
一图解密AlphaZero
https://blog.csdn.net/ikerpeng/article/details/81387170
AlphaGo Zero主要由三个部分组成:自我博弈(self-play),训练和评估。和AlphaGo 比较,AlphaZero最大的区别在于,并没有采用专家样本进行训练。通过自己和自己玩的方式产生出训练样本,通过产生的样本进行训练;更新的网络和更新前的网络比赛进行评估。
整个系统开始依照当前最好的网络参数进行自我博弈,那么假设进行了10000局的比赛,收集自我博弈过程中所得到的数据。这些数据当中包括:每一次的棋局状态以及在此状态下各个动作的概率(由蒙特卡罗搜索树得到);每一局的获胜得分以及所有棋局结束后的累积得分(胜利的+1分,失败得-1分,最后各自累加得分),得到的数据全部会被放到一个大小为 500000的数据存储当中;然后随机的从这个数据当中采样2048个样本,1000次迭代更新网络。更新之后对网络进行评估:采用当前被更新的网络和未更新的网络进行比赛400局,根据比赛的胜率来决定是否要接受当前更新的网络。如果被更新的网络获得了超过55%的胜率,那么接收该被更新的网络,否则不接受。

AlphaZero的输入的棋局状态到底是什么。
如图所示,是一个大小为19X19X17的数据,表示的是17张大小为19X19(和棋盘的大小相等)的特征图。其中,8张属于白子,8张属于黑子,标记为1的地方表示有子,否则标记为0 。剩下的一张用全1或者是全0表示当前轮到 黑子还是白子了。构成的这个数据表示游戏的状态输入到网络当中进行训练。
初步认识AlphaGo Zero原理
https://zhuanlan.zhihu.com/p/35103060
AlphaGo Zero的核心特点可以表述为:
- 单个神经网络收集棋局特征,在末端分支输出策略和棋局终止时的奖励
- 自我对弈的强化学习的蒙特卡罗树搜索(MCTS)
- 探索与利用的结合(Q+U 置信区间上限)
AlphaGo Zero概述
针对描述当前棋盘的一个状态(位置) ,执行一个由神经网络
指导的MCTS搜索,MCTS搜索输出每一步行为(在某个位置落子)的概率。MCTS搜索给出的概率通常会选择那些比由神经网络
给出的执行某一行为的概率要更强大。从这个角度看,MCTS搜索可以被认为是一个强大的策略优化工具。
通过搜索来进行自我对弈——使用改善了的基于MCTS的策略来指导行为选择,然后使用棋局结果(哪一方获胜,用-1和1分别表示白方和黑方获胜)来作为标签数据——可以被认为是一个强大的策略评估工具。
Alpha Zero算法主体思想就是在策略迭代过程中重复使用上述两个工具:
- 神经网络的参数得以更新,这样可以使得神经网络的输出
:
- 移动概率和获胜奖励更接近与经过改善了的搜索得到的概率以及通过自我对弈得到的棋局结果,后者用
表示。
得到的新参数可以在下一次自我对弈的迭代过程中让搜索变得更加强大。(下图)
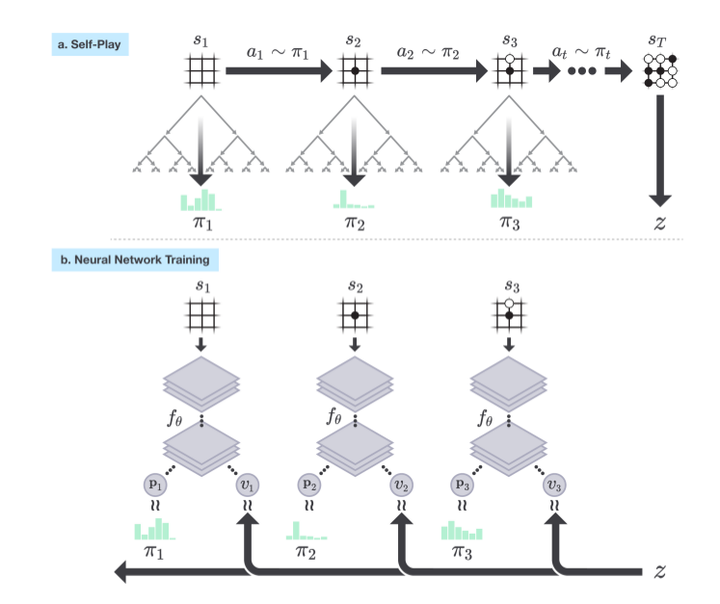
a. 程序自我对弈完成一个棋局产生一个状态序列 ,在
时刻棋局结束,产生了获胜方,用
表示。在其中的每一个时刻
,棋局状态用
表示,会在神经网络
的引导下执行一次MCTS搜索
,通过MCTS搜索计算得到的概率
确定如何行为(在何处落子)
b. 展示的Alpha Zero里神经网络的训练过程。神经网络的输入是某时刻 的棋局状态
外加一些历史和额外信息,输出是一个行为概率向量
和一个标量
,前者表示的在当前棋局状态下采取每种可能落子方式的概率,后者则表示当前棋局状态下当前棋手(还是黑方?)最终获胜还是落败(分别用1和-1表示)。神经网络的训练目标就是要尽可能的缩小两方面的差距:一是搜索得到的概率向量
和网络输出概率向量
差距,二是网络预测的当前棋手的最终结果
和最终游戏赢家(1, -1表示)的差距。网络训练得到的新参数会被用来知道下一轮迭代中自我对弈时的MCTS搜索。

