

机器学习:学习曲线
一、基础理解
- 学习曲线作用:
- 查看模型的学习效果;
- 通过学习曲线可以清晰的看出模型对数据的过拟合和欠拟合;
- 学习曲线:随着训练样本的逐渐增多,算法训练出的模型的表现能力;
- 表现能力:也就是模型的预测准确率,使用均方误差表示;学习率上体现了模型相对于训练集和测试集两类数据的均方误差。
-
具体的操作:
- len(X_train) 个训练样本,训练出 len(X_train) 个模型,第一次使用一个样本训练出第一个模型,第二次使用两个样本训练出第二个模型,... ,第 len(X_train) 次使用 len(X_train) 个样本训练出最后一个模型;
- 每个模型对于训练这个模型所使用的部分训练数据集的预测值:y_train_predict = 模型.predict(X_train[ : i ]);
- 每个模型对于训练这个模型所使用的部分训练数据集的均方误差:mean_squared_error(y_train[ : i ], y_train_predict);
- 每个模型对于整个测试数据集的预测值:y_test_predict = 模型.predict(X_test)
- 每个模型对于整个测试数据集的预测的均方误差:mean_squared_error(y_test, y_test_predict);
- 绘制每次训练模型所用的样本数量与该模型对应的部分训练数据集的均方误差的平方根的关系曲线:plt.plot([i for i in range(1, len(X_train)+1)],np.sqrt(train_score), label="train")
- 绘制每次训练模型所用的样本数量与该模型对应的测试数据集的预测的均方误差的关系曲线:plt.plot([i for i in range(1, len(X_train)+1)],np.sqrt(test_score), label="test")
二、实例
1)模拟数据集
-
数据集
import numpy as np import matplotlib.pyplot as plt np.random.seed(666) x = np.random.uniform(-3, 3, size=100) X = x.reshape(-1, 1) y = 0.5 * x**2 + x + 2. + np.random.normal(0, 1, size=100)
-
绘制数据集
plt.scatter(x, y) plt.show()
-
分割数据集
from sklearn.model_selection import train_test_split # random_state=10:随机种子; X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=10)
2)使用线性回归拟合数据集并绘制学习曲线
-
拟合

from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error # 存储每一次训练的模型的均方误差 train_score = [] test_score = [] # for 循环:进行 75 次模型训练,每次训练出 1 个模型,第一次给 1 个数据,第二次给 2 个数据,... ,最后一次给 75 个数据 for i in range(1, 76): lin_reg = LinearRegression() lin_reg.fit(X_train[:i], y_train[:i]) # LinearRegression().fit(X_train[:i], y_train[:i]) # 查看模型的预测情况:两种,模型基于训练数据集预测的情况(可以理解为模型拟合训练数据集的情况),模型基于测试数据集预测的情况 # 此处使用 lin_reg.predict(X_train[:i]),为训练模型的全部数据集 y_train_predict = lin_reg.predict(X_train[:i]) train_score.append(mean_squared_error(y_train[:i], y_train_predict)) y_test_predict = lin_reg.predict(X_test) test_score.append(mean_squared_error(y_test, y_test_predict))
-
绘制
# np.sqrt(train_score):将列表 train_score 中的数开平方 plt.plot([i for i in range(1, 76)], np.sqrt(train_score), label='train') plt.plot([i for i in range(1, 76)], np.sqrt(test_score), label='test') # plt.legend():显示图例(如图形的 label); plt.legend() plt.show()
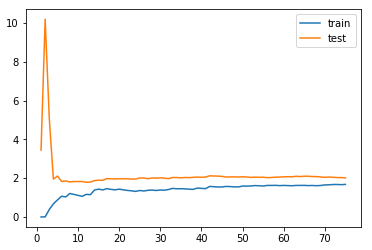

-
分析:随着数据集的增大,所训练出的模型
- 相对于训练数据集的均方误差在逐渐增大:因为随着数据集的增大,样本点的增多,模型越难拟合住所有的数据,相应的均方误差会逐渐的累积,越来越大,但随着训练数据集的增大,均方差的逐渐累积量越来越小,模型相应的会越来越稳定;
- 相对于测试数据集的测试误差逐渐减小,当数据量增大到一定程度,测试误差趋于相对稳定;
- 最终的训练误差和测试误差几乎接近,相当于一个级别,不过测试误差比训练误差相对较大一点,因为训练数据集训练出的模型对训练数据集拟合的程度较好,相对的模型对应训练数据集的均方误差相对较小;
3)将绘制学习曲线的方法封装成一个函数
-
具体代码
def plot_learning_curve(algo, X_train, X_test, y_train, y_test): """绘制学习曲线:只需要传入算法(或实例对象)、X_train、X_test、y_train、y_test""" """当使用该函数时传入算法,该算法的变量要进行实例化,如:PolynomialRegression(degree=2),变量 degree 要进行实例化""" train_score = [] test_score = [] for i in range(1, len(X_train)+1): algo.fit(X_train[:i], y_train[:i]) y_train_predict = algo.predict(X_train[:i]) train_score.append(mean_squared_error(y_train[:i], y_train_predict)) y_test_predict = algo.predict(X_test) test_score.append(mean_squared_error(y_test, y_test_predict)) plt.plot([i for i in range(1, len(X_train)+1)], np.sqrt(train_score), label="train") plt.plot([i for i in range(1, len(X_train)+1)], np.sqrt(test_score), label="test") plt.legend() plt.axis([0, len(X_train)+1, 0, 4]) plt.show()
- 当使用该函数时传入算法,该算法的变量要进行实例化,如:
plot_learning_curve(PolynomialRegression(degree=2), X_train, X_test, y_train, y_test) - 可以直接传承实例化后的变量,如:lin_reg = LinearRegression(),
plot_learning_curve(lin_reg, X_train, X_test, y_train, y_test)
-
使用 plot_squared_error() 函数,绘制线性回归模型的学习曲线
plot_learning_curve(LinearRegression(), X_train, X_test, y_train, y_test)
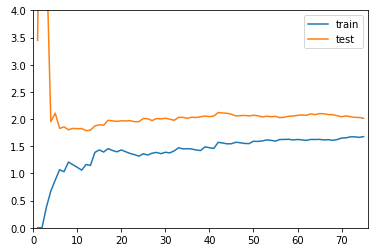
-
使用 plot_squared_error() 函数,绘制线性回归模型的学习曲线
from sklearn.pipeline import Pipeline from sklearn.preprocessing import PolynomialFeatures from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error def PolynomialRegression(degree): return Pipeline([ ('poly', PolynomialFeatures(degree=degree)), ('std_scaler', StandardScaler()), ('lin_reg', LinearRegression()) ])
- degree = 2
poly2_reg = PolynomialRegression(degree=2) plot_learning_curve(poly2_reg, X_train, X_test, y_train, y_test)
- degree = 20
plot_learning_curve(PolynomialRegression(degree=20), X_train, X_test, y_train, y_test)
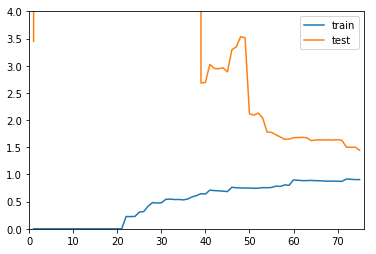
-
分析(一):对比 degree=2 和线性回归学习曲线
-

- 对于欠拟合情况,和最佳的情况相比较,相对的 train 和 test 两根曲线趋于稳定的位置,比最佳的两个曲线趋于稳定的位置较高:说明,无论对于训练数据集还是测试数据集,相应的误差都比较大,这是因为本身模型选的不正确,即使在训练数据集上,误差也比较大;
-
分析(二):对比 degree=2 和 degree=20 两个学习曲线
-

- 对于过拟合情况,在训练数据集上,相应的误差和最佳时的误差差不多,甚至当 degree 取值更大时,过拟合的误差比最佳时的误差小;
- 对于过拟合情况,测试数据集的误差相比较大,并且从图上看出,测试数据集的误差曲线距离训练数据集的误差曲线较远:说明,此时模型的泛化能力不够好,对于新的数据预测误差较大;


· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 字符编码:从基础到乱码解决