

[python] 日常撸码小case
处理log时遇到一些东东
对log 的处理
- 从第二行读起: for line in f.readlines()[1:]
- 最后一个元素是个带换行符以及双引号的str,怎么处理呢? .strip()去掉换行符, eval()去掉双引号
- 查找如果这一行中有
dip write,就详细分析,但会拿到a_dip write,怎么办?
3.1 求助了闪存哈哈哈,嗷神给了提示, 用startwith(), 于是 ifdip writein line 改成了 if line.startswith('dip write') - 需要将
size=10和bgm=history改写成dict
4.1 urlparse 库可以轻松改dict:
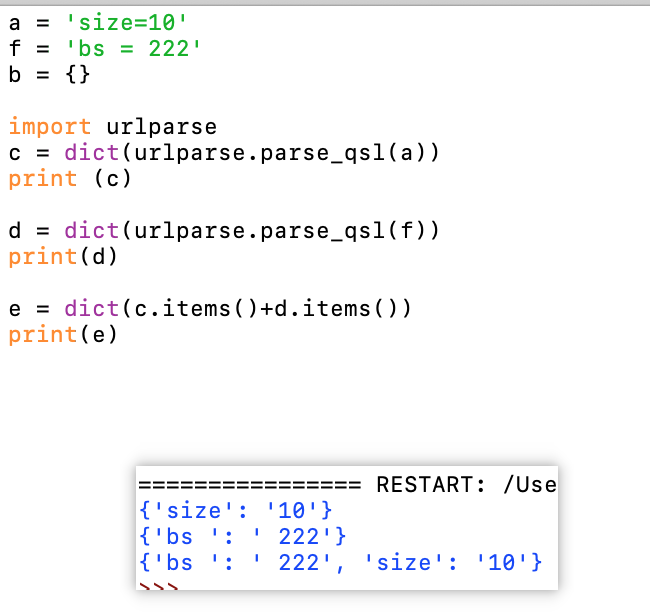
4.2 合并两个dict,summary = dict(a.items()+b.items())
with open('/mnt/test_annie/test.log', 'r') as f:
for line in f.readlines()[1:]:
# for line in f.readlines():
if line.startswith('dip write'):
useful_list = line.split(' ')
new_file_from_log = eval(useful_list[-1].strip())
for item in useful_list:
if '=' in item:
item = dict(urlparse.parse_qsl(item))
checkpoint_log = dict(checkpoint_log.items() + item.items())
对dir 的处理
- 用 instance.files.keys() 来获取路径下所有的files的path
- 用 sorted(instance.files.keys())[-1]来获取最新file的path
- 用 os.path.getsize(file_path)来获取file的size
new_file_path = sorted(self.instance.files.keys())[-1]
new_file_size = os.path.getsize(new_file_path)
log 的存储
cls.fh = logging.FileHandler('/mnt/test_annie/test.log')
cls.instance.logger.addHandler(cls.fh)
标签:
python


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧