

机器学习:逻辑回归(使用多项式特征)
一、基础
- 逻辑回归中的决策边界,本质上相当于在特征平面中找一条直线,用这条直线分割所有的样本对应的分类;
- 逻辑回归只可以解决二分类问题(包含线性和非线性问题),因此其决策边界只可以将特征平面分为两部分;
- 问题:使用直线分类太过简单,因为有很多情况样本的分类的决策边界并不是一条直线,如下图;因为这些样本点的分布是非线性的;
- 方案:引入多项式项,改变特征,进而更改样本的分布状态;
二、具体实现
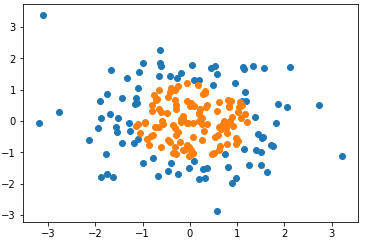
1)模拟数据集
-

import numpy as np import matplotlib.pyplot as plt np.random.seed(666) X = np.random.normal(0, 1, size=(200, 2)) y = np.array(X[:,0]**2 + X[:,1]**2 < 1.5, dtype='int') plt.scatter(X[y==0,0], X[y==0,1]) plt.scatter(X[y==1,0], X[y==1,1]) plt.show()

2)使用逻辑回归算法(不添加多项式项)
-
from playML.LogisticRegression import LogisticRegression log_reg = LogisticRegression() log_reg.fit(X, y) def plot_decision_boundary(model, axis): x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1), np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1) ) X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new) zz = y_predict.reshape(x0.shape) from matplotlib.colors import ListedColormap custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap) plot_decision_boundary(log_reg, axis=[-4, 4, -4, 4]) plt.scatter(X[y==0,0], X[y==0,1]) plt.scatter(X[y==1,0], X[y==1,1]) plt.show()
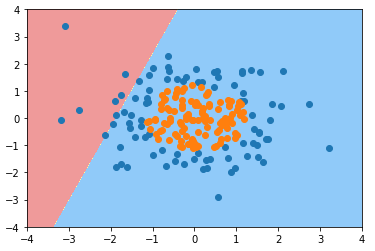
- 问题:决策边界不能反应数据集样本的分布;
3)使用逻辑回归算法(添加多项式项)
- 使用管道(Pipeline)对特征添加多项式项
# 使用管道:Pipeline(list),list 内的每一个元素为为管道的一步,每一步是一个元组, # 元组的第一个元素是一个字符串,是一个实例对象,描述这一步的内容或功能,第二个元素是一个类的对象 from sklearn.pipeline import Pipeline from sklearn.preprocessing import PolynomialFeatures from sklearn.preprocessing import StandardScaler def PolynomialLogisticRegression(degree): return Pipeline([ # 管道第一步:给样本特征添加多形式项; ('poly', PolynomialFeatures(degree=degree)), # 管道第二步:数据归一化处理; ('std_scaler', StandardScaler()), ('log_reg', LogisticRegression()) ]) poly_log_reg = PolynomialLogisticRegression(degree=2) poly_log_reg.fit(X, y) plot_decision_boundary(poly_log_reg, axis=[-4, 4, -4, 4]) plt.scatter(X[y==0,0], X[y==0,1]) plt.scatter(X[y==1,0], X[y==1,1]) plt.show()
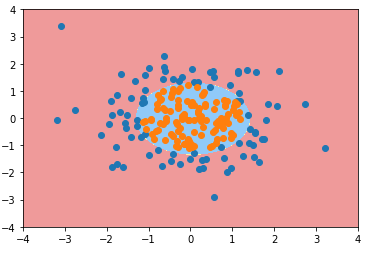
三、其它
1)管道(Pipeline)
- Pipeline(list):list 内的每一个元素为为管道的一步,每一步是一个元组,
- 元组的第一个元素是一个字符串,是一个实例对象,描述这一步的内容或功能,第二个元素是一个类的对象;
- 管道第一步:给样本特征添加多形式项;
- 管道第二步:数据归一化处理;
2)scikit-learn 库的标准
- 管道中使用的逻辑回归算法模型:LogisticRegression() 是自己所写的算法,之所以能直接传入管道使用,因为自己所写的算法遵循了 scikit-learn 的标准;
- scikit-learn 中每一个机器学习算法的标准:__init__()函数、fit()函数、predict()函、score()函数等;
- 如果在scikit-learn 的模块中使用了其它算法/模块,只要这些其它的模块遵循了 scikit-learn 中算法的标准,则 scikit-learn 的模块就认为这些模块也是 scikit-learn 本身的模块;
- 也就是说,如果其它算法想和scikit-learn中的模块衔接使用,该算法就要遵循scikit-learn中机器学习算法的标准;
3)其它
- 实习的应用中,需要对 degree 参数进行调整,选取最佳的参数;
- scikit-learn 建议使用逻辑回归算法时都进行模型正则化;
分类:
机器学习算法


· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 字符编码:从基础到乱码解决