Percolator模型及其在TiKV中的实现
一、背景
Percolator是Google在2010年发表的论文《Large-scale Incremental Processing Using Distributed Transactions and Notifications》中提出的一种分布式事务解决方案。在论文中该方案是用来解决搜索引擎的增量索引问题的。
Percolator支持ACID语义,并实现了Snapshot Isolation的事务隔离级别,所以可以将其看作是一种通用的分布式事务解决方案。Percolator基于google自己的Bigtable来实现的,其本质上是一个二阶段提交协议,利用了Bigtable的行事务。
二、架构
Percolator 包含三个组件:
-
Client:Client 是整个协议的控制中心,是两阶段提交的协调者(Coordinator);
-
TSO:一个全局的授时服务,提供全局唯一且递增的时间戳 (timetamp);
-
Bigtable:实际持久化数据的分布式存储;
2.1. Client
二阶段提交算法中有两种角色,协调者和参入者。在Percolator中,Client充当协调者的角色,负责发起和提交事务。
2.2. Timestamp Oracle (TSO)
Percolator依赖于TSO提供一个全局唯一且递增的时间戳,来实现Snapshot Isolation。在事务的开始和提交的时候,Client都需要从TSO拿到一个时间戳。
2.3 Bigtable
Bigtable从数据模型上可以理解为一个multi-demensional有序Map,键值对形式如下:
(row:string, column:string,timestamp:int64)->string
key由三元组 (row, column, timestamp) 组成,value可以是认为byte数组。
在Bigtable中,一行 (row) 可以包含多个 (column),Bigtable提供了单行的跨多列的事务能力,Percolator利用这个特性来保证对同一个row的多个column的操作是原子性的。Percolator的元数据存储在特殊的column中,如下:

(图片来自:https://research.google)
我们主要需要关注三个column,c:lock , c:write , c:data :
-
c:lock ,在事务Prewrite的时候,会在此column中插入一条记录
-
**c:write **,在事务commit的时候,会在此column中插入一条记录
-
**c:data **,存储数据本身
2.4 Snapshot Isolation
-
事务中所有的读操作都会读到一个 consistent snapshot 的数据,等同于Repeated Read隔离级别;
-
两个并发事务同时对同一个cell写入时,只会有一个事务能够提交成功;
-
当一个事务提交时,如果发现本事务更新的一些数据,被其他比其start time大的事务修改之后,则roll back事务,否则commit事务;
-
存在write skew问题,两个事务读写的数据集有重叠,但是写入的数据集没有重叠,这种情况下,两个事务都可以成功commit,但是相互都没有看见对方写入的新数据,这达不到serializable的隔离级别。但是snpashot isolation相对serializable有更好的读性能,因为读操作只需要读快照数据即可,不需要加锁。
三、 事务处理
3.1 写入逻辑
Percolator使用两阶段提交算法(2PC)来提交事务,这两个阶段分别为 Prewrite 和 Commit。
在Prewrite阶段:
1)从TSO中获取一个timestamp,将其作为事务的start_ts;
2)对事务中需要写入的每行数据,都会在lock列中写入事务的start_ts,并在data列中写入新的数据并附带start_ts,例如上面的14:"value2"。这些locks中会有一个被选作为primary lock,其他locks叫做secondary locks。每个secondary lock都包含一个指向primary lock的指针。
1. 如果需要写入的数据中已经有一个比start_ts 更大的新版本数据,那么当前的事务需要rollback;
2. 如果需要插入lock的行数据中已经存在一个lock,那么当前事务需要rollback。
在Commit阶段:
1)从TSO中获取一个timestamp,将其作为事务的commit_ts;
2)将primary lock删除,同时在write列中写入commit_ts,这两个操作需要是原子的。如果primary lock不存在了,那么commit失败;
3)对所有的secondary locks重复上述步骤。
下面看一个具体的例子,还是一个经典的银行账号转账的例子,从账号Bob中转账7 dollar到账号Joe中:
1、在事务开始之前,两个账号Bob和Joe分别有10 dollars和2 dollars。

(图片来自:https://research.google)
2、在Prewrite阶段,往Bob的lock列中写入一个lock (7: I am primary),这个lock为primary lock,同时在data列中写入数据 7:$3。
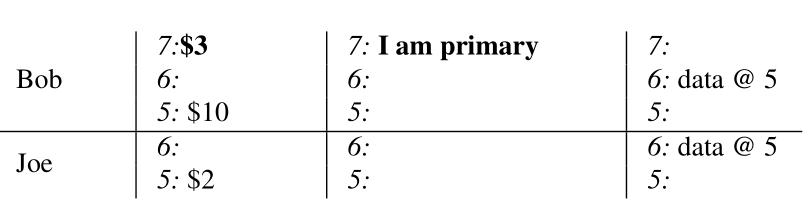
(图片来自:https://research.google)
3、在Prewrite阶段,继续写入secondary locks。往Joe的lock列中写入lock (7:primary@Bob.bal),这个lock指向之前写入的primary lock,同时在data列中写入数据 7:$9。

(图片来自:https://research.google)
4、在commit阶段,先清除掉primary lock,并在 write 列中使用新的timestamp (也就是commit_ts) 写入一条新的记录,同时清除 lock 列中的数据。

(图片来自:https://research.google)
5、在commit阶段,清除掉secondary locks,同时在 write 列中以新的timestamp写入新的记录。
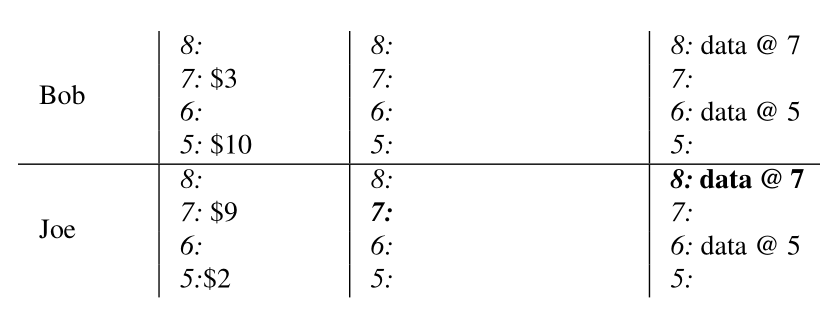
(图片来自:https://research.google)
3.2 读取逻辑
1)获取一个时间戳ts。
2)检查当前我们要读取的数据是否存在一个时间戳在[0, ts]范围内的锁。
-
如果存在一个时间戳在[0, ts]范围的锁,那么意味着当前的数据被一个比当前事务更早启动的事务锁定了,但是当前这个事务还没有提交。因为当前无法判断这个锁定数据的事务是否会被提交,所以当前的读请求不能被满足,只能等待锁被释放之后,再继续读取数据。
-
如果没有锁,或者锁的时间戳大于ts,那么读请求可以被满足。
3)从write列中获取在[0, ts]范围内的最大 commit_ts 的记录,然后依此获取到对应的start_ts。
4)根据上一步获取的start_ts,从data列获取对应的记录。
3.3 处理Client Crash场景
Percolator的事务协调者在Client端,而Client是可能出现crash的情况的。如果Client在提交过程中出现异常,那么事务之前写入的锁会被留下来。如果这些锁没有被及时清理,会导致后续的事务无限制阻塞在锁上。
Percolator采用 lazy 的方式来清理锁,当事务 A 遇到一个事务 B 留下来的锁时,事务 A 如果确定事务 B 已经失败了,则会将事务 B 留下来的锁给清理掉。但是事务 A 很难百分百确定判断事务 B 真的失败了,那就可能导致事务 A 正在清理事务 B 留下来的锁,而事务 B 其实还没有失败,且正在进行事务提交。
为了避免出现此异常,Percolator事务模型在每个事务写入的锁中选取一个作为Primary lock,作为清理操作和事务提交的同步点。在清理操作和事务提交时都会修改primary lock的状态,因为修改锁的操作是在Bigtable的行事务下进行的,所有清理操作和事务提交中只有一个会成功,这就避免了前面提到的并发场景下可能出现的异常。
根据primary lock的状态就可以确定事务是否已经成功commit:
如果Primary Lock不存在,且 write 列中已经写入了 commit_ts,那么表示事务已经成功commit;
如果Primary Lock还存在,那说明事务还没有进入到commit阶段,也就是事务还未成功commit。
事务 A 在提交过程中遇到事务 B 留下的锁记录时需要根据事务 B 的Primary Lock的状态来进行操作。
如果事务 B 的Primary Lock不存在,且 write 列中有 commit_ts 了,那么事务
A 需要将事务 B 的锁记录 roll-forward。roll-forward操作是rollback操作的反向操作,也就是将锁记录清除,并在 write 列中写入 commit_ts。
如果事务 B 的Primary Lock存在,那么事务 A 可以确定事务 B 还没有成功commit,此时事务 A 可以选择将事务 B 留下锁记录清除掉,在清除掉之前,需要将事务 B 的Primary Lock先清理掉。
如果事务 B 的Primary Lock不存在,且 write 列中也没有 commit_ts 信息,那么说明事务 B 已经被 rollback 了,此时也只需要将事务 B 留下的锁清理掉即可。
虽然上面的操作逻辑不会出现不一致的情况,但是由于事务 A 可能将存活着的事务 B 的Primary Lock清理掉,导致事务 B 被rollback,这会影响到系统的整体性能。
为了解决这个问题,Percolator使用了Chubby lockservice来存储每个正在进行事务提交的Client的存活状态,这样就可以确定Client是否真的已经挂掉了。只有在Client真的挂掉了之后,冲突事务才会真的清除掉Primary Lock以及冲突锁记录。但是还可能出现Client存活,但是其实其已经Stuck住了,没有进行事务提交的动作。这时如果不清理掉其留下的锁记录,会导致其他冲突事务无法成功提交。
为了处理这种场景,每个存活状态中还存储了一个wall time,如果判断wall time太旧之后,则进行冲突锁记录的处理。长事务则需要每隔一定的时间去更新这个wall time,保证其事务不会因此被rollback掉。
最终的事务冲突逻辑如下:
如果事务 B 的Primary Lock不存在,且 write 列中有 commit_ts 了,那么事务 A 需要将事务 B 的锁记录 roll-forward。roll-forward操作是rollback操作的反向操作,也就是将锁记录清除,并在 write 列中写入 commit_ts。
如果事务 B 的Primary Lock不存在,且 write 列中也没有 commit_ts 信息,那么说明事务 B 已经被 rollback 了,此时也只需要将事务 B 留下的锁清理掉即可。
如果事务 B 的Primary Lock存在,且TTL已经过期,那么此时事务 A 可以选择将事务 B 留下锁记录清除掉,在清除掉之前,需要将事务 B 的Primary Lock先清理掉。
如果事务 B 的Primary Lock存在,且TTL还未过期,那么此时事务 A 需要等待事务 B 的commit或者rollback后继续处理。
四、在TiKV中的实现及优化
4.1 Percolator在TiKV中的实现
TiKV底层的存储引擎使用的是RocksDB。RocksDB提供atomic write batch,可以实现Percolator对行事务的要求。
RocksDB提供一种叫做 Column Family(CF) 的功能,一个RocksDB实例可以有多个CFs,每个CF是一个隔离的key命令空间,并且拥有自己的LSM-tree。但是同一个RocksDB实例中的多个CFs共用一个WAL,这样可以保证写多个CFs是原子的。
在TiKV中,一个RocksDB实例中有三个CFs:CF_DEFAULT、CF_LOCK、CF_WRITE,分别对应着Percolator的data列、lock列和write列。
我们还需要针对每个key存储多个版本的数据,怎么表示版本信息呢?在TiKV中,我们只是简单地将key和timestamp结合成一个internal key来存储在RocksDB中。下面是每个CF的内容:
-
F_DEFAULT: (key,start_ts) -> value
-
CF_LOCK: key -> lock_info
-
CF_WRITE: (key,commit_ts) -> write_info
将key和timestamp结合在一起地方法如下:
-
将user key编码为 memcomparable 的形式;
-
对timestamp按位取反,然后编码成big-endian的形式;
-
将编码后的timestamp添加到编码后的key之后。
例如,key key1和时间戳 3 将被编码成 "key1\\x00\\x00\\x00\\x00\\xfb\\xff\\xff\\xff\\xff\\xff\\xff\\xff\\xfe"。这样同一个Key的不同版本在rocksdb中是相邻的,且版本比较大的数据在旧版本数据的前面。
TiKV中对Percolator的实现与论文中稍有差别。在TiKV中,CF_WRITE中有4中不同的类型的数据:
-
**Put **,CF_DEFAULT中有一条对应的数据,写入操作是一个Put操作;
-
Delete ,表示写入操作是一个Delete操作;
-
Rollback ,当回滚一个事务的时候,我们不是简单地删除CF_LOCK中的记录,而是在CF_WRITE中插入一条Rollback的记录。
-
Lock
4.2 Percolator在TiKV中的优化
4.2.1 Parallel Prewrite
对于一个事务来说,我们不以one by one的形式去做Prewrite。当我们有多个TiKV节点时,我们会在多个节点上并行地执行Prewrite。
在TiKV的实现中,当提交一个事务时,事务中涉及的Keys会被分成多个batches,每个batch在Prewrite阶段会并行地执行。不需要关注primary key是否第一个Prewrite成功。
如果在事务在Prewrite阶段发生了冲突,事务会被回滚。在执行回滚时,我们是在CF_WRITE中插入一条Rollback记录,而不是Percolator论文中描述的删除对应地锁记录。这条Rollback记录表示对应的事务已经rollback了,当一个后续的Prewrite请求到来时,这个Prewrite不会成功。这种情况可能在网络异常的时候会出现。如果我们让Prewrite请求成功,正确性还是可以保证,但是这个key会被锁定,直到锁记录过期之后,其他事务才可以再次锁定此key。
4.2.2 Short Value in Write Column
当我们访问一个value时,我们需要先从CF_WRITE中找到key对应最新版本start_ts,然后从CF_DEFAULT中找到具体的记录。如果一个value比较小的话,那么查找RocksDB两次开销相对来说有点大。
在具体实现中,为了避免short values两次查找RocksDB,做了一个优化。如果value比较小,在Prewrite阶段,我们不会将value放到CF_DEFAULT中,而是将其放在CF_LOCK中。然后在commit阶段,这个value会从CF_LOCK移动到CF_WRITE中。然后我们在访问这个short value时,就只需要访问CF_WRITE就可以了,减少了一次RocksDB查找。
4.2.3 Point Read Without Timestamp
对于每个事务,我们需要先分配一个start_ts,然后保证事务只能看到在start_ts之前提交的数据。但是如果一个事务只读取一个key的数据,我们是否有必要为其分配一个start_ts呢?答案是否定的,我们只需要读取这个key的最新数据就可以了。
4.2.4 Calculated Commit Timestamp
为了保证Snapshot Isolation,我们需要保证所有的transactional reads是repeatable的。commit_ts应该足够大,保证不会出现一个事务在一次valid read之前被提交,否则就没发保证repeatable read。例如:
Txn1 gets start_ts 100
Txn2 gets start_ts 200
Txn2 reads key "k1" and gets value "1"
Txn1 prewrites "k1" with value "2"
Txn1 commits with commit_ts 101
Tnx2 reads key "k1" and gets value "2"
Tnx2读取了两次"k1",但是得到了不一样的结果。如果commit_ts从PD上分配的,那么肯定不存在此问题,因为如果Txn2的第一次read操作发生在Txn1的Prewrite之前,Txn1的commit_ts肯定发生在完成Prewrite之后,那么Txn2的commit_ts肯定大于Txn1的start_ts。
但是,commit_ts也不能无限大。如果commit_ts大于实际时间的话,那么事务提交的数据新的事务可能读取步到。如果不向PD询问,我们是不能确定一个时间戳是否超过当前的实际时间的。
为了保证Snapshot Isolation的语义以及数据的完整性,commit_ts的有效范围应该是:
max(start_ts,max_read_ts_of_written_keys)<commit_ts<=now
commit_ts的计算方法为:
commit_ts=max(start_ts,region_1_max_read_ts,region_2_max_read_ts,...)+
其中region_N_max_read_ts为region N上所有读操作的最大时间戳,region N为事务所涉及的所有region。
4.2.5 Single Region 1PC
对于非分布式数据库来说,保证事务的ACID属性是比较容易地。但是对于分布式数据库来说,为了保证事务地ACID属性,2PC是必须地。TiKV使用地Percolator算法就是一种2PC算法。
在单region上,write batches是可以保证原子执行地。如果一个事务中影响的所有数据都在一个region上,2PC是没有必要的。如果事务没有write conflict,那么事务是可以直接提交的。
五、总结
优点:
-
事务管理建立在存储系统之上,整体系统架构清晰,系统扩展性好,实现起来简单;
-
在事务冲突较少的场景下,读写性能还不错;
缺点:
-
在事务冲突较多的场景下,性能较差,因为出现了冲突之后,需要不断重试,开销很大;
-
在采用MVCC并发控制算法的情况下也会出现读等待的情况,当存在读写冲突时,对读性能有较大影响;
总体上Percolator模型的设计还是可圈可点,架构清晰,且实现简单。在读写冲突较少的场景下,能够有还不错的性能。
六、引用
1. Codis作者首度揭秘TiKV事务模型,Google Spanner开源实现
2. Google Percolator 事务模型的利弊分析
4. Database · 原理介绍 · Google Percolator 分布式事务实现原理解读 (taobao.org)
作者:vivo互联网数据库团队-Wang Xiang

 浙公网安备 33010602011771号
浙公网安备 33010602011771号