
最长公共子序列
- 标签:字符串处理、前缀判断
题目
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如,"ace" 是 "abcde" 的子序列,但 "aec" 不是 "abcde" 的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
示例 1:
输入:text1 = "abcde", text2 = "ace"
输出:3
解释:最长公共子序列是 "ace" ,它的长度为 3 。
示例 2:
输入:text1 = "abc", text2 = "abc"
输出:3
解释:最长公共子序列是 "abc" ,它的长度为 3 。
示例 3:
输入:text1 = "abc", text2 = "def"
输出:0
解释:两个字符串没有公共子序列,返回 0 。
提示:
1 <= text1.length, text2.length <= 1000
text1 和 text2 仅由小写英文字符组成。
思路及实现
方式一:暴力递归(不推荐,但容易想到)
思路
暴力递归的解决思路是很容易想到的。
递归函数返回两个字符串 str1,str2 到 index1,index2 位置的最长公共子序列的长度。
递归终止的条件是两个串中任意一个串是空串,那么最长公共子序列的长度为 0。
到任意一个 index1,index2 位置有以下几种可能性
最长公共子序列的最后一个值和 str1[index1] 、str2[index2]都相同。
最长公共子序列的最后一个值和 str1[index1] 、str2[index2]都不相同。
最长公共子序列的最后一个值和 str1[index1] 、str2[index2]其中一个相同。
这样就把问题拆分成了子问题,使用递归求解。
代码实现
Java版本
class Solution {
public int longestCommonSubsequence(String text1, String text2) {
return process(text1.toCharArray(), text1.length() - 1, text2.toCharArray(), text2.length() - 1);
}
public int process(char[] str1, int index1, char[] str2, int index2) {
// 递归终止条件,当其中一个字符数组已经遍历完时,返回0
if (index2 < 0 || index1 < 0) {
return 0;
}
// 如果当前字符相等,则两个字符都向前移动一位,并且最长公共子序列长度加1
if (str1[index1] == str2[index2]) {
return process(str1, index1 - 1, str2, index2 - 1) + 1;
} else {
// 如果当前字符不相等,分别计算三种情况下的最长公共子序列长度,并返回最大值
int p1 = process(str1, index1, str2, index2 - 1); // 在str2中减去当前字符
int p2 = process(str1, index1 - 1, str2, index2); // 在str1中减去当前字符
int p3 = process(str1, index1 - 1, str2, index2 - 1); // 在str1和str2中同时减去当前字符
return Math.max(Math.max(p1, p2), p3);
}
}
}
说明:
在longestCommonSubsequence方法中,将输入字符串转换为字符数组,并调用process方法来求解最长公共子序列问题。process方法递归地处理问题,根据当前字符是否相等进行判断:
如果当前字符相等,则最长公共子序列长度等于在两个字符串都减去当前字符的情况下的最长公共子序列长度加1。
如果当前字符不相等,分别计算在str2中减去当前字符、在str1中减去当前字符以及在str1和str2中同时减去当前字符的三种情况下的最长公共子序列长度,并返回最大值。
通过递归回溯的过程,依次处理所有字符的组合,最终得到最长公共子序列的长度。需要注意的是,递归解法可能会导致重复计算,因此在问题规模较大的情况下,可能需要使用记忆化技术对递归过程进行优化,避免重复计算。
优化:缓存优化记忆化搜索
对于上述递归过程,其实会有很多重复的求解过程。
把重复的解放到一个缓存里面,每次直接从缓存中取值,这样就可以减少很多的重复过程。
新建 db 数组(当然 map 也可以),作为缓存数组。
class Solution {
private int db[][];
public int longestCommonSubsequence(String text1, String text2) {
// 初始化二维数组db为-1
db = new int[text1.length()][text2.length()];
for (int i = 0; i < text1.length(); i++) {
for (int j = 0; j < text2.length(); j++) {
db[i][j] = -1;
}
}
return process(text1.toCharArray(), text1.length() - 1, text2.toCharArray(), text2.length() - 1);
}
public int process(char[] str1, int index1, char[] str2, int index2) {
// 递归终止条件,当其中一个字符数组已经遍历完时,返回0
if (index2 < 0 || index1 < 0) {
return 0;
}
// 如果当前字符已经计算过最长公共子序列长度,则直接返回结果
if (db[index1][index2] != -1) {
return db[index1][index2];
}
// 如果当前字符相等,则两个字符都向前移动一位,并且最长公共子序列长度加1
if (str1[index1] == str2[index2]) {
db[index1][index2] = process(str1, index1 - 1, str2, index2 - 1) + 1;
return db[index1][index2];
} else {
// 如果当前字符不相等,分别计算三种情况下的最长公共子序列长度,并返回最大值
int p1 = process(str1, index1, str2, index2 - 1); // 在str2中减去当前字符
int p2 = process(str1, index1 - 1, str2, index2); // 在str1中减去当前字符
int p3 = process(str1, index1 - 1, str2, index2 - 1); // 在str1和str2中同时减去当前字符
db[index1][index2] = Math.max(Math.max(p1, p2), p3);
return db[index1][index2];
}
}
}
说明:
在longestCommonSubsequence方法中,创建了大小为text1.length() x
text2.length()的二维数组db,并将其初始化为-1。该数组将用于保存中间计算结果。process方法递归地处理问题,增加了对中间计算结果是否已经保存的判断:
如果当前字符已经计算过最长公共子序列长度,则直接返回计算结果。
如果当前字符相等,则最长公共子序列长度等于在两个字符串都减去当前字符的情况下的最长公共子序列长度加1。
如果当前字符不相等,分别计算在str2中减去当前字符、在str1中减去当前字符以及在str1和str2中同时减去当前字符的三种情况下的最长公共子序列长度,并返回最大值。
通过这种记忆化的方式,可以避免重复计算,提高运行效率。
C语言版本
#include <stdio.h>
#include <string.h>
int db[1000][1000]; // 定义全局数组用于保存计算结果
int process(char* str1, int index1, char* str2, int index2) {
// 递归终止条件,当其中一个字符数组已经遍历完时,返回0
if (index2 < 0 || index1 < 0) {
return 0;
}
// 如果当前字符已经计算过最长公共子序列长度,则直接返回结果
if (db[index1][index2] != -1) {
return db[index1][index2];
}
// 如果当前字符相等,则两个字符都向前移动一位,并且最长公共子序列长度加1
if (str1[index1] == str2[index2]) {
db[index1][index2] = process(str1, index1 - 1, str2, index2 - 1) + 1;
return db[index1][index2];
} else {
// 如果当前字符不相等,分别计算三种情况下的最长公共子序列长度,并返回最大值
int p1 = process(str1, index1, str2, index2 - 1); // 在str2中减去当前字符
int p2 = process(str1, index1 - 1, str2, index2); // 在str1中减去当前字符
int p3 = process(str1, index1 - 1, str2, index2 - 1); // 在str1和str2中同时减去当前字符
db[index1][index2] = (p1 > p2) ? ((p1 > p3) ? p1 : p3) : ((p2 > p3) ? p2 : p3); // 取三者中的最大值
return db[index1][index2];
}
}
int longestCommonSubsequence(char* text1, char* text2) {
memset(db, -1, sizeof(db)); // 初始化数组为-1
return process(text1, strlen(text1) - 1, text2, strlen(text2) - 1);
}
/*
int main() {
char text1[] = "abcde";
char text2[] = "ace";
int result = longestCommonSubsequence(text1, text2);
printf("Longest Common Subsequence: %d\n", result);
return 0;
}
*/
说明
在process函数中,增加了对中间计算结果是否已经保存的判断:如果当前字符已经计算过最长公共子序列长度,则直接返回计算结果。
如果当前字符相等,则最长公共子序列长度等于在两个字符串都减去当前字符的情况下的最长公共子序列长度加1。
如果当前字符不相等,分别计算在str2中减去当前字符、在str1中减去当前字符以及在str1和str2中同时减去当前字符的三种情况下的最长公共子序列长度,并返回最大值。
通过全局数组db的记忆化方式,可以避免重复计算,提高运行效率。在longestCommonSubsequence函数中,使用memset函数将db数组初始化为-1。在main函数中,给定了两个示例字符串,并打印了最长公共子序列的长度。
Python3版本
def process(str1, index1, str2, index2, db):
# 递归终止条件,当其中一个字符数组已经遍历完时,返回0
if index2 < 0 or index1 < 0:
return 0
# 如果当前字符已经计算过最长公共子序列长度,则直接返回结果
if db[index1][index2] != -1:
return db[index1][index2]
# 如果当前字符相等,则两个字符都向前移动一位,并且最长公共子序列长度加1
if str1[index1] == str2[index2]:
db[index1][index2] = process(str1, index1 - 1, str2, index2 - 1, db) + 1
return db[index1][index2]
else:
# 如果当前字符不相等,分别计算三种情况下的最长公共子序列长度,并返回最大值
p1 = process(str1, index1, str2, index2 - 1, db) # 在str2中减去当前字符
p2 = process(str1, index1 - 1, str2, index2, db) # 在str1中减去当前字符
p3 = process(str1, index1 - 1, str2, index2 - 1, db) # 在str1和str2中同时减去当前字符
db[index1][index2] = max(p1, p2, p3) # 取三者中的最大值
return db[index1][index2]
def longestCommonSubsequence(text1, text2):
m, n = len(text1), len(text2)
db = [[-1] * n for _ in range(m)] # 创建二维数组并初始化为-1
return process(text1, m - 1, text2, n - 1, db)
# 示例用法
#text1 = "abcde"
#text2 = "ace"
#result = longestCommonSubsequence(text1, text2)
#print("Longest Common Subsequence:", result)
说明:
在process函数中,增加了对中间计算结果是否已经保存的判断:如果当前字符已经计算过最长公共子序列长度,则直接返回计算结果。
如果当前字符相等,则最长公共子序列长度等于在两个字符串都减去当前字符的情况下的最长公共子序列长度加1。
如果当前字符不相等,分别计算在str2中减去当前字符、在str1中减去当前字符以及在str1和str2中同时减去当前字符的三种情况下的最长公共子序列长度,并返回最大值。
通过二维数组db的记忆化方式,可以避免重复计算,提高运行效率。在longestCommonSubsequence函数中,创建了大小为m x n的二维数组db,并将其初始化为-1。
在示例用法中,给定了两个示例字符串,并打印了最长公共子序列的长度。
复杂度分析
- 时间复杂度:O(m * n),其中m和n分别是text1和text2的长度。
- 空间复杂度:O(m * n),主要用于存储中间计算结果的二维数组。
通过对中间计算结果的记忆化优化,递归解法避免了重复计算,提高了效率。但在某些情况下,仍可能存在大量的计算和存储开销。因此,实际应用中,可以结合其他解法如动态规划来进一步优化时间和空间复杂度。
方式二:动态规划(推荐)
思路
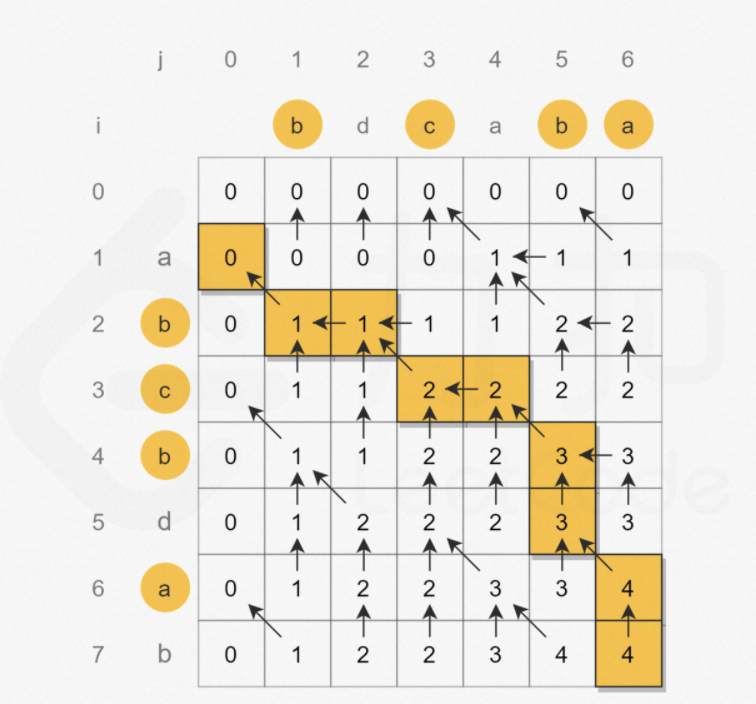
最长公共子序列问题是典型的二维动态规划问题。 假设字符串 text 1 和 text 2 的长度分别为 m 和 n,创建 m+1 行 n+1 列的二维数组 dp,其中 dp[i][j] 表示 text 1 [0:i] text2 [0:j] 的最长公共子序列的长度。
上述表示中,text 1 [0:i] 表示 text 1 的长度为 i 的前缀,text 2 [0:j] 表示 text 2 的长度为 j 的前缀。
考虑动态规划的边界情况:
- 当 i=0 时,text 1 [0:i] 为空,空字符串和任何字符串的最长公共子序列的长度都是 0,因此对任意 0≤j≤n,有 dp[0][j]=0;
- 当 j=0 时,text 2 [0:j] 为空,同理可得,对任意 0≤i≤m,有 dp[i][0]=0。
因此动态规划的边界情况是:当 i=0 或 j=0 时,dp[i][j]=0。
当 i>0 且 j>0 时,考虑 dp[i][j] 的计算:
- 当 text 1 [i−1]=text 2 [j−1] 时,将这两个相同的字符称为公共字符,考虑 text 1 [0:i−1] 和 text 2 [0:j−1] 的最长公共子序列,再增加一个字符(即公共字符)即可得到 text 1 [0:i] 和 text 2 [0:j] 的最长公共子序列,因此 dp[i][j]=dp[i−1][j−1]+1。
- 当 text1[i−1]!=text2[j−1] 时,考虑以下两项:
- 2.1.text1[0:i−1]和 text2[0:j] 的最长公共子序列;
- 2.2.text1[0:i] 和 text2[0:j−1] 的最长公共子序列。
要得到 text 1 [0:i] 和 text 2 [0:j] 的最长公共子序列,应取两项中的长度较大的一项,因此 dp[i][j]=max(dp[i−1][j],dp[i][j−1])。
由此可以得到如下状态转移方程:
最终计算得到 dp[m][n] 即为 text 1和 text2的最长公共子序列的长度。
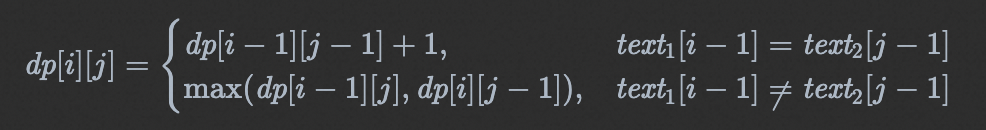
代码实现
Java版本
class Solution {
public int longestCommonSubsequence(String text1, String text2) {
// dp, dp[i][j]表示text1的前i个字符和text2的前j个字符的最长公共子序列
int m = text1.length();
int n = text2.length();
int[][] dp = new int[m + 1][n + 1]; // 创建一个二维数组用于保存最长公共子序列的长度
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (text1.charAt(i - 1) == text2.charAt(j - 1)) {
// 如果当前字符相等,那么最长公共子序列的长度为前一个子序列长度加1
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
// 如果当前字符不相等,那么最长公共子序列的长度为text1减去当前字符和text2的最长公共子序列长度,
// 与text2减去当前字符和text1的最长公共子序列长度的较大值
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[m][n]; // 返回text1和text2的最长公共子序列的长度
}
}
说明:
该代码实现了动态规划算法来求解两个字符串的最长公共子序列。其中,二维数组dp用于保存最长公共子序列的长
度。
通过两个嵌套的循环,遍历所有字符的组合。如果两个字符相等,则当前最长公共子序列的长度为前一个子序列长度加1;如果两个字符不相等,则最长公共子序列的长度为分别减去当前字符后的子序列的最大长度。最终,返回dp[m][n],即text1和text2的最长公共子序列的长度。
希望这个补充的代码说明对您有帮助。
C语言版本
#include <stdio.h>
#include <string.h>
int longestCommonSubsequence(char* text1, char* text2) {
int m = strlen(text1);
int n = strlen(text2);
int dp[m + 1][n + 1];
// 初始化边界条件
for (int i = 0; i <= m; i++) {
for (int j = 0; j <= n; j++) {
if (i == 0 || j == 0) {
dp[i][j] = 0;
}
}
}
// 填充二维数组
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (text1[i - 1] == text2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = (dp[i - 1][j] > dp[i][j - 1]) ? dp[i - 1][j] : dp[i][j - 1];
}
}
}
return dp[m][n];
}
/**
int main() {
char text1[] = "abcde";
char text2[] = "ace";
int result = longestCommonSubsequence(text1, text2);
printf("Longest Common Subsequence: %d\n", result);
return 0;
}
**/
说明:
使用二维数组dp保存最长公共子序列的长度。代码中的longestCommonSubsequence函数接受两个字符串作为参数,并返回它们的最长公共子序列的长度。
首先,对dp数组进行边界条件的初始化,使其第一行和第一列的值为0。
然后,通过两个嵌套的循环遍历所有字符的组合。如果两个字符相等,则当前最长公共子序列的长度为前一个子序列长度加1;如果两个字符不相等,则最长公共子序列的长度为在text1中减去当前字符和在text2中的最长公共子序列长度,与在text2中减去当前字符和在text1中的最长公共子序列长度的较大值。
最后,返回dp[m][n],即text1和text2的最长公共子序列的长度。
在main函数中,给定了两个示例字符串,并打印了最长公共子序列的长度。
Python3版本
def longestCommonSubsequence(text1: str, text2: str) -> int:
m, n = len(text1), len(text2)
dp = [[0] * (n + 1) for _ in range(m + 1)]
# 动态规划填充二维数组
for i in range(1, m + 1):
for j in range(1, n + 1):
if text1[i - 1] == text2[j - 1]:
# 如果字符相等,则当前最长公共子序列的长度为前一个子序列长度加1
dp[i][j] = dp[i - 1][j - 1] + 1
else:
# 如果字符不相等,则最长公共子序列的长度为两个子序列的较大值
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
return dp[m][n]
# 示例用法
#text1 = "abcde"
#text2 = "ace"
#result = longestCommonSubsequence(text1, text2)
#print("Longest Common Subsequence:", result)
说明:
使用二维数组dp保存最长公共子序列的长度。代码中的longestCommonSubsequence函数接受两个字符串作为参数,并返回它们的最长公共子序列的长度。
首先,创建一个大小为(m+1)x(n+1)的二维数组dp,其中m和n分别是两个字符串的长度。
然后,通过两个嵌套的循环遍历所有字符的组合。如果两个字符相等,则当前最长公共子序列的长度为前一个子序列长度加1;如果两个字符不相等,则最长公共子序列的长度为两个子序列的较大值。
最后,返回dp[m][n],即text1和text2的最长公共子序列的长度。
在示例用法中,给定了两个示例字符串,并打印了最长公共子序列的长度。
希望这个带有注释说明的Python代码对您有所帮助。
复杂度分析
- 时间复杂度:O(mn),其中 m 和 n 分别是字符串 text 1 和 text 2 的长度。二维数组 dp 有 m+1 行和 n+1 列,需要对 dp 中的每个元素进行计算。
- 空间复杂度:O(mn),其中 m 和 n 分别是字符串 text 1 和 text 2 的长度。创建了 m+1 行 n+1 列的二维数组 dp。
总结
| 解法 | 时间复杂度 | 空间复杂度 | 备注 |
|---|---|---|---|
| 动态规划 | O(m * n) | O(m * n) | 使用二维数组保存中间计算结果 |
| 递归优化 | O(m * n) | O(m * n) | 使用二维数组保存中间计算结果 |
相似题目
| 相似题目 | 力扣链接 | 难度评级 |
|---|---|---|
| 最长递增子序列 | 链接 | Medium |
| 编辑距离 | 链接 | Hard |
| 最长重复子数组 | 链接 | Medium |
| 最长回文子序列 | 链接 | Medium |
| 最长连续递增序列 | 链接 | Easy |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号