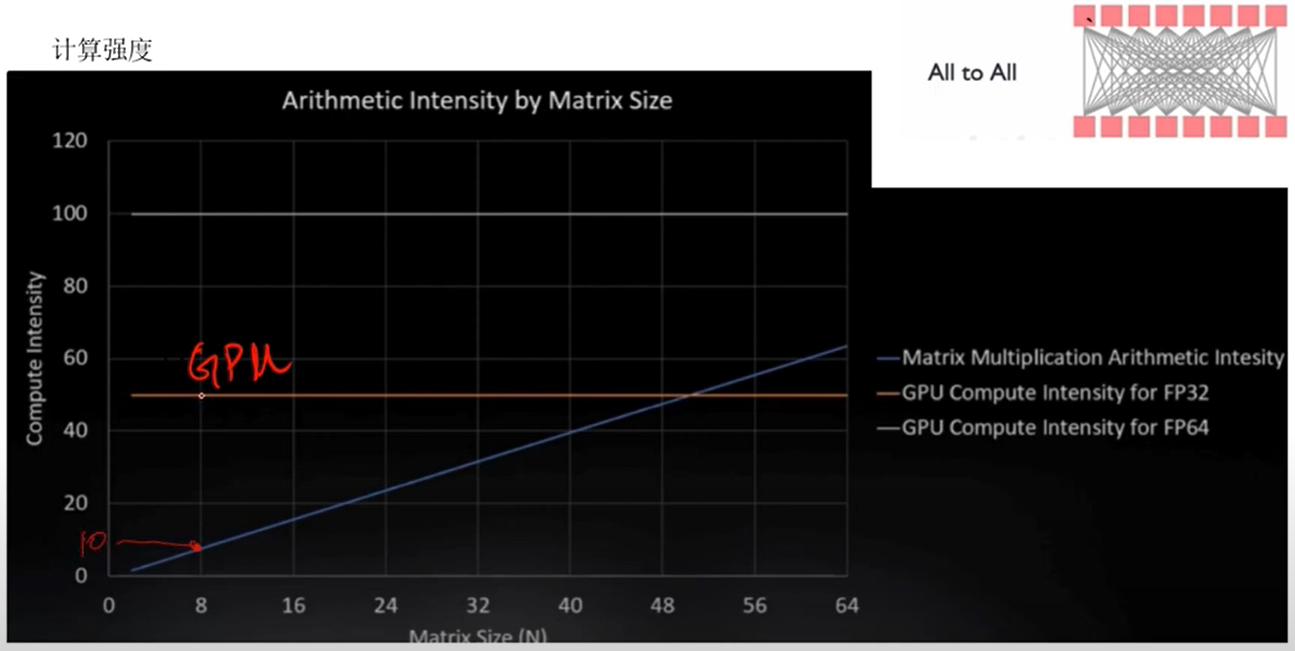
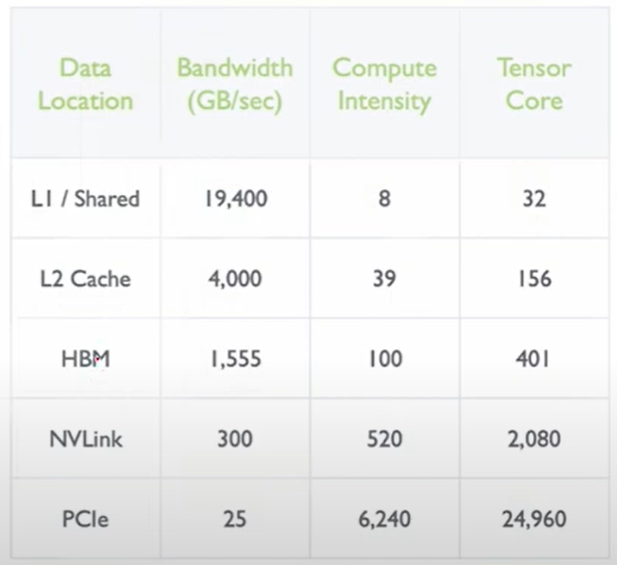
4. 计算强度
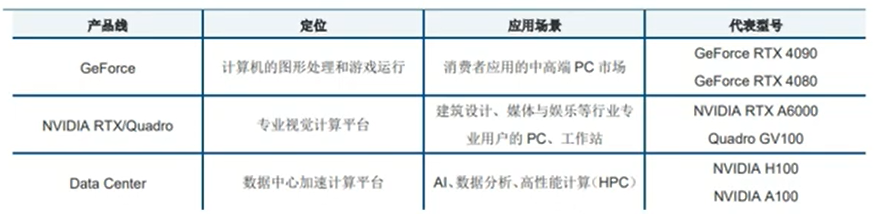
5. 英伟达主要产品线


6. 大模型计算量计算方法
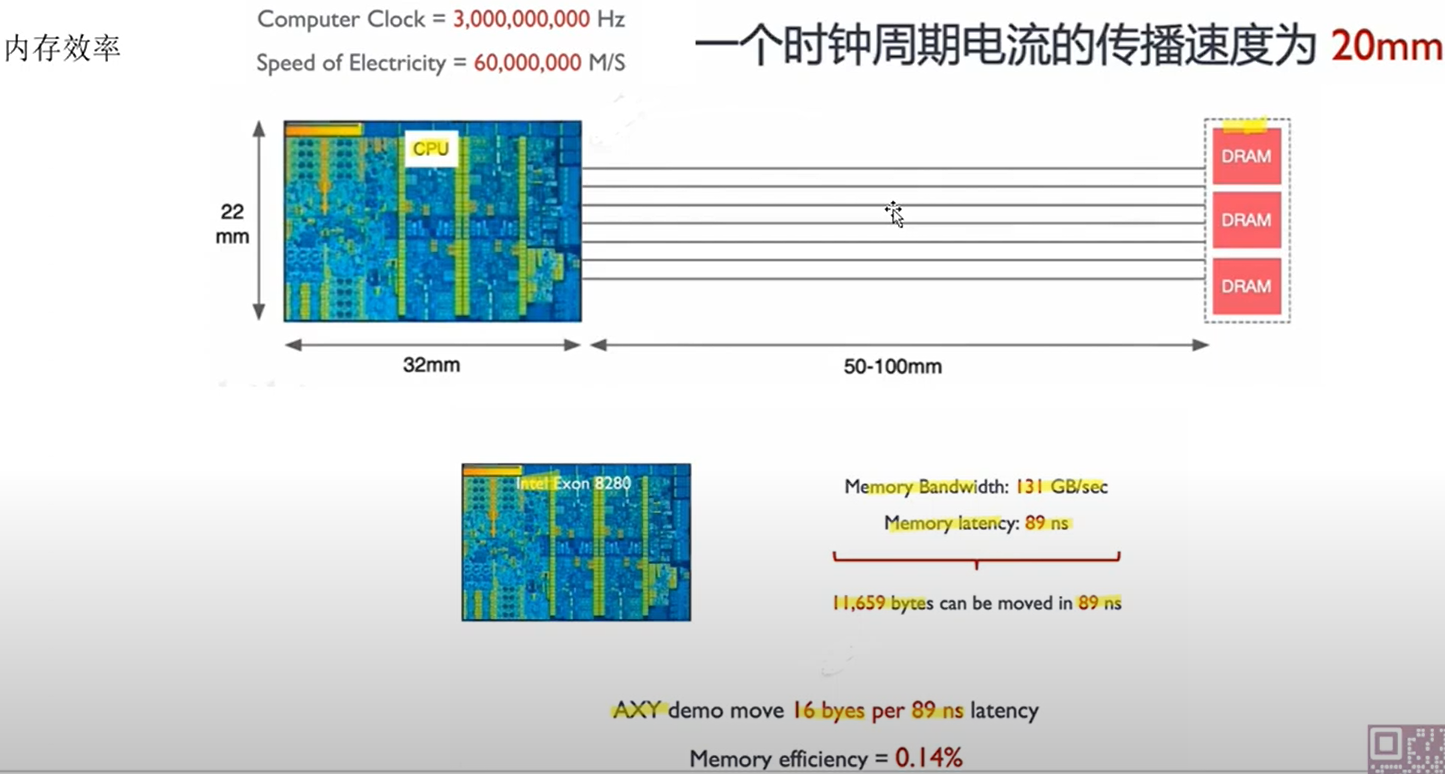
7. GPU 计算过程
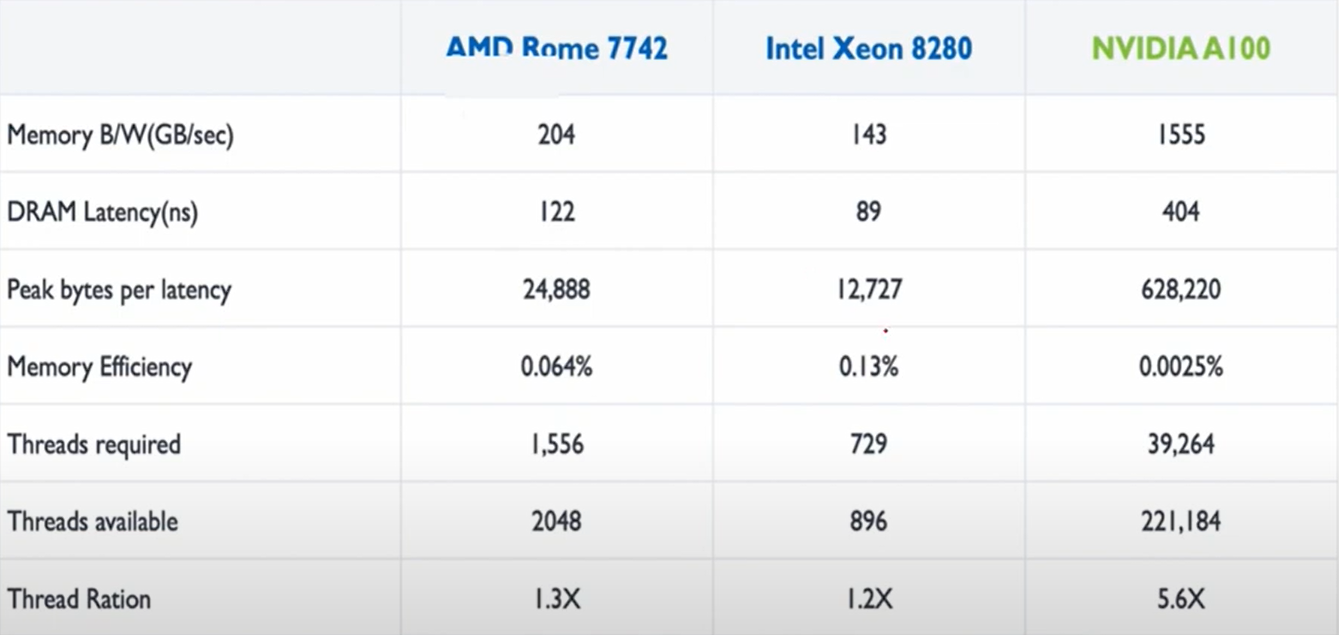
关键点: CPU 通过降低延迟加快速度,GPU 是提高并发内存占用提高速度。
8. CPU 与 GPU 的区别
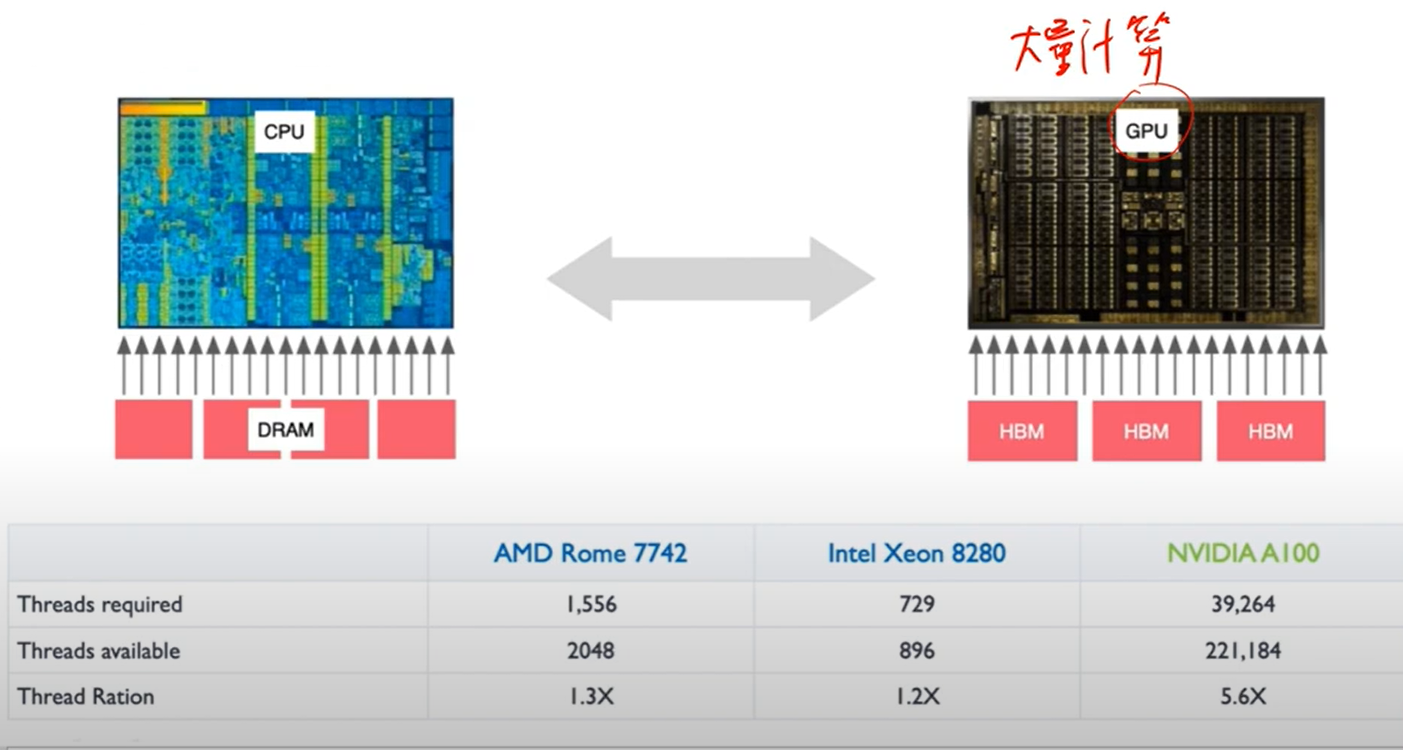
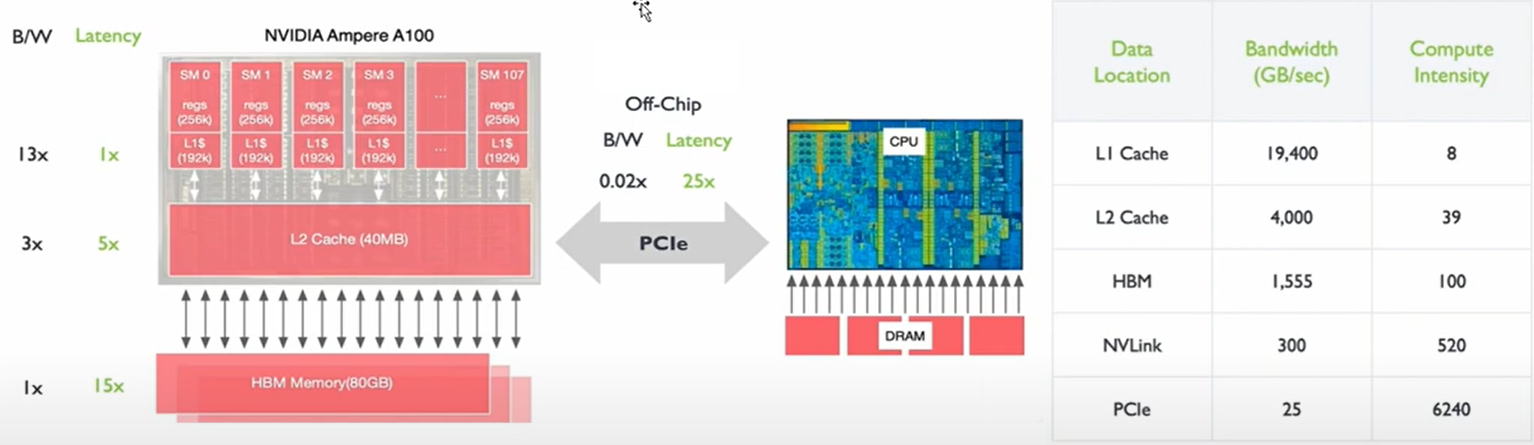
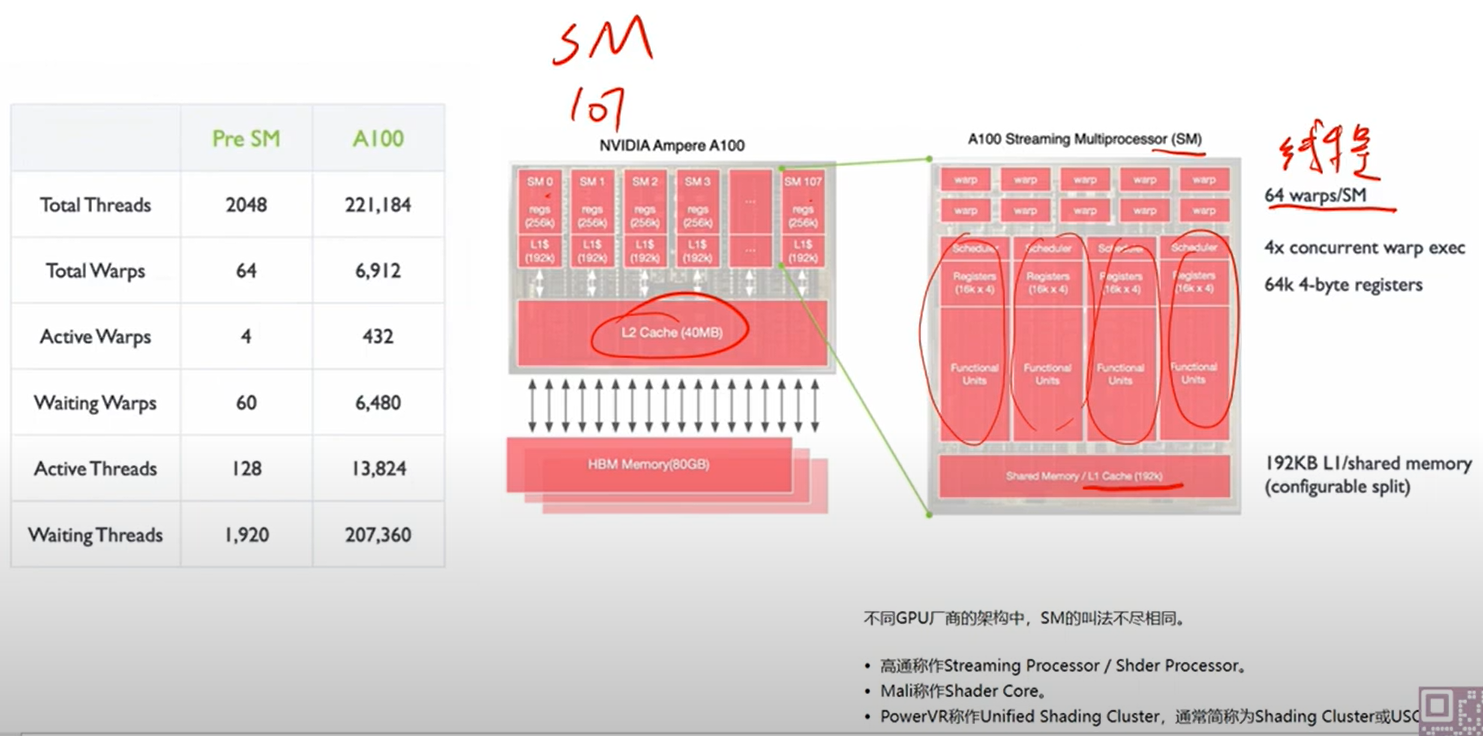
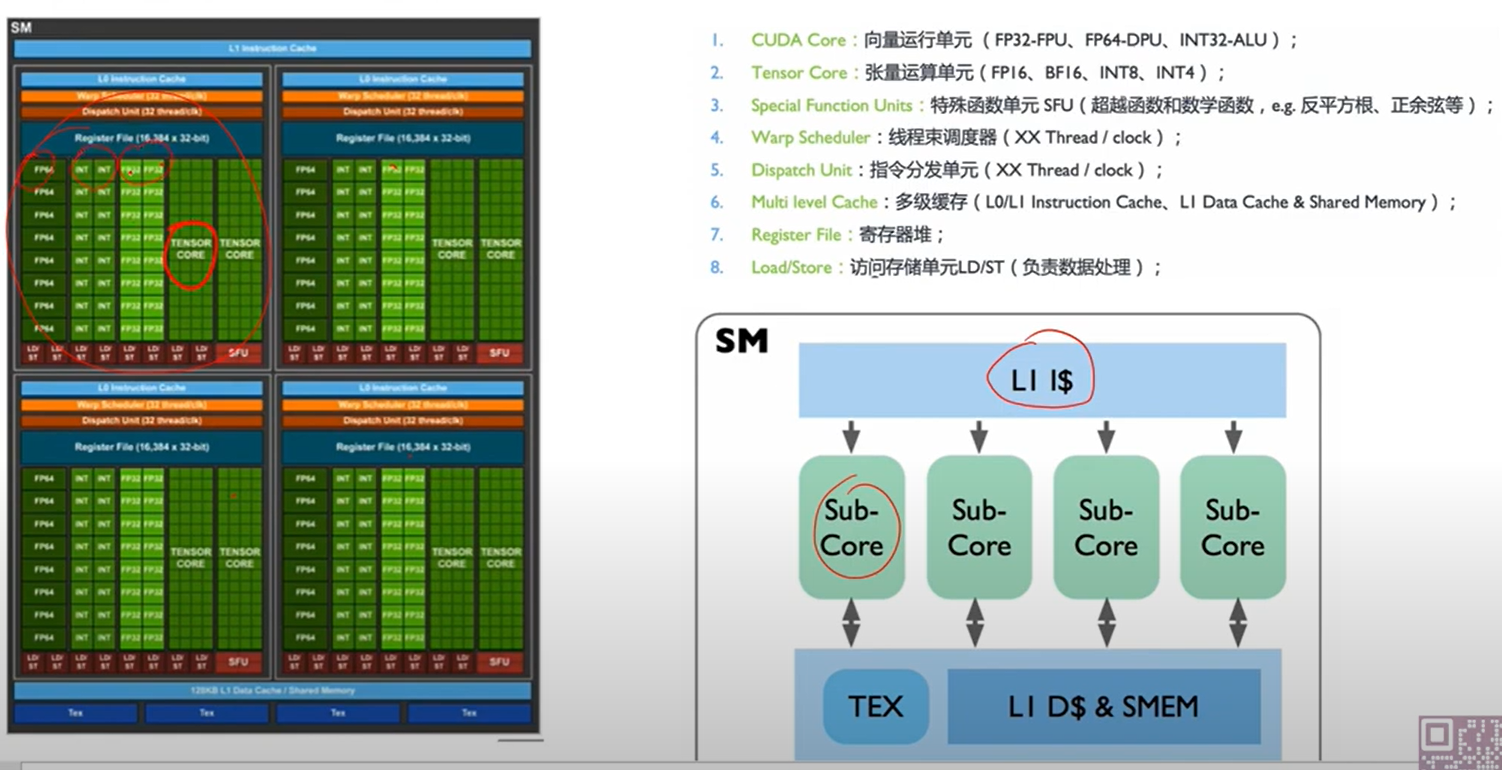
9. GPU 的核心架构(A100 为例)
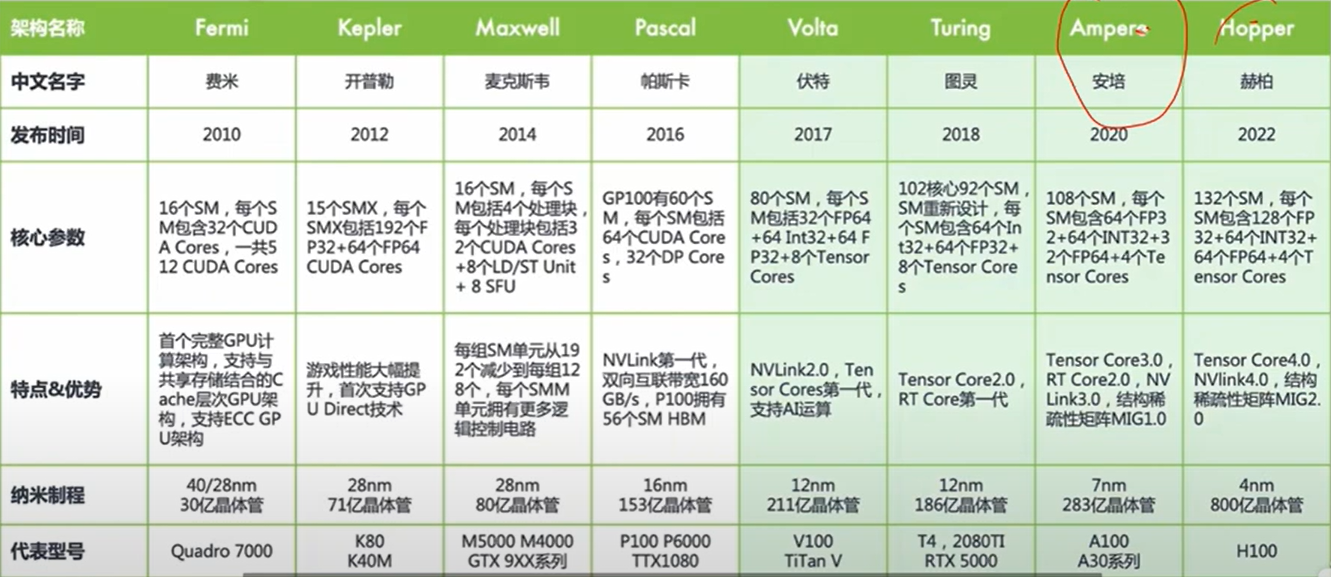
10. 英伟达历代产品参数



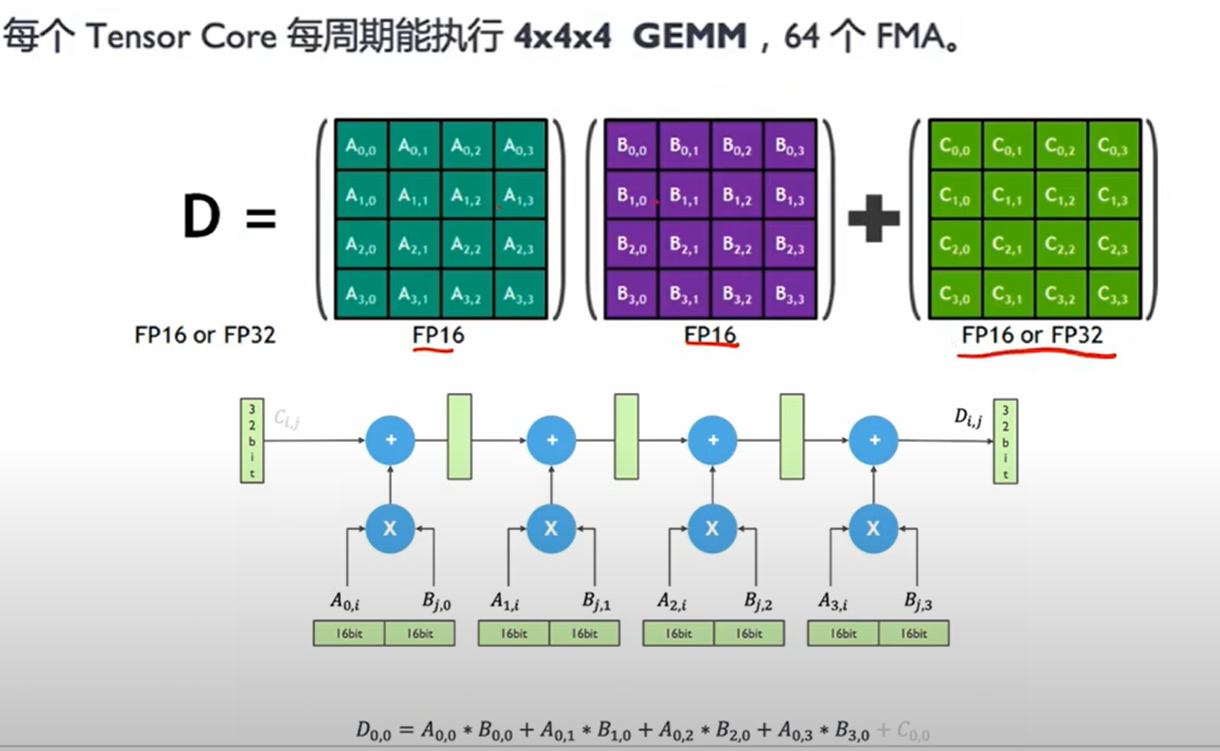
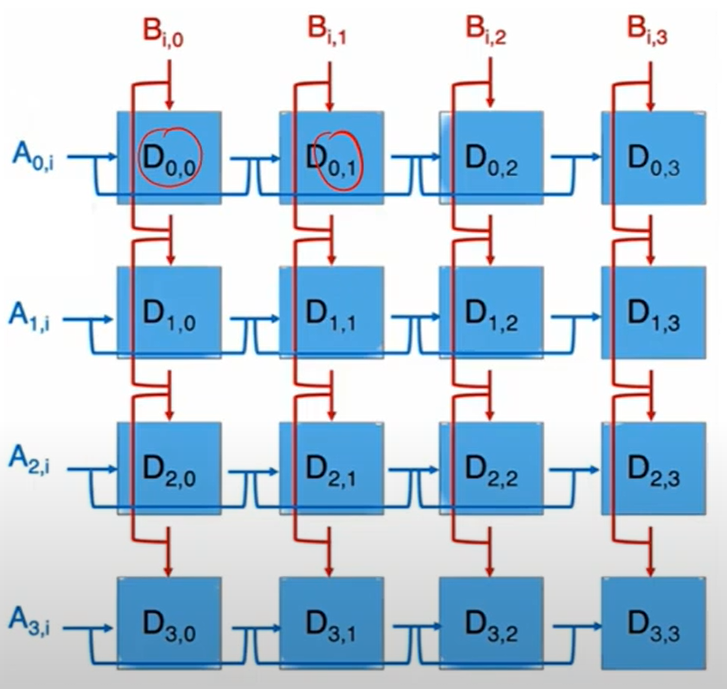
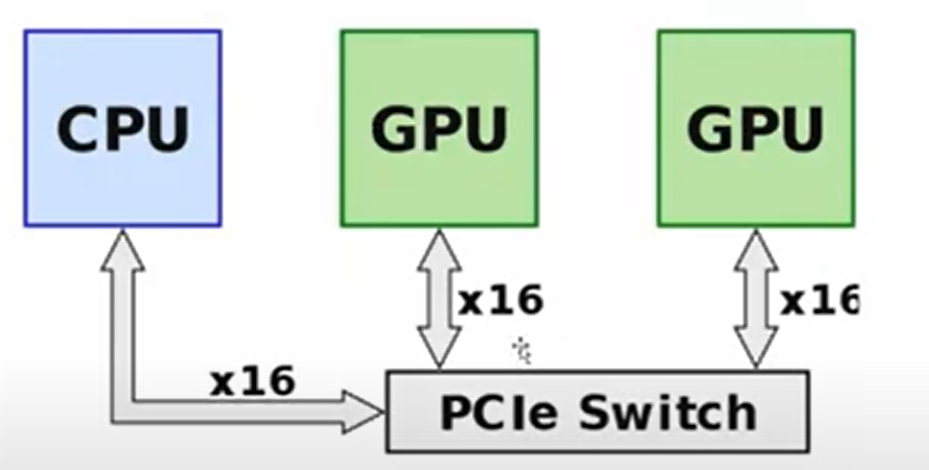
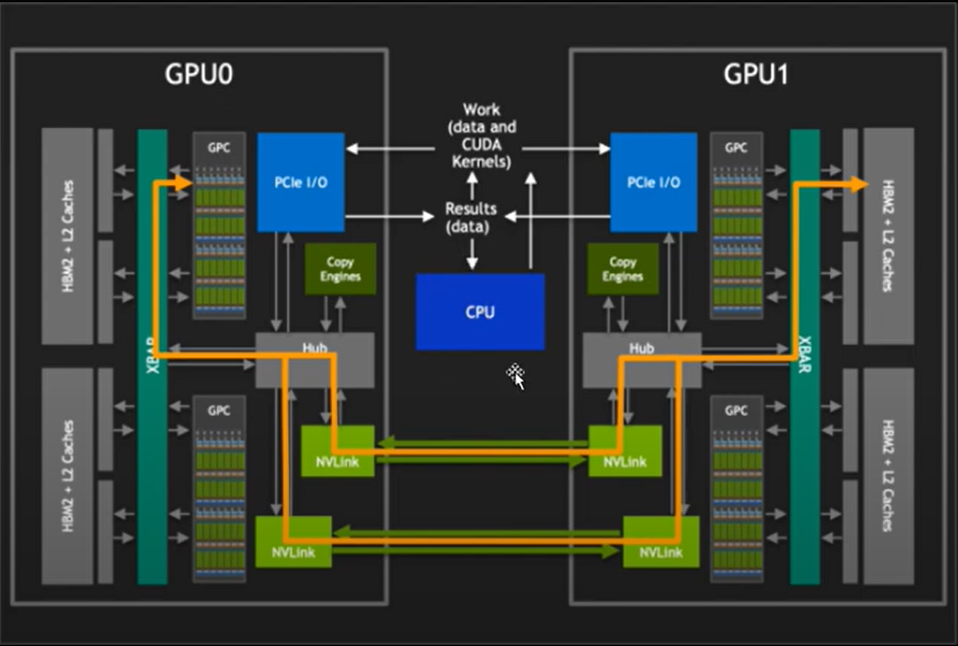
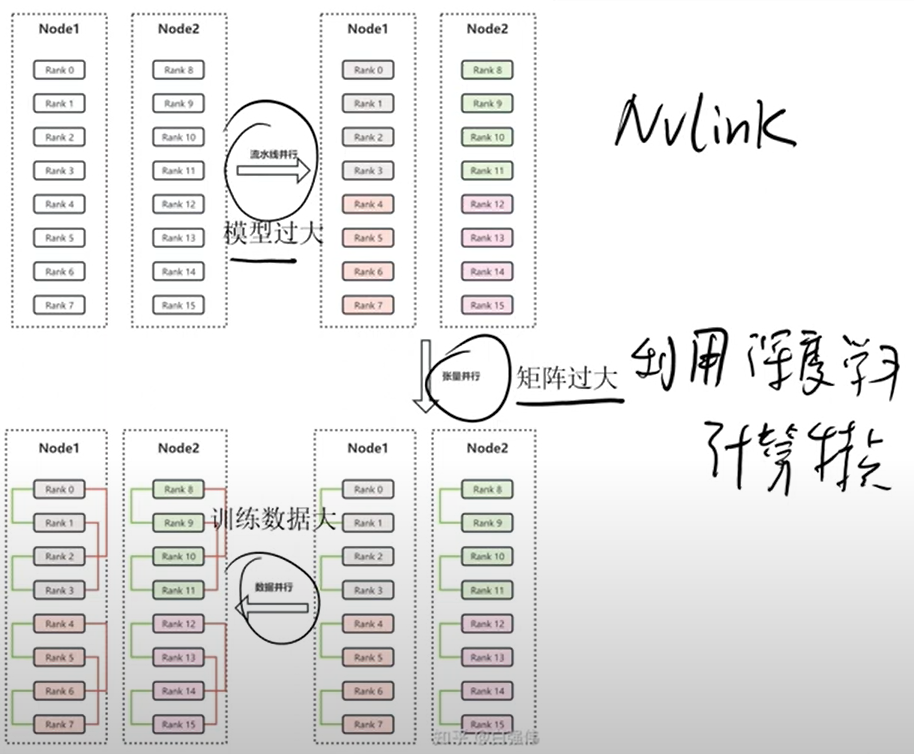
11. Nvlink: GPU 通信原理
-
PCie
-
Nvlink
-
硬件通信原理
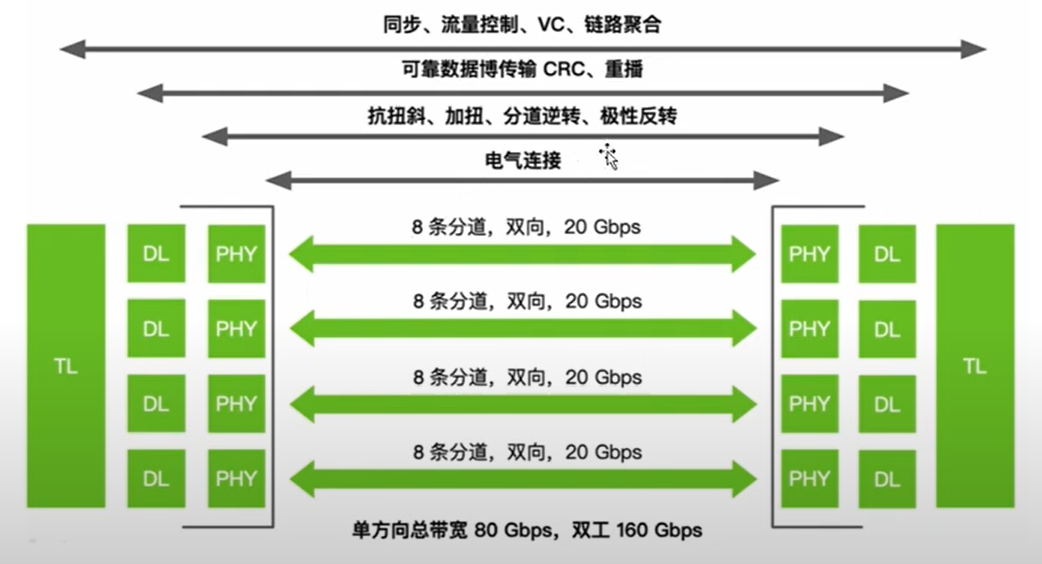
-
第一代 Nvlink
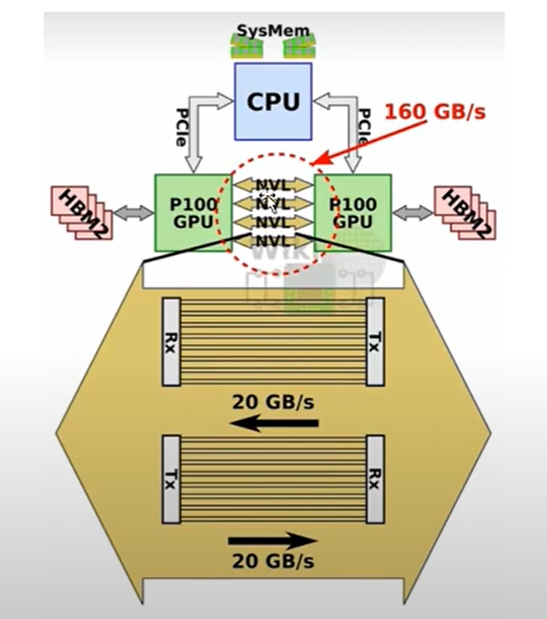
-
Nvlink 发展
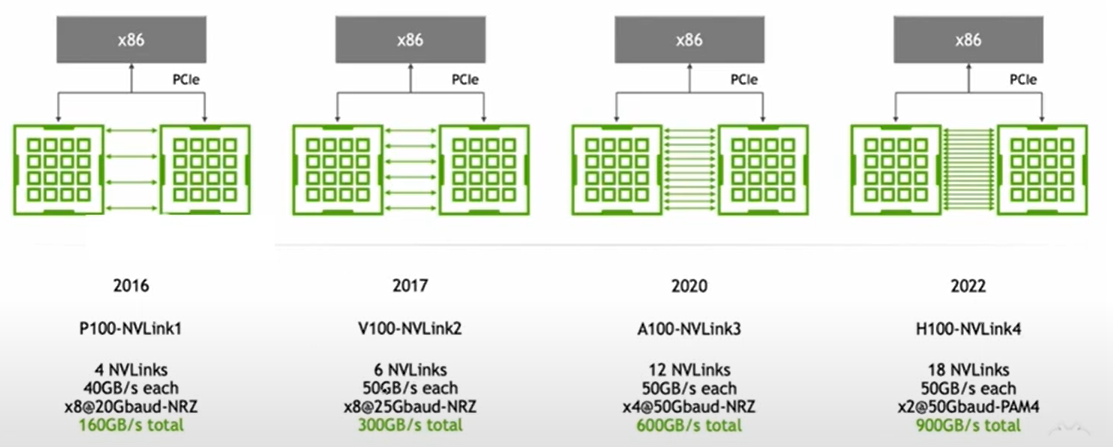
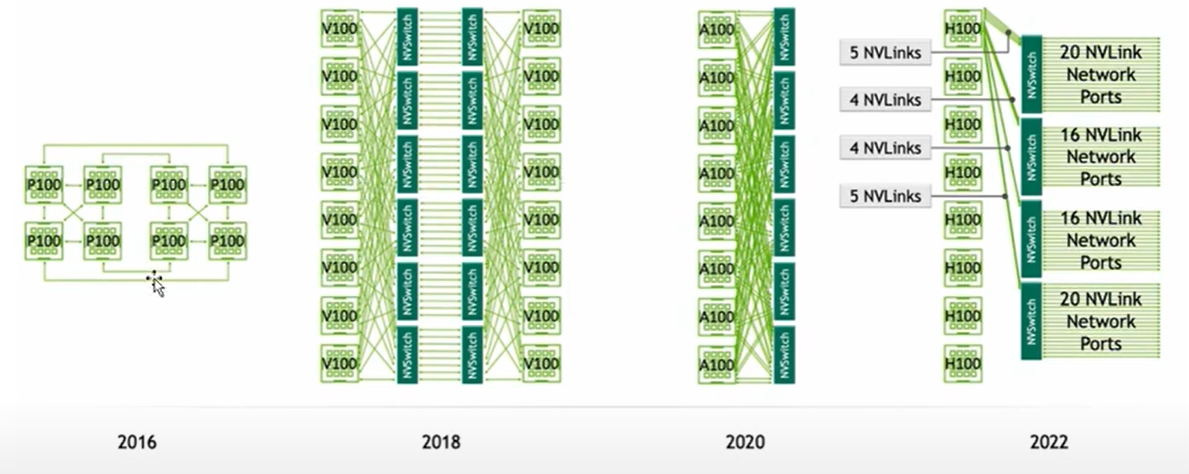
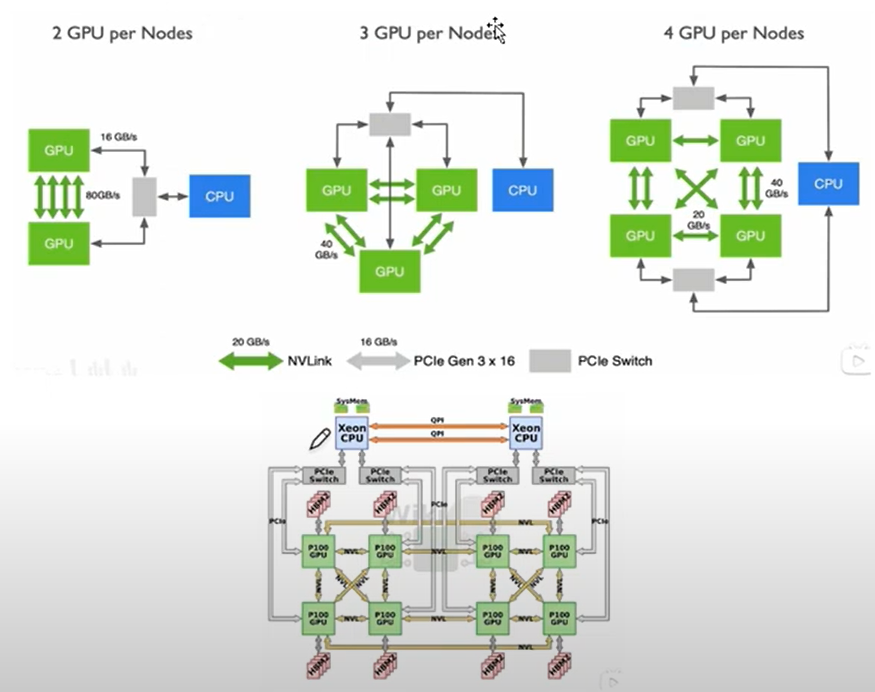
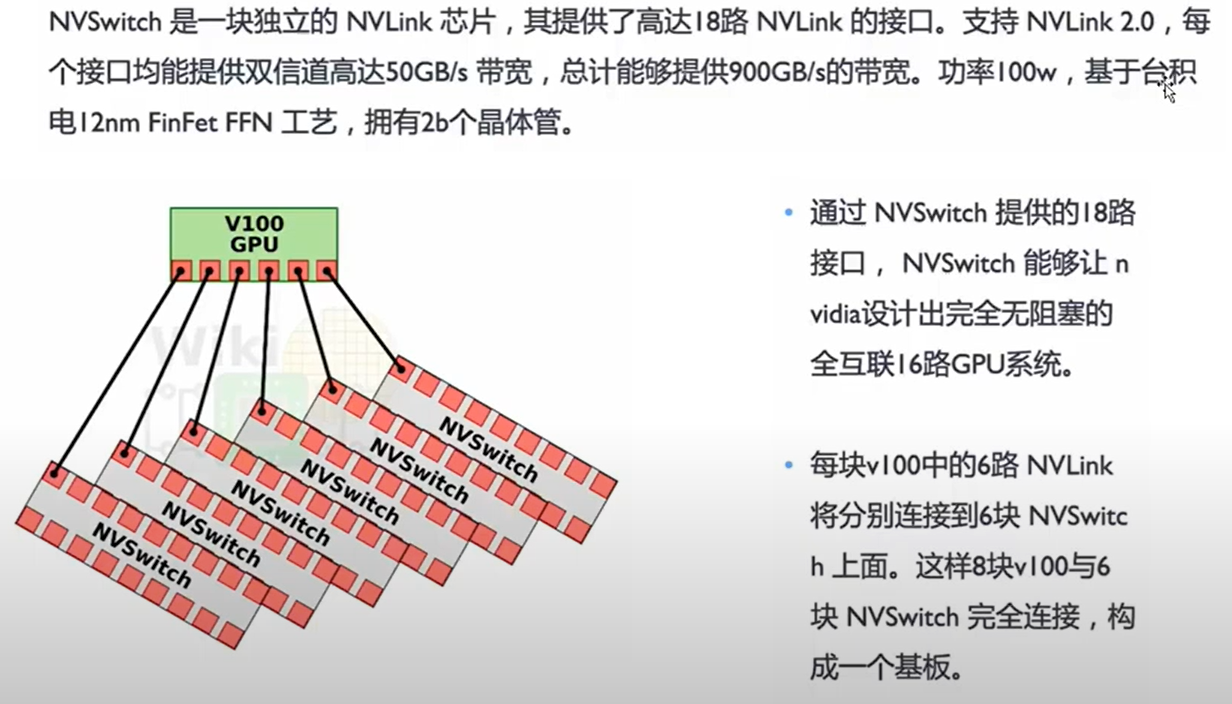
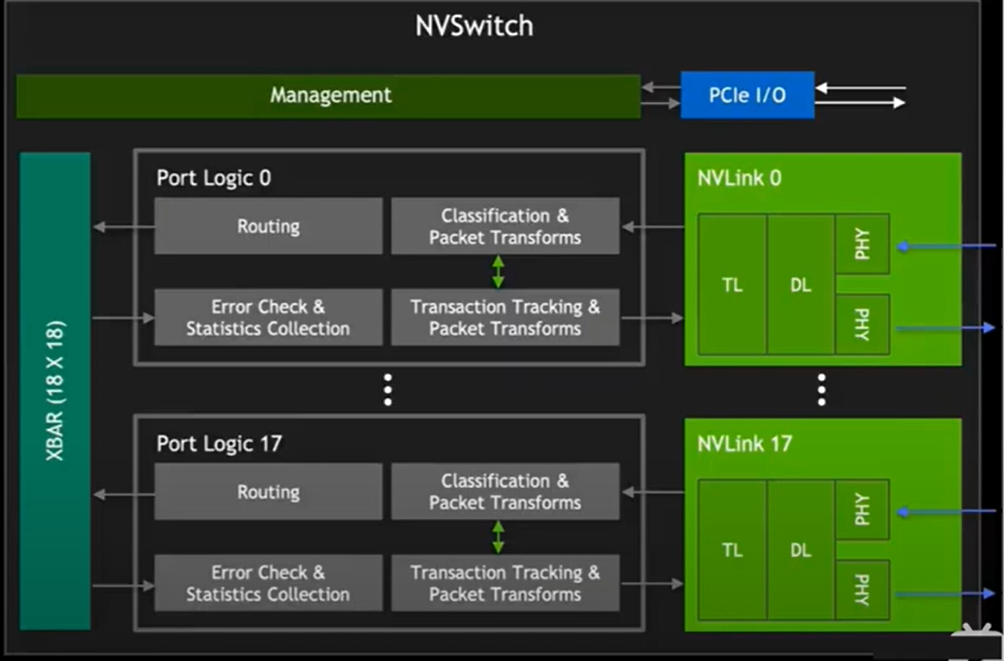
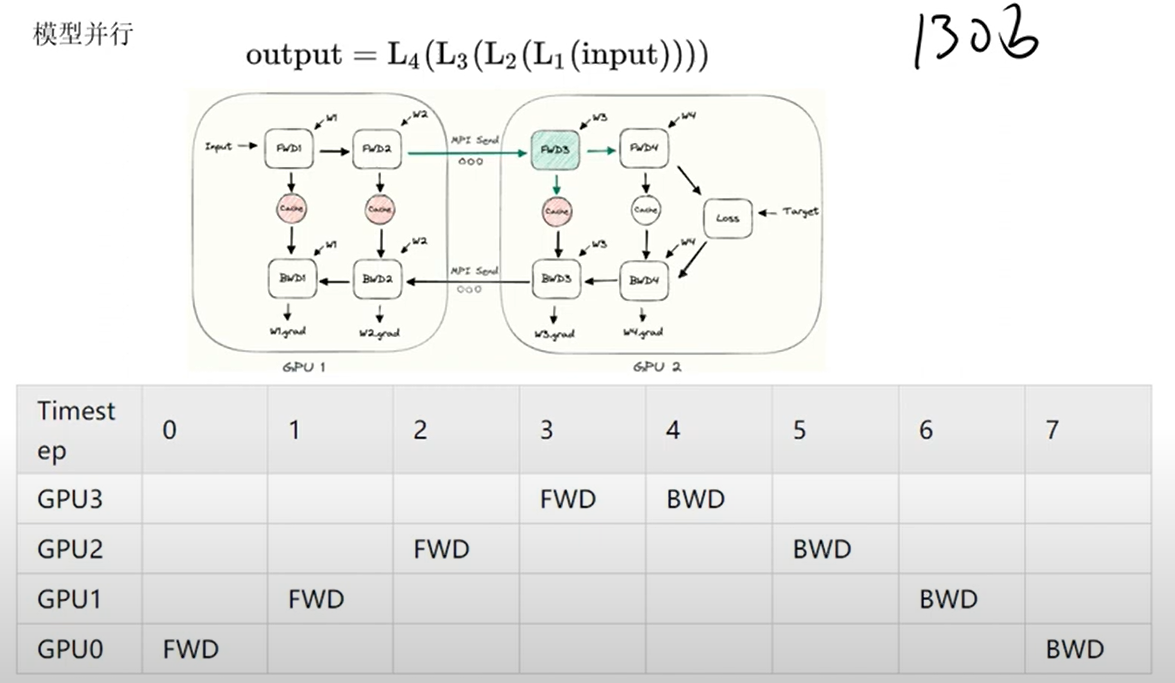
- GPU 的并行计算
Nvlink 大模型:
a. 大模型本身大,单核gpu 装不下
b. 数据多,单个 gpu 算不完
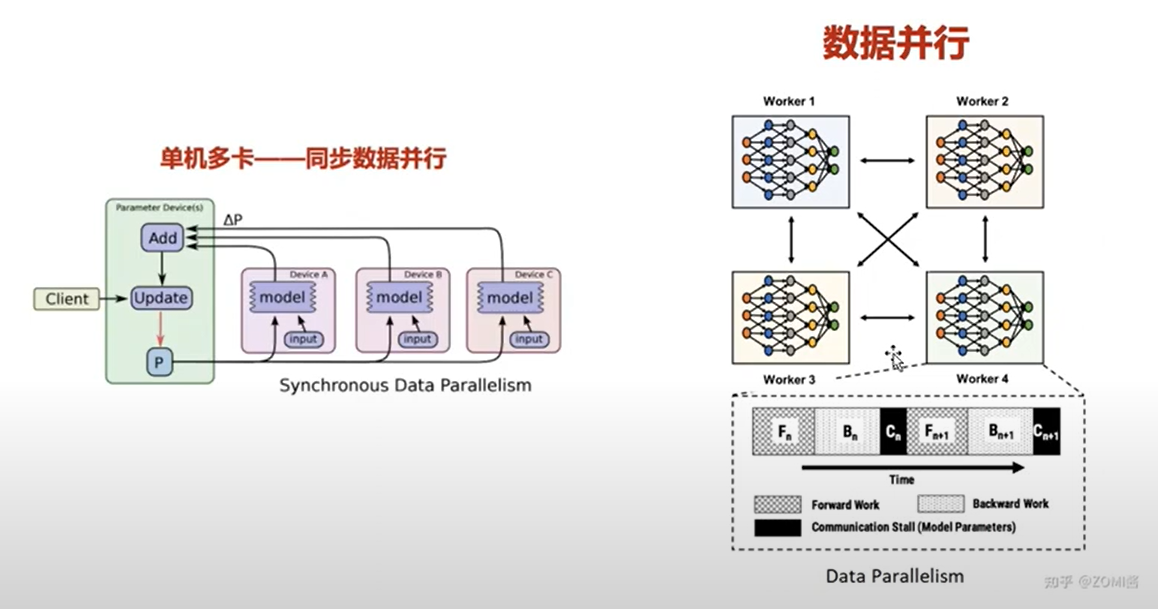
关键点: 单机目前最多支持 8 张卡;
- 大模型核心总结
a. 算法: 大部分开源,没有什么神秘的
b. 数据: 苦活
c. 算力: 花钱
总结
心得: GPU 这个水真的很深,大模型应用无非三个方面,算法难,但是开源;数据多,但是太杂乱;算力好,但是要花钱。
后会无期,未来可期!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号