
分布式日志收集系统:Facebook Scribe
1.分布式日志收集系统:背景介绍
许多公司的平台每天会产生大量的日志(一般为流式数据,如,搜索引擎的pv,查询等),处理这些日志需要特定的日志系统,一般而言,这些系统需要具有以下特征:
(1) 构建应用系统和分析系统的桥梁,并将它们之间的关联解耦;
(2) 支持近实时的在线分析系统和类似于Hadoop之类的离线分析系统;
(3) 具有高可扩展性。即:当数据量增加时,可以通过增加节点进行水平扩展。
2.分布式日志收集系统:Facebook Scribe主要内容
(1)Scribe简介及系统架构
(2)Scribe技术架构
(3)Scribe部署结构
(4)Scribe主要功能和使用方案
(5)Scribe的具体应用实例
(6)Scribe的扩展
(7)Scribe研究体会
3.Scribe简介
Scribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用。 Scribe是基于一个使用非阻断C++服务器的thrift服务的实现。它能够从各种日志源上收集日志,存储到一个中央存储系统 (可以是NFS,分布式文件系统等)上,以便于进行集中统计分析处理。它为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。
4.Scribe的系统架构
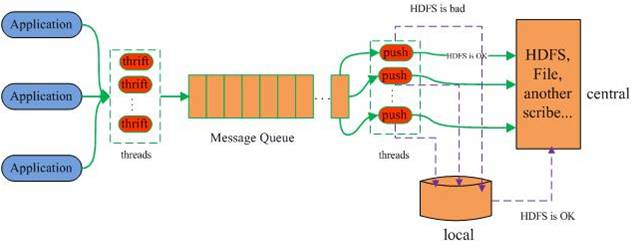
如上图所示:Scribe从各种数据源上收集数据,放到一个共享队列上,然后push到后端的中央存储系统上。当中央存储系统出现故障时,scribe可以暂时把日志写到本地文件中,待中央存储系统恢复性能后,scribe把本地日志续传到中央存储系统上。
5.Scribe的技术架构
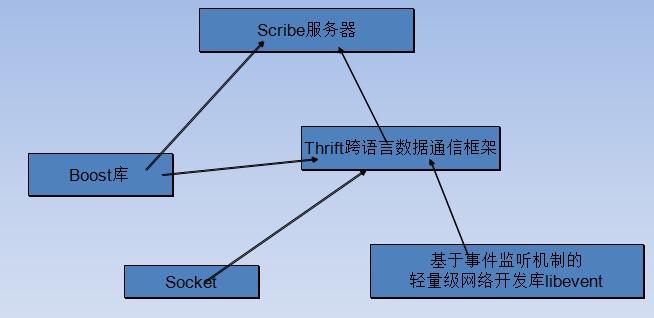
如上图所示:Scribe服务器底层数据通信框架是Thrift,Thrift也是Facebook开源的,并得到了广泛的使用。也用到了C++的准标准库boost,主要使用共享指针和文件相关的功能。Thrift也用到了libevent开发库和socket编程技术。
6.Scribe部署结构

7.Scribe的主要功能
1.支持多种存储类型:7种并且可扩展
2.日志自动切分功能:按文件大小和时间切分
3.灵活的客户端:
(1)支持多种常用语言(Thrift提供支持);
(2)可与应用系统集成;可以作实现独立客户端
4.支持日志分类功能(Facebook有上百种日志分类)
5.其他功能
(1)连接池
(2)灵活的日志缓存大小
(3)多线程功能(消息队列)
(4)scribe服务器之间可以转发日志
6.以上功能都是可以通过配置文件来灵活配置
8.Scribe使用方案
(1)和产生日志文件的应用系统集成
scribe能够和各种应用系统很好的集成是因为它提供几乎所有的开发语言的开发包
(2)应用系统在本地产生日志文件,使用一个独立运行的客户端程序同样,独立的客户端也可以采用各种语言开发,我们采用的是python来开发客户端
9.Scribe的具体应用实例
1.Facebook肯定大量的使用,主要用于处理Facebook级别日志,一旦有新的日志分类生成,Scribe将自动处理。(Facebook有上百个日志分类)。
2. Twitter:一款分布式实时统计系统Rainbird使用了scribe
3.我的公司:
(1)*****
(2)*****
(3)*****
(4)*****
(5)*****
(6)*****
4.其他
10.Scribe的扩展:存在的问题
虽然scribe系统是如此的优秀,但是也存在着一些不足和问题,针对存在的问题我们对scribe进行扩展。我们发现scribe存在的主要问题如下:
1、单点故障问题
有三个地方存在单点故障:
(1)中心服务器
(2)本地服务器
(3)收集日志的客户端程序
2、日志丢失问题
当日志文件发生切分的时候可能导致日志丢失
3、历史日志收集问题
4、scribe服务器挂了没有及时通知
11.Scribe的扩展:问题解决方案
针对上面我们提出的问题,主要提供如下相应的解决方案:
1.中心服务器单点故障
可以部署多个中心服务器,然后本地服务器通过配置文件可以自动在这些服务器之间进行切换
2.其余的问题我们都是通过自己写的python客户端解决的
python客户端我们是基于一个开源的项目进行二次开发的,因为开源的python客户端功能很简单,只是跟踪一个日志文件并把日志文件的数据读取导入到scribe本地服务器
12.Scribe的扩展:python客户端
我们开发的python客户端主要实现了如下功能:
1、解决本地scribe服务器的单点故障
我们可以通过配置多个本地scribe服务器(通过配置文件配置,相当的灵活),python脚本会根据配置的这些服务器自动切换(当一个scribe挂掉之后自动切换,如果挂掉本地scribe服务器重新启动以后又会自动切换回去。
2、解决日志丢失的问题
开源的python客户端是按照固定的时间间隔扫描日志文件是否有变化,如果在这个时间段内发生日志切换会导致日志丢失。我们同样是采用这个方式去检测日志文件,不过我们在发生日志切分的时候会再次去检测被切分走得日志文件是否已经收集完毕。
3、解决历史日志收集
如果在我们运行python客户端以前已经产生了日志,这部分的日志收集也是我们新增的一个功能
4、解决自身的单点故障问题
不排除我们的python客户端也会挂掉的时候,当我们下次启动怎样保证我们收集的日志不重复不丢失是需要解决的问题。我们的解决方案就是对已经收集的日志文件的各种信息做序列化(主要是已经收集日志文件的位置)
5、收集日志文件怎样保证按照日志生成的顺序收集
日志的生成顺序就是跟他们文件的建立时间是相关的,通过这一点我们可以实现。
6、及时通知机制
为了及时的通知到scrib服务器挂掉的信息到相关人员,我们开发了邮件通知机制,就是当某一个本地scribe服务器挂掉以后会触发邮件发送
13.Scribe研究体会
怎样从我们工作的内容深入学习?
1.每个人在公司负责开发的内容都是很有限的,怎样从我们开发的内容入手深入研究和学习更多的知识?
2.Scribe研究的例子!

14.总结:以上内容有一些是来至互联网,在加入了自己的一些理解,希望对需要的人有所帮助!
转自:http://blog.csdn.net/wanweiaiaqiang/article/details/7065370

 浙公网安备 33010602011771号
浙公网安备 33010602011771号