K8s & K3s 如何监控压力测试
背景简介
随着容器技术的发展,容器服务已经成为行业主流,然而想要在生产环境中成功部署和操作容器,关键还是容器编排技术。市场上有各种各样的容器编排工具,如Docker原生的Swarm、Mesos、Kubernetes等,其中Google开发的Kubernetes因为业界各大巨头的加入和开源社区的全力支撑,成为了容器编排的首选。
简单来讲,Kubernetes是容器集群管理系统,为容器化的应用提供资源调度、部署运行、滚动升级、扩容缩容等功能。容器集群管理给业务带来了便利,但是随着业务的不断增长,应用数量可能会发生爆发式的增长。那在这种情况下,Kubernetes能否快速地完成扩容、扩容到大规模时Kubernetes管理能力是否稳定成了挑战。
K8s & K3s 架构
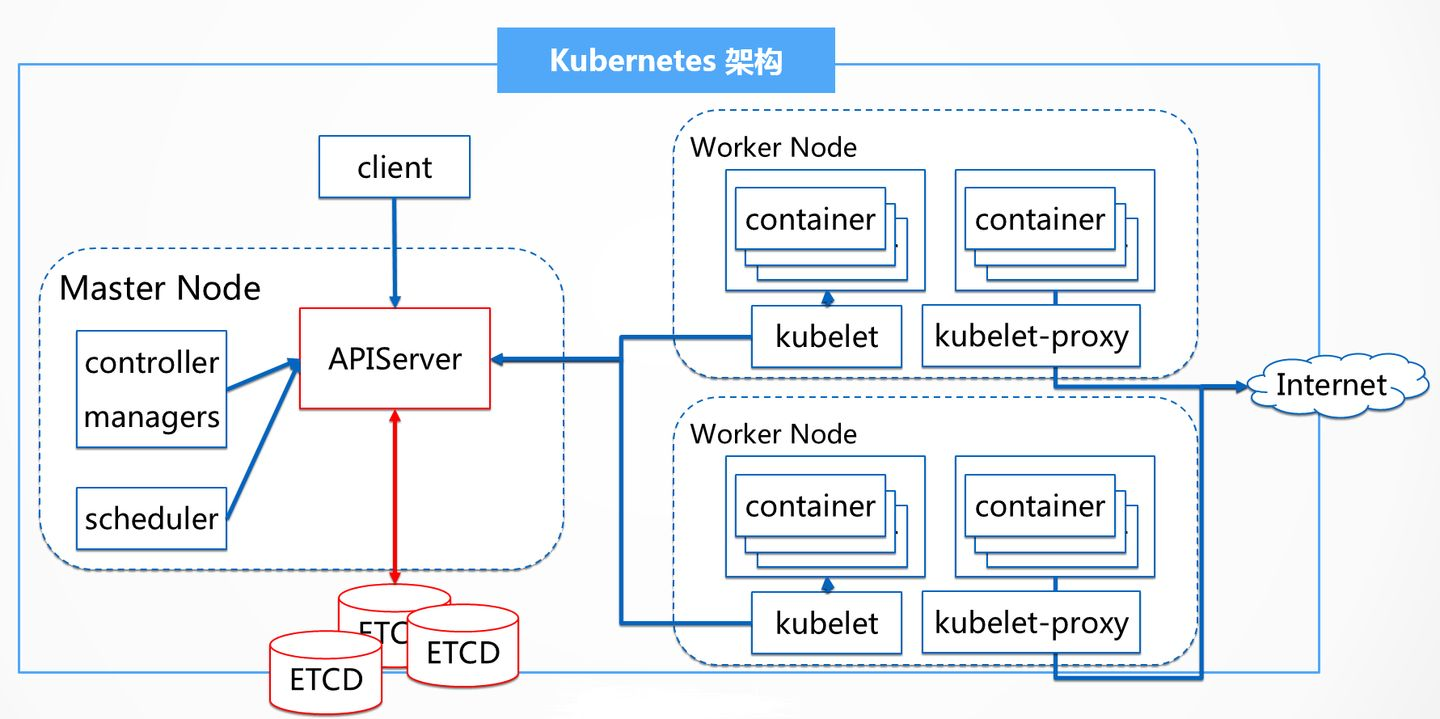
集群内部:如上Kubernetes架构图所示,无论外部客户端,还是Kubernetes集群内部组件,其通信都需要经过Kubernetes的apiserver,API的响应性决定着集群性能的好坏。
集群外部:对于外部客户而言,他只关注创建容器服务所用的时间,因此,pod的启动时间也是影响集群性能的另外一个因素。
目前,业内普遍采用的性能标准是:
- API响应性:99%的API调用响应时间小于1s。
- Pod启动时间:99%的pods(已经拉取好镜像)启动时间在5s以内。
“pod启动时间”包括了ReplicationController的创建,RC依次创建pod,调度器调度pod,Kubernetes为pod设置网络,启动容器,等待容器成功响应健康检查,并最终等待容器将其状态上报回API服务器,最后API服务器将pod的状态报告给正在监听中的客户端。
除此之外,网络吞吐量、镜像大小(需要拉取)都会影响Kubernetes的整体性能。
Kubernetes性能的关键点
1 当集群资源使用率是X%(50%、90% 、99%等不同规模下)的时候,创建新的pod所需的时间(这种场景需要提前铺底,然后在铺底基础上用不同的并发梯度创建pod,测试pod创建耗时,评估集群性能)。在测试kubernetes新版本时,一般是以老版本稳定水位(node、pod等)铺底,然后梯度增加进行测试。
2 当集群使用率高于90%时,容器启动时延的增大(系统会经历一个异常的减速)还有etcd测试的线性性质和“模型建立”的因素。调优方法是:调研etcd新版本是否有解决该问题。
3 测试的过程中要找出集群的一个最高点,低于和高于这个阈值点,集群性能都不是最优的。
4 组件负载会消耗master节点的资源,资源消耗所产生的不稳定性和性能问题,会导致集群不可用。所以,在测试过程中要时刻关注资源情况。
5 客户端创建资源对象的格式 —— API服务对编码和解码JSON对象也需要花费大量的时间 —— 这也可以作为一个优化点。
集群压测
集群整体指标
1 不同的集群使用水位线(0%,50%, 90%)上,pod/deployment(rs 等资源)创建、扩缩容等核心操作的性能。可以通过预先创建出一批dp(副本数默认设置为3)来填充集群,达到预期的水位,即铺底。
2 不同水位对系统性能的影响——安全水位,极限水位
3 容器有无挂载数据盘对容器创建性能的影响。例如,挂载数据盘增加了kubelet挂载磁盘的耗时,会增加pod的启动时长。
测试kubernetes集群的性能时,重点关注在不同水位、不同并发数下,长时间执行压力测试时,系统的稳定性,包括:
1 系统性能表现,在较长时间范围内的变化趋势
2 系统资源使用情况,在较长时间范围内的变化趋势
3 各个服务组件的TPS、响应时间、错误率
4 内部模块间访问次数、耗时、错误率等内部性能数据
5 各个模块资源使用情况
6 各个服务端组件长时间运行时,是否出现进程意外退出、重启等情况
7 服务端日志是否有未知错误
8 系统日志是否报错
apiserver
1 关注api的响应时间。数据写到etcd即可,然后根据情况关注异步操作是否真正执行完成。
2 关注apiserver缓存的存储设备对性能的影响。例如,master端节点的磁盘io。
3 流控对系统、系统性能的影响。
4 apiserver 日志中的错误响应码。
5 apiserver 重启恢复的时间。需要考虑该时间用户是否可接受,重启后请求或者资源使用是否有异常。
6 关注apiserver在压力测试情况下,响应时间和资源使用情况。
scheduler
1 压测scheduler处理能力
并发创建大量pod,测试各个pod被调度器调度的耗时(从Pod创建到其被bind到host)
不断加大新建的pod数量来增加调度器的负载
关注不同pod数量级下,调度器的平均耗时、最大时间、最大QPS(吞吐量)
2 scheduler 重启恢复的时间(从重启开始到重启后系统恢复稳定)。需要考虑该时间用户是否可接受,重启后请求或者资源使用是否有异常。
3 关注scheduler日志中的错误信息。
controller
1 压测 deployment controller处理能力
并发创建大量rc(1.3 以后是deployment,单副本),测试各个deployment被空感知并创建对应rs的耗时
观察rs controller创建对应pod的耗时
扩容、缩容(缩容到0副本)的耗时
注: 不断加大新建deployment的数,测试在不同deployment数量级下,控制器处理deployment的平均耗时、最大时间、最大QPS(吞吐量)和控制器负载等情况
2 controller 重启恢复的时间(从重启开始到重启后系统恢复稳定)。需要考虑该时间用户是否可接受,重启后请求或者资源使用是否有异常。
3 关注controller日志中的错误信息。
kubelet
1 node心跳对系统性能的影响。
2 kubelet重启恢复的时间(从重启开始到重启后系统恢复稳定)。需要考虑该时间用户是否可接受,重启后请求或者资源使用是否有异常。
3 关注kubelet日志中的错误信息。
etcd
1 关注etcd 的写入性能
写最大并发数
写入性能瓶颈,这个主要是定期持久化snapshot操作的性能
2 etcd 的存储设备对性能的影响。例如,写etcd的io。
3 watcher hub 数对kubernetes系统性能的影响。
Kubectl 基础命令
- 资源创建
# 创建资源,也可以使用远程 URL
kubectl create -f ./my.yaml
# 使用多个文件创建资源
kubectl create -f ./my1.yaml -f ./my2.yaml
# 使用目录下的所有清单文件来创建资源
kubectl create -f ./dir
# 启动一个 nginx 实例
kubectl run nginx --image=ngin
- 显示和查找
# 列出所有 namespace 中的 service
kubectl get services
# 列出所有 namespace 中的 pod
kubectl get pods --all-namespaces
# 列出 kube-system 中的 pod
kubectl get pods -n kube-system
# 列出所有 pod 并显示详细信息
kubectl get pods -o wid
- 更新资源
# 滚动更新 pod frontend-v1
kubectl rolling-update frontend-v1 -f frontend-v2.json
# 更新资源名称并更新镜像
kubectl rolling-update frontend-v1 frontend-v2 --image=image:v2
# 更新 frontend pod 中的镜像
kubectl rolling-update frontend --image=image:v2
# 强制替换,删除后重新创建资源。会导致服务中断。
kubectl replace --force -f ./pod.json
# 为 nginx RC 创建服务,启用本地 80 端口连接到容器上的 8000 端口
kubectl expose rc nginx --port=80 --target-port=800
- 删除资源
# 删除 pod.json 文件中定义的类型和名称的 pod
kubectl delete -f ./pod.json
# 删除名为 "baz" 的 pod 和名为 "foo" 的 service
kubectl delete pod, service baz foo
# 删除具有 name=myLabel 标签的 pod 和 serivce
kubectl delete pods, services -l name=myLabel
# 删除具有 name=myLabel 标签的 pod 和 service,包括尚未初始化的
kubectl delete pods, services -l name=myLabel --include-uninitialized
# 删除 my-ns namespace 下的所有 pod 和 serivce,包括尚未初始化的
kubectl -n my-ns delete po,svc --al
- pod交互
# 流式输出 pod 的日志(stdout
kubectl logs -f my-pod
# 流式输出 pod 中容器的日志(stdout,pod 中有多个容器的情况下使用)
kubectl logs -f my-pod -c my-container
# 交互式 shell 的方式运行 pod
kubectl run -i --tty busybox --image=busybox -- sh
# 连接到运行中的容器
kubectl attach my-pod -i
# 在已存在的容器中执行命令(pod 中有多个容器的情况下)
kubectl exec my-pod -c my-container -- ls
Dashboard简介
Kubernetes Dashboard 是一个管理 Kubernetes 集群的全功能 Web 界面,旨在以 UI 的方式完全替代命令行工具(kubectl 等)。
在 Dashboard 页面上,可以查看 Kubernetes 的集群状态,对集群进行相关的操作。但是,Dashboard 无法图形化展现集群度量指标信息,需要安装 Heapser 插件。
kubernetes-dashboard搭建方式: https://www.cnblogs.com/vpc123/articles/14366619.html
监控架构图如下

- cAdvisor,是 Kubelet 内置的容器资源收集工具。它会自动收集本机容器 CPU、内存、网络和文件系统的资源占用情况,并对外提供 API。
- InfluxDB,是一个开源分布式时序、事件和指标数据库。
- Grafana,是 InfluxDB 的 Dashboard,提供了强大的图表展示功能。常和 InfluxDB 组合使用,展示图表化的监控数据。
- Heapster,提供了整个集群的资源监控,并支持持久化数据存储到 InfluxDB 等后端存储。
- kube-state-metrics,除了配置 cAdvisor、Heapster、Influx、Grafana,还可以考虑部署 kube-state-metrics。kube-state-metrics 会轮询 Kubernetes API 调度了多少个replicas、现在可用的有几个、多少个 Pod 是 running、stopped、terminated 状态、Po 重启了多少次。
参数配置如下
- 获取官方配置 yaml:
git clone https://github.com/kubernetes/heapster.git
# 查看 yaml 配置列表
ls -l deploy/kube-config/influxdb/
grafana.yaml
heapster.yaml
influxdb.yaml
- Heapster、InfluxDB、Grafana 均以 Pod 的形式启动和运行,创建 Pod:
kubectl create -f deploy/kube-config/influxdb/
deployment.extensions/monitoring-grafana created
service/monitoring-grafana created
serviceaccount/heapster created
deployment.extensions/heapster created
service/heapster created
deployment.extensions/monitoring-influxdb created
service/monitoring-influxdb created
- 可能需要等待几分钟,Pod 才会处于 Running 状态:
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
heapster-7ff8d6bf9f-ngb9p 1/1 Running 0 31m
monitoring-grafana-68b57d754-4qwjm 1/1 Running 0 31m
monitoring-influxdb-cc95575b9-5j556 1/1 Running 0 31m
- 配置完毕之后,发现 Dashboard 并没有显示 CPU、内存等信息,查看 Heapser 日志:
kubectl logs -f heapster-7ff8d6bf9f-ngb9p -n kube-system
1 reflector.go:190] k8s.io/heapster/metrics/util/util.go:30: Failed to list *v1.Node: nodes is forbidden: User "system:serviceaccount:kube-system:heapster" cannot list nodes at the cluster scope
- 提示缺角色,无权访问。新增授权:
kubectl create -f deploy/kube-config/rbac/heapster-rbac.yaml
clusterrolebinding.rbac.authorization.k8s.io/heapster created
- 更新 Heapser:
kubectl replace --force -f deploy/kube-config/influxdb/heapster.yaml
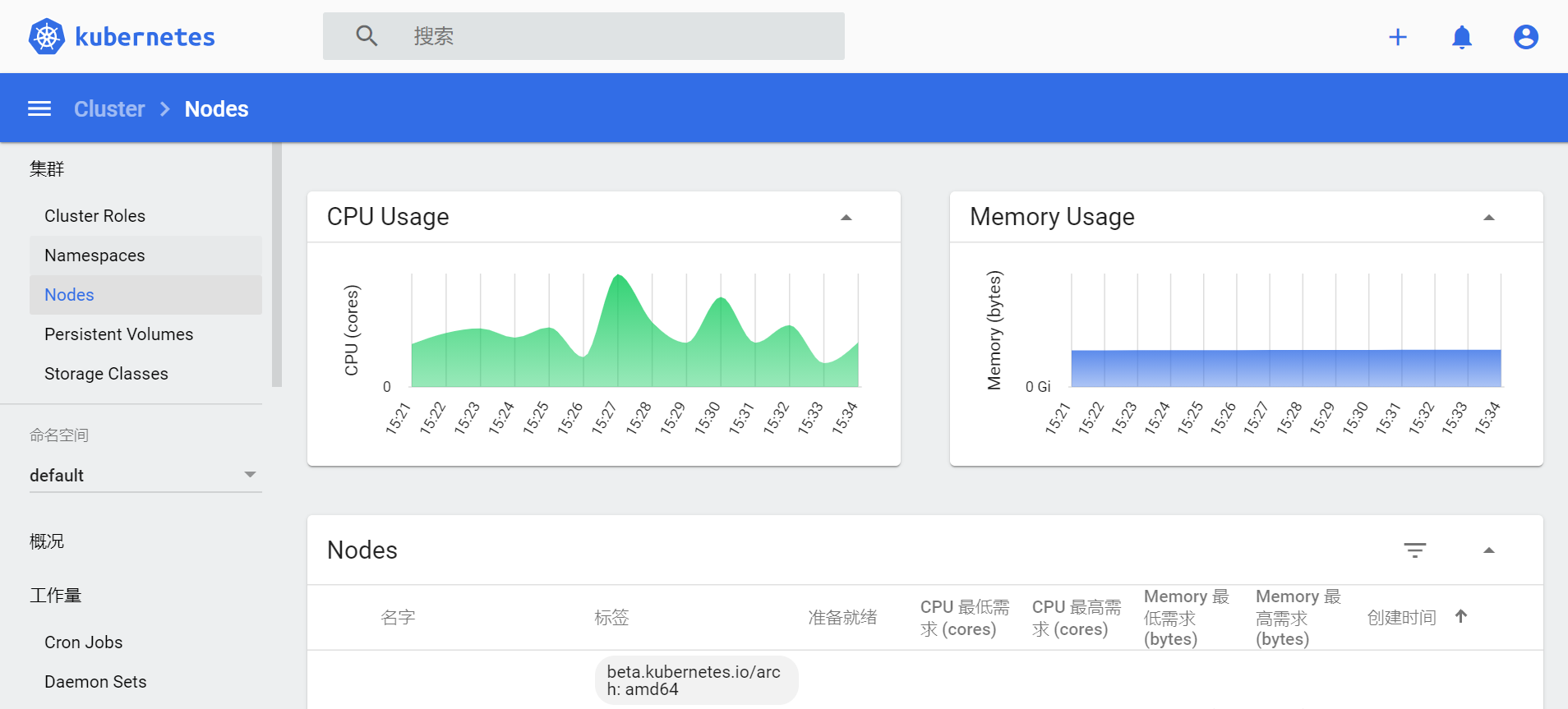
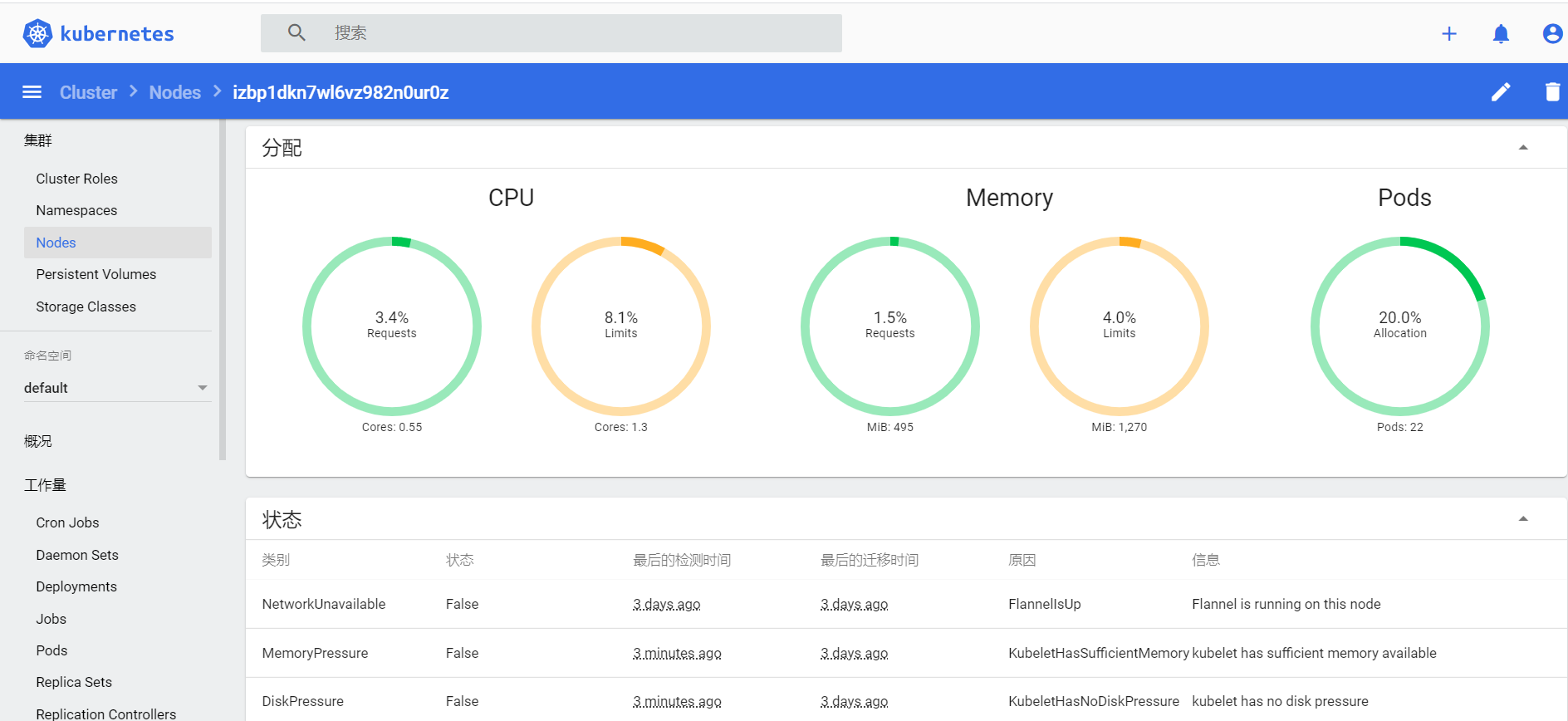
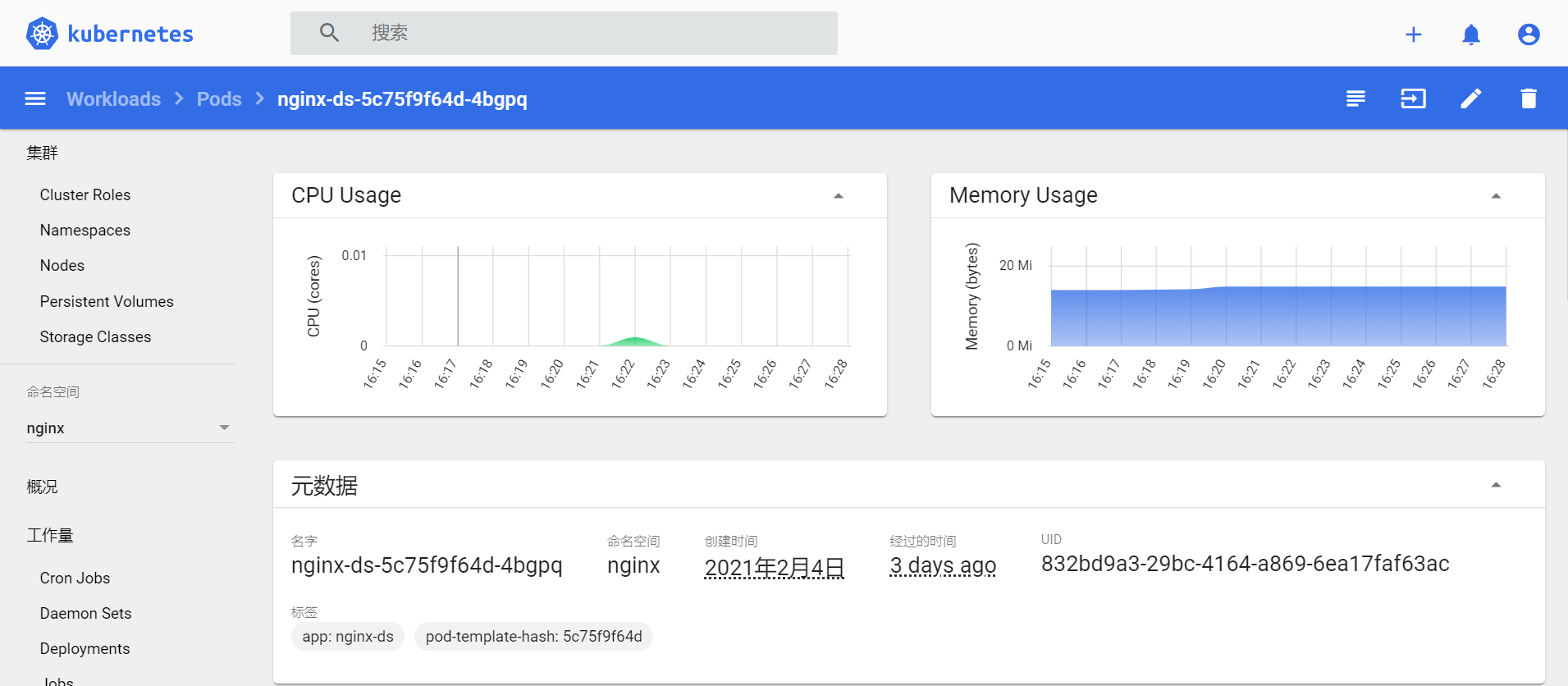
- 再次查看 Dashboard,Nodes 和 Pods 中,可以非常直观的看到 CPU 和 MEM 的使用情况。
压力测试
Apache 提供的 ab 工具,对 Kubernetes 托管的 Nginx 服务进行简单的压力测试实验。
- 安装 Apache
********** Windows 安装 ab *********
# 安装 choco (管理员权限打开)
@powershell -NoProfile -ExecutionPolicy Bypass -Command "iex ((new-object net.webclient).DownloadString('https://chocolatey.org/install.ps1'))" && SET PATH=%PATH%;%ALLUSERSPROFILE%\chocolatey\bin
# 安装 apache-httpd
choco install apache-httpd
********** Linux 安装 ab *********
yum -y install httpd-tools

- 执行测试
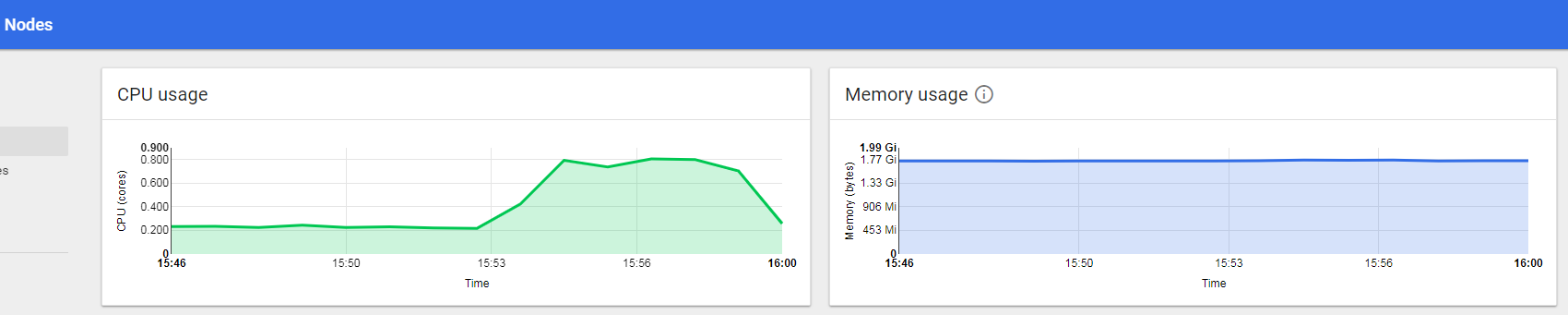
压测开始后,在 Dashboard 看到 CPU 和内存使用量
ab -c 125 -n 400000 http://集群地址IP:端口/
//并发请求数
Concurrency Level: 125
//整个测试持续的时间
Time taken for tests: 317.350 seconds
//完成的请求数
Complete requests: 400000
//失败的请求数
Failed requests: 0
//吞吐率
Requests per second: 1260.44 [#/sec] (mean)
//用户平均请求等待时间
Time per request: 99.172 [ms] (mean)
//服务器平均请求处理时间
Time per request: 0.793 [ms] (mean, across all concurrent requests)
拓展阅读
ab是apachebench命令的缩写。
ab的原理:ab命令会创建多个并发访问线程,模拟多个访问者同时对某一URL地址进行访问。它的测试目标是基于URL的,因此,它既可以用来测试apache的负载压力,也可以测试nginx、lighthttp、tomcat、IIS等其它Web服务器的压力。
ab命令对发出负载的计算机要求很低,它既不会占用很高CPU,也不会占用很多内存。但却会给目标服务器造成巨大的负载,其原理类似CC攻击。自己测试使用也需要注意,否则一次上太多的负载。可能造成目标服务器资源耗完,严重时甚至导致死机。
- 压测工具安装
yum -y install httpd-tools
- ab 用法
ab [options] [http://]hostname[:port]/path
# ab 示例
ab -n 5000 -c 200 http://localhost/index.php
# 常见参数如下
-n :总共的请求执行数,缺省是1;
-c: 并发数,缺省是1;
-t:测试所进行的总时间,秒为单位,缺省50000s
-p:POST时的数据文件
-w: 以HTML表的格式输出结果
执行测试用例:ab -n 1000 -c 100 -w http://localhost/index.php >>d:miss.html
