
2024-01-06-AI 大模型全栈工程师 - Fine-tuning 集中答疑
摘要
2024-01-06 周六 杭州 晴
课程内容
1. GPU 利用率
a. GPU 利用率较低的原因本质是由于CPU的计算或者I/O环节耗时过长,导致GPU利用率较低;
b. 数据加载与处理的耗时,采用多线程或者 I/O 多路复用技术提高 I/O 或 CPU 利用率;
c. 减少 I/O 操作的耗时
c.1 模型保存不宜太频繁
c.2 日志/性能指标采集不宜太频繁
c.3 使用高性能存储介质
c.4 数据不宜使用小数据块,会影响 I/O
c.5 分布式训练时要使用多线程和并行技术
c.6 多机训练要使用 GDRDMA 技术
d. 其他 CPU 耗时
d.1 主要是损失函数和 metrici 计算的复杂度
2. Batch 的拼接方式(PADDING 在哪边)
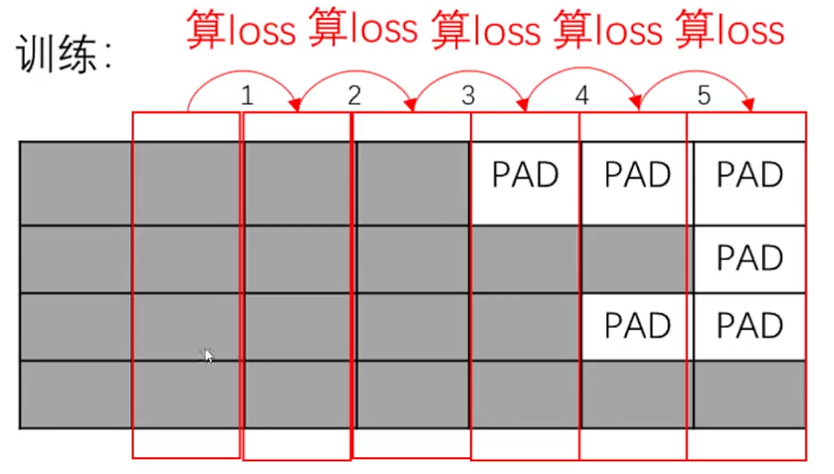
3. Tokenizer 怎么分词,怎么处理未登录时间
a. 双字节对(BPE)编码: 高频二元组合并,低频的分开,迭代至不能合并为止,ChatGpt 用的就是这个方法;
b. 基于与监督学习的 Unigram 模型切分
4. 数据准备与处理
a. 数据采集: 真实数据,web 抓取,人造数据
b. 数据标注: 专业标注公司,众包,主动学习,设计产品形态
c. 数据清洗: 去除不相关数据,去除冗余数据,去除误导数据
d. 样本均衡性: 尽量保证每个标签都有足够训练的样本,每个标签对应的数据尽量相等,数据不均衡策略
5. 数据集构建
a. 数据充分的情况: 切分训练集,验证集,测试集,采用随机采样保证数据分布一致
b. 数据的确太少: 交叉验证
总结
好好学习模型训练,在我的有生之年一定可以造出来通用人工智能体,但是我绝不会把自己的意识上传,人生三万天足以,1万天用于野蛮成长,1万天用于发展(拼搏向上),1万天学会下山(小隐隐于世)。
后会无期,未来可期!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号