
Ceph 集群搭建实践
前情提要
ceph 集群之前通过 rook-ceph 搭建过,但是对于 ceph 的组件还有用途却不是很了解,正好最近可以进行整理验证一下手工搭建 ceph 集群,并且整理下相关的使用命令,针对这种分布式的存储系统进行全面的了解;
Ceph文件系统简述
Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。
Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。
a. Ceph的优点
- 高性能
a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
c. 能够支持上千个存储节点的规模,支持TB到PB级的数据。 - 高可用性
a. 副本数可以灵活控制。
b. 支持故障域分隔,数据强一致性。
c. 多种故障场景自动进行修复自愈。
d. 没有单点故障,自动管理。 - 高可扩展性
a. 去中心化。
b. 扩展灵活。
c. 随着节点增加而线性增长。 - 特性丰富
a. 支持三种存储接口:块存储、文件存储、对象存储。
b. 支持自定义接口,支持多种语言驱动。
Ceph架构与组件
Ceph 架构
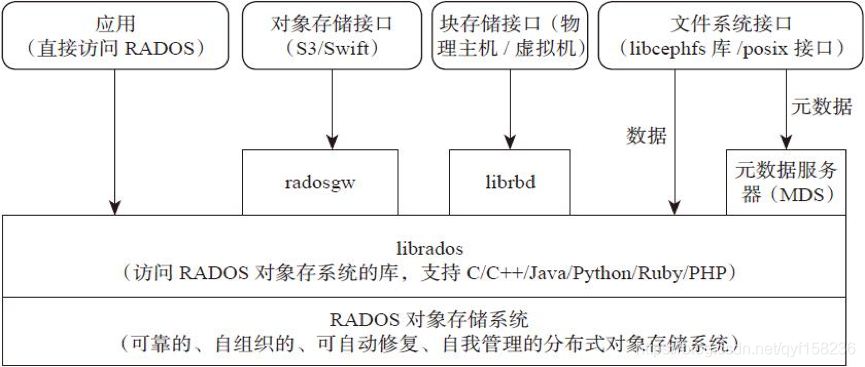
Ceph核心组件及概念介绍
-
Monitor
一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。 -
OSD
OSD全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有很多个OSD。 -
MDS
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。 -
Object
Ceph最底层的存储单元是Object对象,每个Object包含元数据和原始数据。 -
PG
PG全称Placement Grouops,是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。 -
RADOS
RADOS全称Reliable Autonomic Distributed Object Store,是Ceph集群的精华,用户实现数据分配、Failover等集群操作。 -
Libradio
Librados是Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。 -
CRUSH
CRUSH是Ceph使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方。 -
RBD
RBD全称RADOS block device,是Ceph对外提供的块设备服务。 -
RGW
RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。 -
CephFS
CephFS全称Ceph File System,是Ceph对外提供的文件系统服务。
Ceph的存储过程
CEPH集群在存储数据时,都是进行扁平化处理,Object作为集群最小的存储单位。
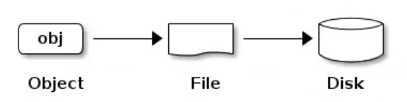
ceph在对象存储的基础上提供了更加高级的思想。当对象数量达到了百万级以上,原生的对象存储在索引对象时消耗的性能非常大。ceph因此引入了placement group (pg) 的概念。一个PG就是一组对象的集合。
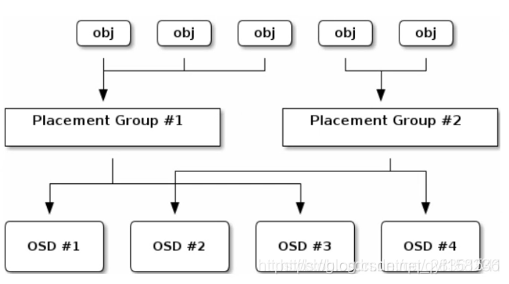
Ceph IO流程及数据分布
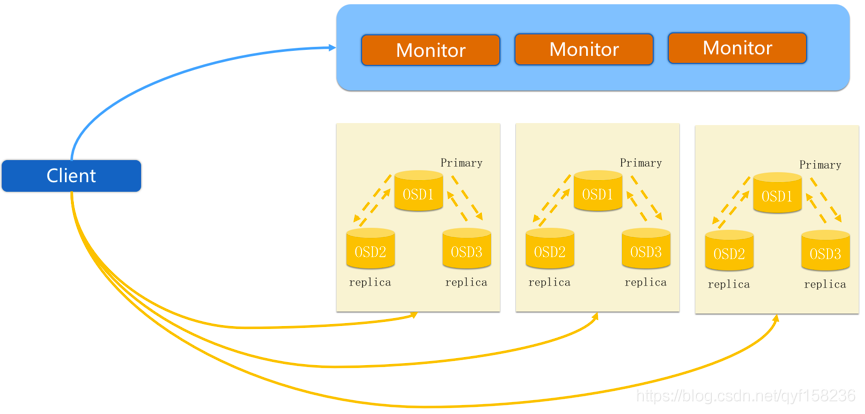
正常IO流程图
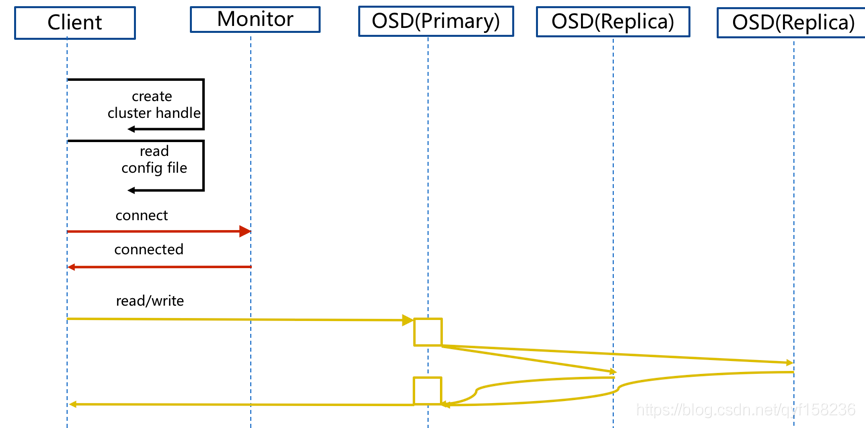
通信步骤:
- client 创建cluster handler。
- client 读取配置文件。
- client 连接上monitor,获取集群map信息。
- client 读写io 根据crushmap 算法请求对应的主osd数据节点。
- 主osd数据节点同时写入另外两个副本节点数据。
- 等待主节点以及另外两个副本节点写完数据状态。
- 主节点及副本节点写入状态都成功后,返回给client,io写入完成。
Ceph IO算法流程
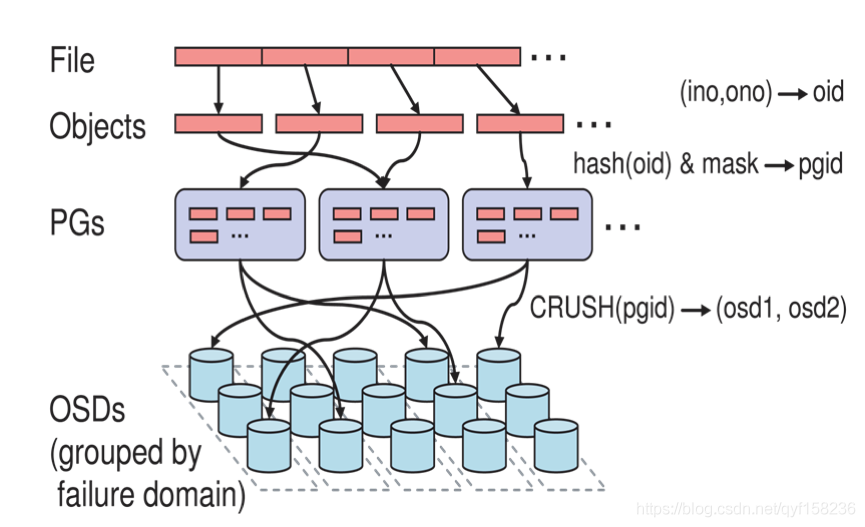
-
File用户需要读写的文件。File->Object映射:
a. ino (File的元数据,File的唯一id)。
b. ono(File切分产生的某个object的序号,默认以4M切分一个块大小)。
c. oid(object id: ino + ono)。 -
Object是RADOS需要的对象。Ceph指定一个静态hash函数计算oid的值,将oid映射成一个近似均匀分布的伪随机值,然后和mask按位相与,得到pgid。Object->PG映射:
a. hash(oid) & mask-> pgid 。
b. mask = PG总数m(m为2的整数幂)-1 。 -
PG(Placement Group),用途是对object的存储进行组织和位置映射, (类似于redis cluster里面的slot的概念),一个PG里面会有很多object。采用CRUSH算法,将pgid代入其中,然后得到一组OSD。PG->OSD映射:
a. CRUSH(pgid)->(osd1,osd2,osd3) 。
Ceph RBD IO流程
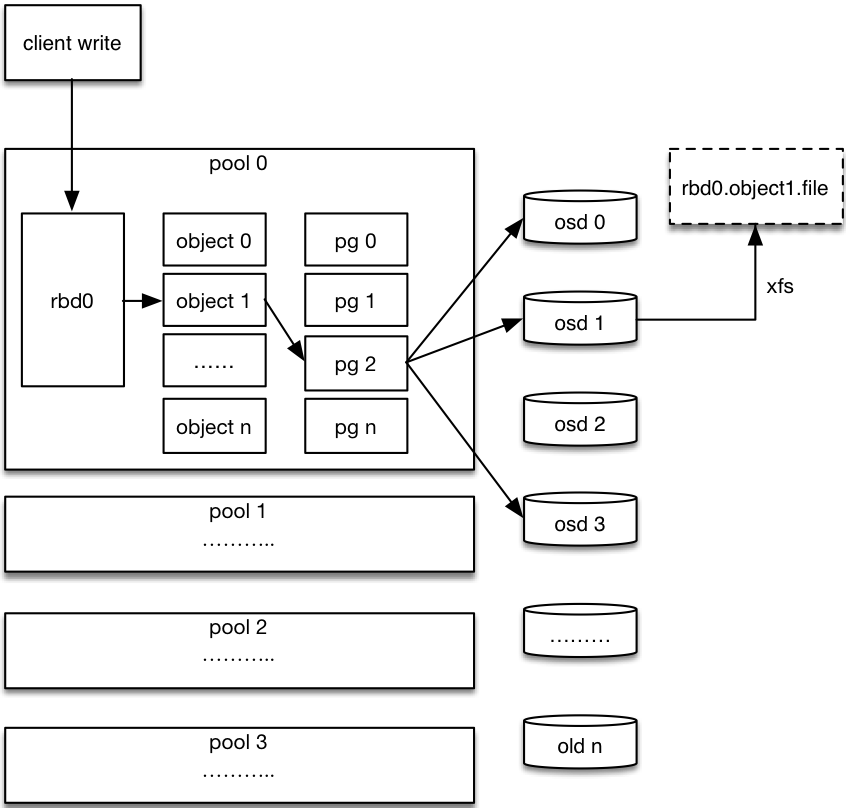
流程步骤:
- 客户端创建一个pool,需要为这个pool指定pg的数量。
- 创建pool/image rbd设备进行挂载。
- 用户写入的数据进行切块,每个块的大小默认为4M,并且每个块都有一个名字,名字就是object+序号。
- 将每个object通过pg进行副本位置的分配。
- pg根据cursh算法会寻找3个osd,把这个object分别保存在这三个osd上。
- osd上实际是把底层的disk进行了格式化操作,一般部署工具会将它格式化为xfs文件系统。
- object的存储就变成了存储一个文rbd0.object1.file。
Ceph RBD IO框架图
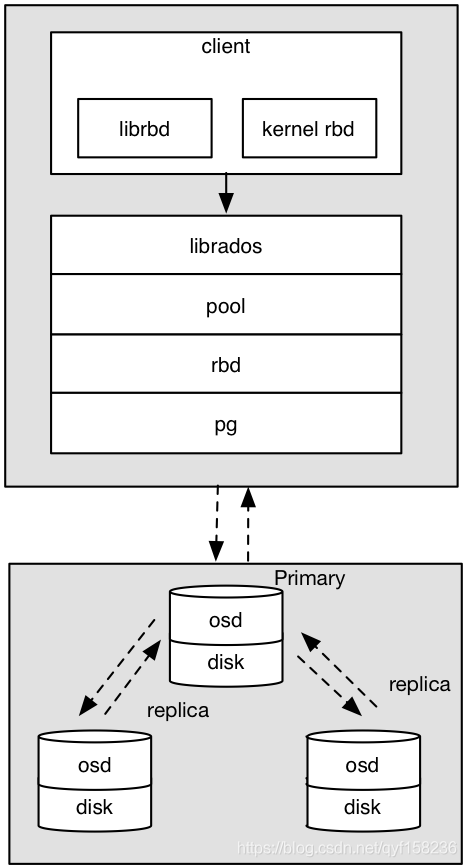
客户端写数据osd过程:
- 采用的是librbd的形式,使用librbd创建一个块设备,向这个块设备中写入数据。
- 在客户端本地同过调用librados接口,然后经过pool,rbd,object、pg进行层层映射,在PG这一层中,可以知道数据保存在哪3个OSD上,这3个OSD分为主从的关系。
- 客户端与primay OSD建立SOCKET 通信,将要写入的数据传给primary OSD,由primary OSD再将数据发送给其他replica OSD数据节点。
Ceph搭建过程
资源准备
- 1.准备三台centos7虚拟机。
- 2.每台虚拟机安装两块网卡,一块仅主机模式,一块nat模式。
- 3.准备两块硬盘,一块系统盘,另一块作为ceph使用大小500G。
| 主机 | VM1 | NAT |
|---|---|---|
| ceph1 | 192.168.0.10 | 36.139.125.143 |
| ceph2 | 192.168.0.15 | 36.139.125.48 |
| ceph3 | 192.168.0.20 | 36.139.125.228 |
预配置
每个节点都要操作,步骤一样
1、每个节点的修改主机名,和hosts文件
# 设置主机名
hostnamectl set-hostname cephX
# 修改主机映射
vi /etc/hosts
192.168.0.10 ceph1
192.168.0.15 ceph2
192.168.0.20 ceph3
2、关闭UseDNS,用CRT连接可以快一点
vi /etc/ssh/sshd_config
115/UseDNS no
3、关闭防火墙和核心防护
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
vi /etc/selinux/config
SELINUX =disabled
4、三个节点创建免交互
ssh-keygen
ssh-copy-id root@ceph1
ssh-copy-id root@ceph2
ssh-copy-id root@ceph3
5、配置YUM源
cd /etc/yum.repos.d/
mkdir backup
mv C* backup
//安装wget命令,方便下载新的yum源。
yum install wget -y
//用wget命令下载新的yum源。
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
//配置ceph源
vi /etc/yum.repos.d/ceph.repo
[ceph]
name=Ceph packages for
baseurl=https://mirrors.aliyun.com/ceph/rpm-mimic/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[ceph-noarch]
name=Ceph noarch packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-mimic/el7/SRPMS/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
- 配置时间同步
yum -y install ntpdate
ntpdate -u cn.ntp.org.cn
crontab -e
*/20 * * * * ntpdate -u cn.ntp.org.cn > /dev/null 2>&1
systemctl reload crond.service
安装ceph集群
1.首先安装好相应的工具
//ceph1节点
yum install ceph-deploy ceph python-setuptools -y
//ceph2、ceph3节点
yum install ceph python-setuptools -y
//每个节点都创建目录
mkdir /etc/ceph
管理节点创建mon并初始化,收集秘钥
[root@ceph1 yum.repos.d]# cd /etc/ceph
[root@ceph1 ceph]# ceph-deploy new ceph1 ceph2 '//创建mon'
[root@ceph1 ceph]# ceph-deploy mon create-initial '//初始化,收集秘钥'
# 查看集群状态
[root@ceph1 ceph]# ceph -s
创建osd:
[root@ceph1 ceph]# ceph-deploy osd create --data /dev/sdb ceph1
[root@ceph1 ceph]# ceph-deploy osd create --data /dev/sdb ceph2
[root@ceph1 ceph]# ceph -s '//查看集群状态会发现有两个osd加入进来了'
[root@ceph1 ceph]# ceph osd tree '//查看osd目录树'
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 1.99799 root default
-3 0.99899 host ceph1
0 hdd 0.99899 osd.0 up 1.00000 1.00000
-5 0.99899 host ceph2
1 hdd 0.99899 osd.1 up 1.00000 1.00000
[root@ceph01 ceph]# ceph osd stat '//查看osd状态'
2 osds: 2 up, 2 in; epoch: e9
将配置文件和admin秘钥下发到节点并给秘钥增加权限:
[root@ceph1 ceph]# ceph-deploy admin ceph1 ceph2
[root@ceph1 ceph]# chmod +r ceph.client.admin.keyring
[root@ceph2 ceph]# chmod +r ceph.client.admin.keyring
# 2.3.3:扩容操作: 扩容ceph3节点的osd和mon
[root@ceph1 ceph]# ceph-deploy osd create --data /dev/sdb ceph3
[root@ceph1 ceph]# ceph -s '//已经有三个osd了'
[root@ceph1 ceph]# vi ceph.conf
[global]
fsid = b175fb1a-fdd6-4c57-a41f-b2d964dff248
mon_initial_members = ceph1, ceph2, ceph3 '//添加ceph3'
mon_host = mon_host = 192.168.0.10,192.168.0.15,192.168.0.20
'//添加ceph3 IP地址'
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
public network = 192.168.0.0/24 '//添加内部通信网段'
[root@ceph1 ceph]# ceph-deploy --overwrite-conf config push ceph1 ceph2 ceph3
[root@ceph1 ceph]# ceph-deploy mon add ceph3 '//添加mon'
[root@ceph1 ceph]# systemctl list-unit-files |grep mon '//查看已启动的含mon列表'
三台主机重启mon服务
[root@ceph1 ceph]# systemctl restart ceph-mon.target
[root@ceph1 ceph]# ceph -s
osd 故障模拟
1、首先模拟故障,将一个osd从集群中移除
移除osd,删除osd,删除osd认证
ceph osd out osd.2
ceph osd crush remove osd.2
ceph auth del osd.2
#重启所有节点osd服务,osd.2就down掉了
systemctl restart ceph-osd.target
# 查看 osd 状态
ceph osd tree
2、恢复osd到集群中
//在ceph3节点,查看ceph位置信息
df -hT
显示位置信息:
tmpfs tmpfs 910M 52K 910M 1% /var/lib/ceph/osd/ceph-2
//查看/var/lib/ceph/osd/ceph-2的fsid
[root@ceph3 ~]# cd /var/lib/ceph/osd/ceph-2
[root@ceph3 ceph-2]# more fsid
57df2d3e-2f53-4143-9c3f-5e98d0ae619b
//重新添加osd进入集群
[root@ceph3 ceph-2]# ceph osd create 57df2d3e-2f53-4143-9c3f-5e98d0ae619b
//重新添加认证权限
[root@ceph3 ceph-2]# ceph auth add osd.2 osd 'allow *' mon 'allow rwx' -i /var/lib/ceph/osd/ceph-2/keyring
//设置ceph3的权重,ceph osd crush add osdID号 权重 host=主机名
[root@ceph3 ceph-2]# ceph osd crush add 2 0.99899 host=ceph3
//将osd加入集群
[root@ceph0 ceph-2]# ceph osd in osd.2
//重启所有节点的osd服务
systemctl restart ceph-osd.target
# 查看 osd 状态
ceph osd tree
开启MGR监控模块
基于配置文件
# 编辑ceph.conf文件
vi ceph.conf
[mon]
mgr initial modules = dashboard
#推送配置
[admin@admin my-cluster]$ ceph-deploy --overwrite-conf config push ceph1 ceph2 ceph3
#重启mgr
sudo systemctl restart ceph-mgr@ceph1
web登录配置
默认情况下,仪表板的所有HTTP连接均使用SSL/TLS进行保护。
#要快速启动并运行仪表板,可以使用以下内置命令生成并安装自签名证书:
[root@node1 my-cluster]# ceph dashboard create-self-signed-cert
Self-signed certificate created
#创建具有管理员角色的用户:
[root@node1 my-cluster]# ceph dashboard set-login-credentials admin admin
Username and password updated
#查看ceph-mgr服务:
[root@node1 my-cluster]# ceph mgr services
{
"dashboard": "https://node1:8443/"
}
以上配置完成后,浏览器输入https://node1:8443输入用户名admin,密码admin登录即可查看;
总结
基于分布式的云原生领域,存储类,网络类,容器,微服务,函数服务,中间件等等,最近两年的时间积累了太多的知识点,但是一直没有合适的时间进行整理,毕竟温故而知新,常更常新吗!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号