机器学习:决策树(决策树解决回归问题、决策树算法的局限性)
一、解决回归问题的思路
1)思路对比
- 解决分类问题:根据模型参数训练结束后,对每个“叶子”节点的样本数据进行投票,规定数量最多的样本的类型为该“叶子”的预测类型;
- 解决回归问题:根据模型参数划分结束后,对每个“叶子”节点处 的相应的数据输出值的平均值,作为该“叶子”的预测值;(也就是训练结束后,每个“叶子”处可能有多个数值,取多个数值的平均值作为该“叶子”的预测值,根据特征值预测未知的样本数据时,如果最终计算结果在该“叶子”上,认为该“叶子”的预测值为该特征值对应的样本的数据;)
2)scikit-learn 的决策树算法
- 两个算法的参数相同,参数的功能相同;
- DecisionTreeClassifier():解决分类问题;
- DecisionTreeRegressor():解决回归问题;
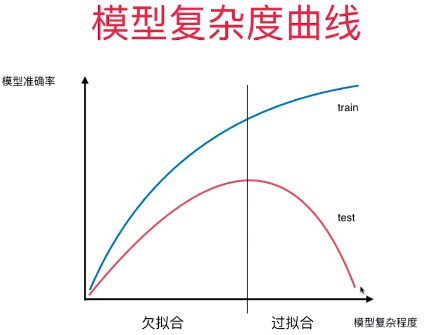
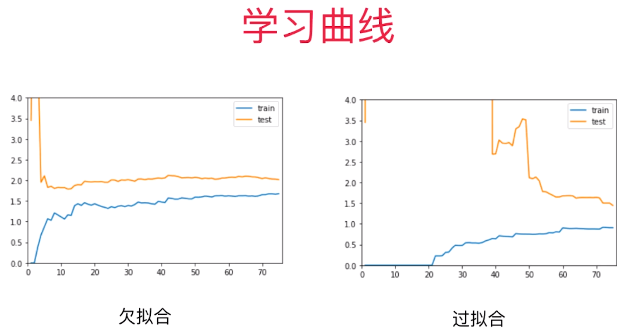
3)判断模型过拟合 / 欠拟合
4)代码
-
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets boston = datasets.load_boston() X = boston.data y = boston.target from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666) from sklearn.tree import DecisionTreeRegressor dt_reg = DecisionTreeRegressor() dt_reg.fit(X_train, y_train) dt_reg.score(X_test, y_test) # 模型对测试数据集上的准确率:0.6946080795352323 dt_reg.score(X_train, y_train) # 模型在训练数据集上的准确率:1.0
- 分析:模型对训练数据集的预测准确度:100%,但在测试数据集上的准确度:69%,模型过拟合;
- 一般过拟合:
- 模型在训练数据集上的表现非常好;
- 模型在测试数据集上的表现不好;
二、决策树算法的局限性
1)局限性一
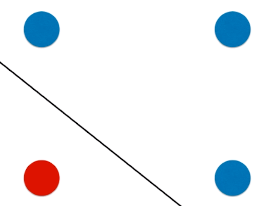
- 决策树模型的决策边界都是与坐标轴平行的,永远不会产生斜线,决策边界可能不准确;
-
情景一:
- 左一图:原始数据分布;
- 中间图:决策树模型得到的决策边界;
- 右一图:为线性模型得到的决策边界;
![]() 、、、
、、、![]() 、、、
、、、 ![]()
 、、、
、、、 、、、
、、、 
-
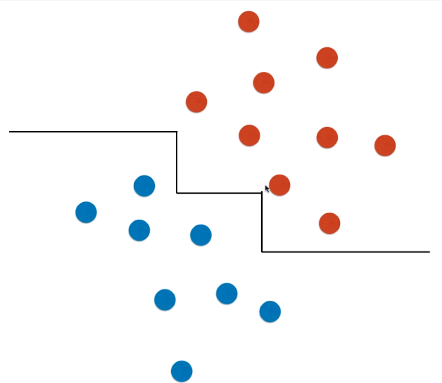
情景二:此种数据分布情况,使用决策树算法不能很好的进行分类,其决策边界有可能是右侧图形态;
 、
、
2)局限性二
- 对个别数据比较敏感:数据集中样本的增减,对模型的训练影响较大;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号