SQL:分析函数、排名函数、聚合函数配合窗口函数 OVER 的用法
参考 1:Microsoft 中的 SQL Server 文档(分析函数、排名行数、聚合函数、OVER窗口函数)
参考 2:SQL Server 分析函数和排名函数 博主:悦光阴
- 分析函数基于分组,计算分组内数据的聚合值,经常会和窗口函数OVER()一起使用,使用分析函数可以很方便地计算同比和环比,获得中位数,获得分组的最大值和最小值。
- 分析函数和聚合函数不同,不需要GROUP BY子句,对SELECT子句的结果集,通过OVER()子句分组;
一,分析函数
- 分析函数通常和 OVER() 函数搭配使用,SQL Server 中共有4类分析函数。
- 注意:distinct 子句的执行顺序是在分析函数之后。
1,分布函数:CUME_DIST、PERCENT_RANK
- 功能:计算某个值在某个值组内的累积分布;换言之,
CUME_DIST计算某指定值在一组值中的相对位置。
- CUME_DIST 计算的逻辑是:小于等于当前值的行数 / 分组内总行数;
- PERCENT_RANK 计算的逻辑是:(分组内当前行的 RANK 值-1)/ (分组内总行数-1),排名值是 RANK() 函数排序的结果值;
-
示例:
-
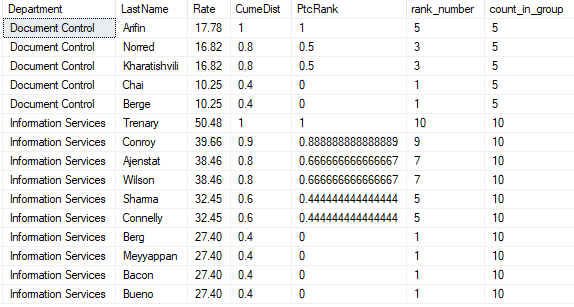
select Department ,LastName ,Rate ,cume_dist() over(partition by Department order by Rate) as CumeDist ,percent_rank() over(partition by Department order by Rate) as PtcRank ,rank() over(partition by Department order by Rate asc) as rank_number ,count(0) over(partition by Department) as count_in_group from #data order by DepartMent ,Rate desc
![]()
-
2,分布函数:PERCENTILE_CONT、PERCENTILE_DISC
-
功能:
- 都是为了计算百分位的数值,比如计算在某个百分位时某个栏位的数值是多少;
- 如,20% —— 一组数据中,分布位置在 20% 处的数值、50% —— 分布位置在 50% 处的数值,也就是中位数;
-
语法:
-
PERCENTILE_CONT ( numeric_literal ) WITHIN GROUP ( ORDER BY order_by_expression [ ASC | DESC ] ) OVER ( [ <partition_by_clause> ] ) PERCENTILE_DISC ( numeric_literal ) WITHIN GROUP ( ORDER BY order_by_expression [ ASC | DESC ] ) OVER ( [ <partition_by_clause> ] )
-
-
区别:
- 这两个函数的区别是前者是连续型,后者是离散型。
- CONT代表continuous,连续值,DISC代表discrete,离散值。
- PERCENTILE_CONT是连续型,意味它考虑的是区间,所以值是绝对的中间值;
- PERCENTILE_DISC是离散型,所以它更多考虑向上或者向下取舍,而不会考虑区间;
-
示例:
-
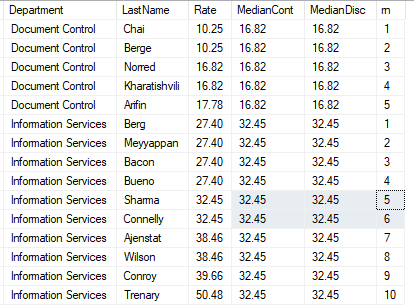
select Department ,LastName ,Rate ,PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY Rate) OVER (PARTITION BY Department) AS MedianCont ,PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY Rate) OVER (PARTITION BY Department) AS MedianDisc ,row_number() over(partition by Department order by Rate) as rn from #data order by DepartMent ,Rate asc
![]()
-
3,偏移函数:LAG、LEAD
-
功能:
- 对某列数据进行偏移;
-
区别:
- LAG:向下偏移 —— 如果偏移 n 行数据(即 offset=n),旧列中的第一行数据,在新列中为第 n+1 行数据;
- LEAD:向上偏移 —— 如果偏移 n 行数据(即 offset=n),旧列中的第一行数据,在新列中为第 n+1 行数据,
-
语法:
-
LAG (scalar_expression [,offset] [,default]) OVER ( [ partition_by_clause ] order_by_clause ) LEAD ( scalar_expression [ ,offset ] , [ default ] ) OVER ( [ partition_by_clause ] order_by_clause )
- sclar_expression
- 偏移的对象,即 旧列;
- offset
- 偏移量;
- 如,offset=n,表示偏移了 n 行数据;
- 默认值是1,必须是正整数;
- 偏移量;
- default
- 偏移后的偏移区的取值;
- 如, LAG 偏移了 n 行,则新列中的前 n 行的数据即为 default;
- 如果未指定默认值,则返回NULL;
- default 可以是列,子查询或其他表达式,但数据类型必须跟 sclar_expression 类型兼容;
- 偏移后的偏移区的取值;
-
-
示例:
- 结果日期,这两个函数特别适合用于计算同比和环比;
-
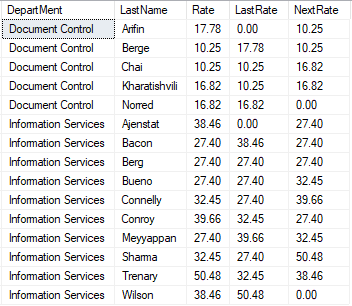
select DepartMent ,LastName ,Rate ,lag(Rate,1,0) over(partition by Department order by LastName) as LastRate ,lead(Rate,1,0) over(partition by Department order by LastName) as NextRate from #data order by Department ,LastName
![]()
-
理解:
- scalar_expression = Rate:对 Rate 列的数据进行偏移;
- offset=1:偏移量设置为 1;(即偏移一行数据)
- default=0:偏移区的数据设置为 0;
- 如新列 LastRate 的第一个分组的第 1 行数据;(向下偏移 1 行数据)
- 如新列 NextRate 的第一个分组的第 5 行数据;(向上偏移 1 行数据)
4,偏移函数:FIRST_VALUE、LAST_VALUE、NTH_VALUE
-
功能:
- FIRST_VALUE:返回 scalar_expression 列中,分组中的第一行的数据;
- LAST_VALUE:返回 scalar_expression 列中,分组中的最后一行的数据;
- NTH_VALUE:返回 scalar_expression 列中,每个分组的偏移量;(即 offset 值)
-
语法:
-
LAST_VALUE ( [scalar_expression ) OVER ( [ partition_by_clause ] order_by_clause rows_range_clause ) FIRST_VALUE ( [scalar_expression ] ) OVER ( [ partition_by_clause ] order_by_clause [ rows_range_clause ] )
- scalar_expression —— 目标列:如果对该列进行了分组和排序,则返回该列中的每个分组中的第一行 / 最后一行的数据;
-
-
示例:
-
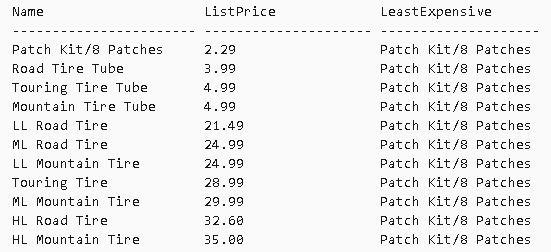
USE AdventureWorks2012; GO SELECT Name, ListPrice, FIRST_VALUE(Name) OVER (ORDER BY ListPrice ASC) AS LeastExpensive FROM Production.Product WHERE ProductSubcategoryID = 37;
![]()
- 理解:返回结果集中 Name 列中的第一行数据;
-
二,排名函数
- TSQL共有4个排名函数:RANK、NTILE、DENSE_RANK、ROW_NUMBER,和 OVER() 函数搭配使用,按照特定的顺序排名。
1,ROW_NUMBER
- 这个函数赋予唯一的连续位次;
- 如,有 3 条排在第1位时,排序为:1,2,3,4······
-
ROW_NUMBER ( ) OVER ( [ PARTITION_BY_clause ] order_by_clause )
-
分组内序列的最大值就是该分组内的行的数目;
2,RANK
- 功能:在计算排序时,若存在相同位次,会跳过之后的位次;
- 如,有3条排在第1位时,排序为:1,1,1,4······
-
RANK ( ) OVER ( [ partition_by_clause ] order_by_clause )
3,DENSE_RANK
- 功能: 在计算排序时,若存在相同位次,不会跳过之后的位次。
- 如,有3条排在第1位时,排序为:1,1,1,2······
-
DENSE_RANK ( ) OVER ( [ <partition_by_clause> ] < order_by_clause > )
4,NTILE
- 功能:对每个分组的所有数据进行分块标记,每个标记就是该行数据所在第几个数据块;
- 如,integer_expression=3:把一个分组的数据分成 3 分;(则每个数据块的行数 = 分组数据总行数 / 3,如果不能整除,最后一个数据块的数据记录最少)
-
语法:
-
NTILE (integer_expression) OVER ( [ <partition_by_clause> ] < order_by_clause > )
-
-
示例
-
-
select Department, LastName, Rate, row_number() over(order by Rate) as [row number], rank() over(order by rate) as rate_rank, dense_rank() over(order by rate) as rate_dense_rank, ntile(4) over(order by rate) as quartile_by_rate from test_data
![]()
-

三、聚合函数 配合 OVER 函数
- 一般配合 OVER 函数使用的聚合函数:SUM、COUNT、AVG、MAX、MIN;
-
功能:
- SUM、AVG:返回累积计算结果;
- 如,第 n 行的数据,是从前 n 行数据中计算得到;
- COUNT、MAX、MIN:返回分组中的行数、最大值、最小值,一个分组返回一行数;
- SUM、AVG:返回累积计算结果;
-
语法:
- 对一列的分组进行计算
-
<窗口函数> OVER([pattition by col_a] ORDER BY col_b)
-
- 不分组,直接对某列进行计算
-
<窗口函数(col_a)> OVER(ORDER BY col_b)
-
- 对一列的分组进行计算
-
示例:
-
SUM:累积求和
- 第 n 行数据为前 n 行数据的总和;
-
select product_id, product_name, sale_price, sum(sale_price) over (order by product_id) as current_sum from Product;
![]()
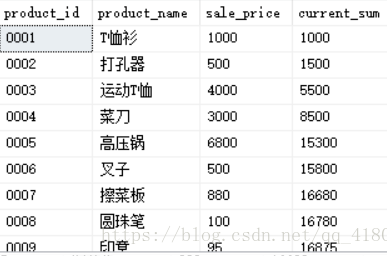
-
AVG:累积求平均
- 第 n 行的数据为前 n 行数据的平均数;
-
select product_id, product_name, sale_price, avg(sale_price) over (order by product_id) as current_sum from Product;
![]()

-
AVG:移动平均(一)
- 计算前 n 行 + 改行数据的平均值;
- 如,n=2:计算相邻 3 行数据,即 (前 2 行 + 本身行数据) / 3;
- 如,当 n=2 时,第 10 行的数据 = (第8行 + 第9行 + 第10行) / 3
- 如,n=2:计算相邻 3 行数据,即 (前 2 行 + 本身行数据) / 3;
-
语法:
-
<聚合函数> OVER([PARTITION BY col_a] ORDER BY col_b ROWS n PRECEDING)
-
-
示例:
-
SELECT product_id, product_name, sale_price, AVG (sale_price) OVER (ORDER BY product_id ROWS 2 PRECEDING) AS moving_avg FROM Product;
![]()
- n = 2:计算前两行+本行数据的平均值;
- 第 3 行:1833 = (1000+500+4000) / 3
- 第 4 行:2500 = (500+4000+3000) / 3
- 第 5 行:4600 = (4000+3000+6800) / 3
-
- 计算前 n 行 + 改行数据的平均值;

-
AVG:移动平均(二)
- 功能:(计算上一行 + 下一行 + 该行) / 3;
-
语法及示例:
-
SELECT product_id, product_name, sale_price, AVG(sale_price) OVER (ORDER BY product_id ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS moving_avg
--使用between规划范围,语句意思为rows 1 preceding 到 rows 1 following FROM Product;![]()
- 4600 = (4000+3000+6800) / 3
-


 浙公网安备 33010602011771号
浙公网安备 33010602011771号