浅析 Jetty 中的线程优化思路
作者:vivo 互联网服务器团队- Wang Ke
本文介绍了 Jetty 中 ManagedSelector 和 ExecutionStrategy 的设计实现,通过与原生 select 调用的对比揭示了 Jetty 的线程优化思路。Jetty 设计了一个自适应的线程执行策略(EatWhatYouKill),在不出现线程饥饿的情况下尽量用同一个线程侦测 I/O 事件和处理 I/O 事件,充分利用了 CPU 缓存并减少了线程切换的开销。这种优化思路对于有大量 I/O 操作场景下的性能优化具有一定的借鉴意义。
一、什么是 Jetty
Jetty 跟 Tomcat 一样是一种 Web 容器,它的总体架构设计如下:
Jetty 总体上由一系列 Connector、一系列 Handler 和一个 ThreadPool组成。
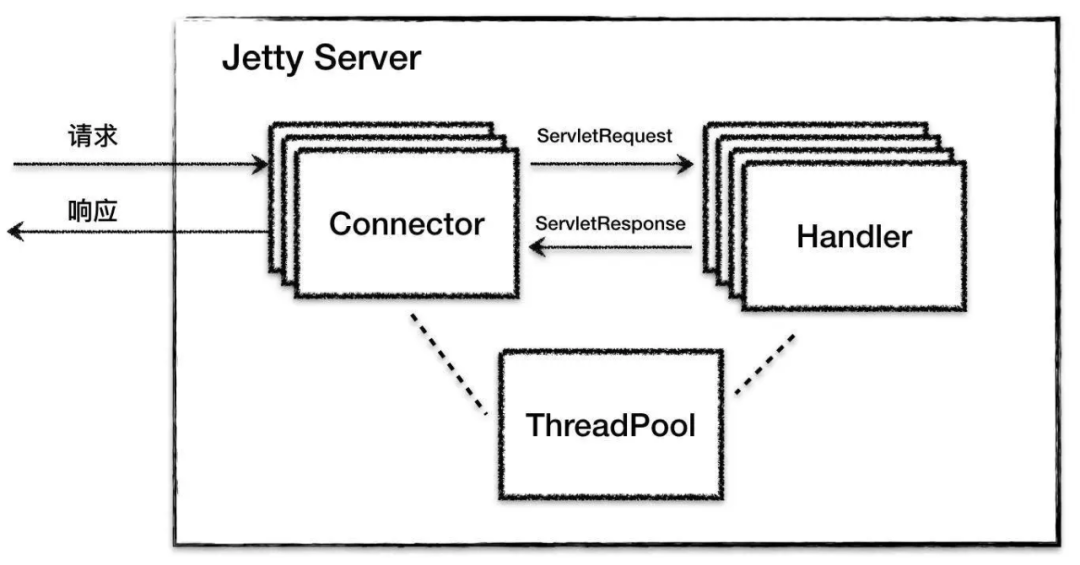
Connector 也就是 Jetty 的连接器组件,相比较 Tomcat 的连接器,Jetty 的连接器在设计上有自己的特点。
Jetty 的 Connector 支持 NIO 通信模型,NIO 模型中的主角是 Selector,Jetty 在 Java 原生 Selector 的基础上封装了自己的 Selector:ManagedSelector。
二、Jetty 中的 Selector 交互
2.1 传统的 Selector 实现
常规的 NIO 编程思路是将 I/O 事件的侦测和请求的处理分别用不同的线程处理。
具体过程是:
- 启动一个线程;
- 在一个死循环里不断地调用 select 方法,检测 Channel 的 I/O 状态;
- 一旦 I/O 事件到达,就把该 I/O 事件以及一些数据包装成一个 Runnable;
- 将 Runnable 放到新线程中去处理。
这个过程有两个线程在干活:一个是 I/O 事件检测线程、一个是 I/O 事件处理线程。
这两个线程是"生产者"和"消费者"的关系。
这样设计的好处:
将两个工作用不同的线程处理,好处是它们互不干扰和阻塞对方。
这样设计的缺陷:
当 Selector 检测读就绪事件时,数据已经被拷贝到内核中的缓存了,同时 CPU 的缓存中也有这些数据了。
这时当应用程序去读这些数据时,如果用另一个线程去读,很有可能这个读线程使用另一个 CPU 核,而不是之前那个检测数据就绪的 CPU 核。
这样 CPU 缓存中的数据就用不上了,并且线程切换也需要开销。
2.2 Jetty 中的 ManagedSelector 实现
Jetty 的 Connector 将 I/O 事件的生产和消费放到同一个线程处理。
如果执行过程中线程不阻塞,操作系统会用同一个 CPU 核来执行这两个任务,这样既能充分利用 CPU 缓存,又可以减少线程上下文切换的开销。
ManagedSelector 本质上是一个 Selector,负责 I/O 事件的检测和分发。
为了方便使用,Jetty 在 Java 原生 Selector 的基础上做了一些扩展,它的成员变量如下:
public class ManagedSelector extends ContainerLifeCycle implements Dumpable
{
// 原子变量,表明当前的ManagedSelector是否已经启动
private final AtomicBoolean _started = new AtomicBoolean(false);
// 表明是否阻塞在select调用上
private boolean _selecting = false;
// 管理器的引用,SelectorManager管理若干ManagedSelector的生命周期
private final SelectorManager _selectorManager;
// ManagedSelector的id
private final int _id;
// 关键的执行策略,生产者和消费者是否在同一个线程处理由它决定
private final ExecutionStrategy _strategy;
// Java原生的Selector
private Selector _selector;
// "Selector更新任务"队列
private Deque<SelectorUpdate> _updates = new ArrayDeque<>();
private Deque<SelectorUpdate> _updateable = new ArrayDeque<>();
...
}2.2.1 SelectorUpdate 接口
为什么需要一个"Selector更新任务"队列呢?
对于 Selector 的用户来说,我们对 Selector 的操作无非是将 Channel 注册到 Selector 或者告诉 Selector 我对什么 I/O 事件感兴趣。
这些操作其实就是对 Selector 状态的更新,Jetty 把这些操作抽象成 SelectorUpdate 接口。
/**
* A selector update to be done when the selector has been woken.
*/
public interface SelectorUpdate
{
void update(Selector selector);
}这意味着不能直接操作 ManagedSelector 中的 Selector,而是需要向 ManagedSelector 提交一个任务类。
这个类需要实现 SelectorUpdate 接口的 update 方法,在 update 方法中定义要对 ManagedSelector 做的操作。
比如 Connector 中的 Endpoint 组件对读就绪事件感兴趣。
它就向 ManagedSelector 提交了一个内部任务类 ManagedSelector.SelectorUpdate:
_selector.submit(_updateKeyAction);这个 _updateKeyAction 就是一个 SelectorUpdate 实例,它的 update 方法实现如下:
private final ManagedSelector.SelectorUpdate _updateKeyAction = new ManagedSelector.SelectorUpdate()
{
@Override
public void update(Selector selector)
{
// 这里的updateKey其实就是调用了SelectionKey.interestOps(OP_READ);
updateKey();
}
};在 update 方法里,调用了 SelectionKey 类的 interestOps 方法,传入的参数是 OP_READ,意思是我对这个 Channel 上的读就绪事件感兴趣。
2.2.2 Selectable 接口
上面有了 update 方法,那谁来执行这些 update 呢,答案是 ManagedSelector 自己。
它在一个死循环里拉取这些 SelectorUpdate 任务逐个执行。
I/O 事件到达时,ManagedSelector 通过一个任务类接口(Selectable 接口)来确定由哪个函数处理这个事件。
public interface Selectable
{
// 当某一个Channel的I/O事件就绪后,ManagedSelector会调用的回调函数
Runnable onSelected();
// 当所有事件处理完了之后ManagedSelector会调的回调函数
void updateKey();
}Selectable 接口的 onSelected() 方法返回一个 Runnable,这个 Runnable 就是 I/O 事件就绪时相应的处理逻辑。
ManagedSelector 在检测到某个 Channel 上的 I/O 事件就绪时,ManagedSelector 调用这个 Channel 所绑定的类的 onSelected 方法来拿到一个 Runnable。
然后把 Runnable 扔给线程池去执行。
三、Jetty 的线程优化思路
3.1 Jetty 中的 ExecutionStrategy 实现
前面介绍了 ManagedSelector 的使用交互:
-
如何注册 Channel 以及 I/O 事件
-
提供什么样的处理类来处理 I/O 事件
那么 ManagedSelector 如何统一管理和维护用户注册的 Channel 集合呢,答案是 ExecutionStrategy 接口。
这个接口将具体任务的生产委托给内部接口 Producer,而在自己的 produce 方法里实现具体执行逻辑。
这个 Runnable 的任务可以由当前线程执行,也可以放到新线程中执行。
public interface ExecutionStrategy
{
// 只在HTTP2中用到的一个方法,暂时忽略
public void dispatch();
// 实现具体执行策略,任务生产出来后可能由当前线程执行,也可能由新线程来执行
public void produce();
// 任务的生产委托给Producer内部接口
public interface Producer
{
// 生产一个Runnable(任务)
Runnable produce();
}
}实现 Produce 接口生产任务,一旦任务生产出来,ExecutionStrategy 会负责执行这个任务。
private class SelectorProducer implements ExecutionStrategy.Producer
{
private Set<SelectionKey> _keys = Collections.emptySet();
private Iterator<SelectionKey> _cursor = Collections.emptyIterator();
@Override
public Runnable produce()
{
while (true)
{
// 如果Channel集合中有I/O事件就绪,调用前面提到的Selectable接口获取Runnable,直接返回给ExecutionStrategy去处理
Runnable task = processSelected();
if (task != null)
return task;
// 如果没有I/O事件就绪,就干点杂活,看看有没有客户提交了更新Selector的任务,就是上面提到的SelectorUpdate任务类。
processUpdates();
updateKeys();
// 继续执行select方法,侦测I/O就绪事件
if (!select())
return null;
}
}
}SelectorProducer 是 ManagedSelector 的内部类。
SelectorProducer 实现了 ExecutionStrategy 中的 Producer 接口中的 produce 方法,需要向 ExecutionStrategy 返回一个 Runnable。
在 produce 方法中 SelectorProducer 主要干了三件事:
-
如果 Channel 集合中有 I/O 事件就绪,调用前面提到的 Selectable 接口获取 Runnable,直接返回给 ExecutionStrategy 处理。
-
如果没有 I/O 事件就绪,就干点杂活,看看有没有客户提交了更新 Selector 上事件注册的任务,也就是上面提到的 SelectorUpdate 任务类。
-
干完杂活继续执行 select 方法,侦测 I/O 就绪事件。
3.2 Jetty 的线程执行策略
3.2.1 ProduceConsume(PC) 线程执行策略
任务生产者自己依次生产和执行任务,对应到 NIO 通信模型就是用一个线程来侦测和处理一个 ManagedSelector 上的所有的 I/O 事件。
后面的 I/O 事件要等待前面的 I/O 事件处理完,效率明显不高。

图中,绿色代表生产一个任务,蓝色代表执行这个任务,下同。
3.2.2 ProduceExecuteConsume(PEC) 线程执行策略
任务生产者开启新线程来执行任务,这是典型的 I/O 事件侦测和处理用不同的线程来处理。
缺点是不能利用 CPU 缓存,并且线程切换成本高。
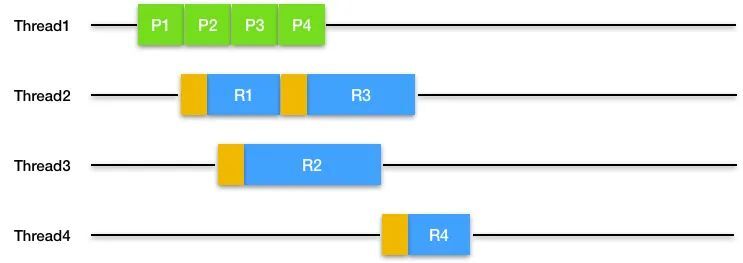
图中,棕色代表线程切换,下同。
3.2.3 ExecuteProduceConsume(EPC) 线程执行策略
任务生产者自己运行任务,这种方式可能会新建一个新的线程来继续生产和执行任务。
它的优点是能利用 CPU 缓存,但是潜在的问题是如果处理 I/O 事件的业务代码执行时间过长,会导致线程大量阻塞和线程饥饿。
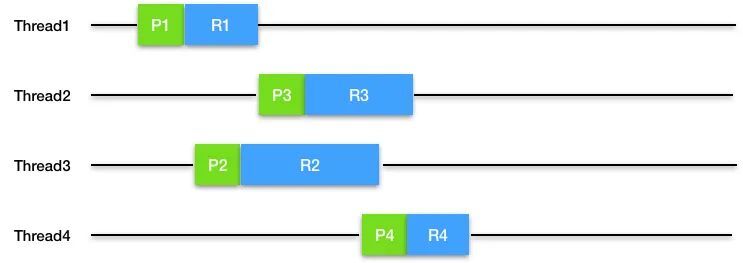
3.2.4 EatWhatYouKill(EWYK) 改良线程执行策略
这是 Jetty 对 ExecuteProduceConsume 策略的改良,在线程池线程充足的情况下等同于 ExecuteProduceConsume;
当系统比较忙线程不够时,切换成 ProduceExecuteConsume 策略。
这么做的原因是:
ExecuteProduceConsume 是在同一线程执行 I/O 事件的生产和消费,它使用的线程来自 Jetty 全局的线程池,这些线程有可能被业务代码阻塞,如果阻塞的多了,全局线程池中线程自然就不够用了,最坏的情况是连 I/O 事件的侦测都没有线程可用了,会导致 Connector 拒绝浏览器请求。
于是 Jetty 做了一个优化:
在低线程情况下,就执行 ProduceExecuteConsume 策略,I/O 侦测用专门的线程处理, I/O 事件的处理扔给线程池处理,其实就是放到线程池的队列里慢慢处理。
四、总结
本文基于 Jetty-9 介绍了 ManagedSelector 和 ExecutionStrategy 的设计实现,介绍了 PC、PEC、EPC 三种线程执行策略的差异,从 Jetty 对线程执行策略的改良操作中可以看出,Jetty 的线程执行策略会优先使用 EPC 使得生产和消费任务能够在同一个线程上运行,这样做可以充分利用热缓存,避免调度延迟。
这给我们做性能优化也提供了一些思路:
-
在保证不发生线程饥饿的情况下,尽量使用同一个线程生产和消费可以充分利用 CPU 缓存,并减少线程切换的开销。
-
根据实际场景选择最适合的执行策略,通过组合多个子策略也可以扬长避短达到1+1>2的效果。
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号