import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
y = boston.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.svm import LinearSVR
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
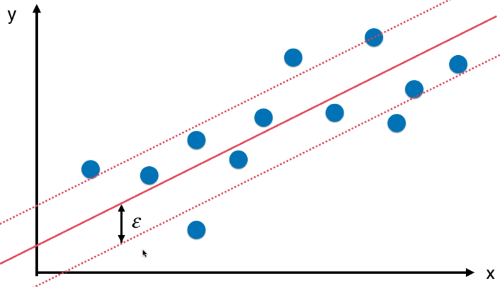
def StandardLinearSVR(epsilon=0.1):
return Pipeline([
('std_scaler', StandardScaler()),
('linearSVR', LinearSVR(epsilon=epsilon))
# 此处使用超参数 C 的默认值;
# 如果使用 SVR(),还需要调节参数 kernel;
])
svr = StandardLinearSVR()
svr.fit(X_train, y_train)
svr.score(X_test, y_test)
# 准确率:0.6353520110647206


 浙公网安备 33010602011771号
浙公网安备 33010602011771号