[机器学习][逻辑回归] 有监督学习之逻辑回归
线性回归方法一般只做回归分析,预测连续值等,而我们的任务是分类任务时该怎么办呢?下面我们讲一下最基本的分类方法,也就是逻辑回归方法(Logit regression)。逻辑回归又称为对数几率回归,它将线性回归的输出又进行了一个特殊的函数,使其输出一个代表分类可能性的概率值,这个特殊的函数称作sigmoid函数,如下式所示:
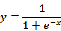
该函数的函数图像如下图所示:
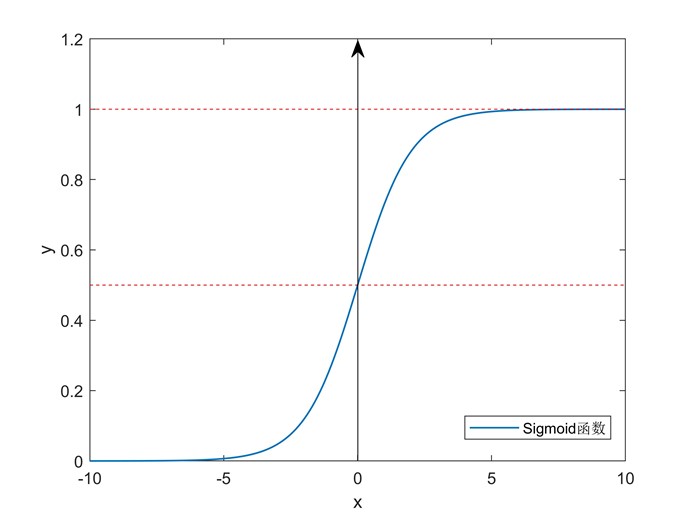
图6 sigmoid函数
Sigmoid函数在机器学习乃至深度学习中占有很重要的地位,因为它具有以下几个良好性质:
-
单调可微,具有对称性
-
便于求导,sigmoid函数的导数满足:
![]()
-
定义域为
![]() ,值域为
,值域为![]() ,可以将任意值映射到一个概率上
,可以将任意值映射到一个概率上
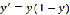
 ,值域为
,值域为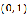 ,可以将任意值映射到一个概率上
,可以将任意值映射到一个概率上 将现行回归的输出值通过sigmoid函数,可以得到:
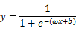
将上式稍作变形,可以得到:

可以看出,逻辑回归实际上就是用线性回归拟合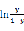 函数,但为什么逻辑回归能用于分类问题呢?由sigmoid函数的性质,我们可以做出假设:预测标签为第一类的数据概率为
函数,但为什么逻辑回归能用于分类问题呢?由sigmoid函数的性质,我们可以做出假设:预测标签为第一类的数据概率为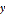 ,预测为第二类的概率为
,预测为第二类的概率为 。即:
。即:
现在预测的概率知道了,我们可以通过极大似然估计(Maximum Likelihood Estimate, MLE)来估计参数 ,使得每个样本的预测值属于其真实标签值的概率最大。这时,极大似然函数也是我们的损失函数:
,使得每个样本的预测值属于其真实标签值的概率最大。这时,极大似然函数也是我们的损失函数:
其中, 为所有待优化参数,
为所有待优化参数,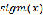 为关于参数
为关于参数 和样本特征
和样本特征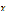 的sigmoid函数,
的sigmoid函数, 为样本数目。
为样本数目。
为了直观展示逻辑回归的功能,我们依然用一个例子来进行说明。我们随机在平面上依照某种规则随机生成两类数据点,每一类有100个样本,总共200个样本,如下图所示:
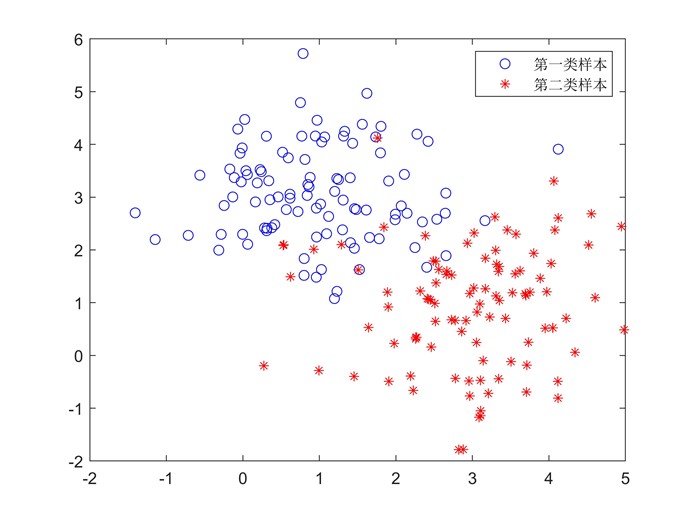
图7 随机生成的两类数据
可以看出每个样本点实际上就是坐标平面内的一个点,每个样本点有两个属性:横坐标值和纵坐标值。我们现在用逻辑回归来尝试将这两类数据分开,用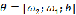 代表所有待优化的参数,即对下式进行逻辑回归:
代表所有待优化的参数,即对下式进行逻辑回归:
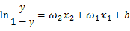
其中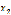 代表平面横坐标的值,
代表平面横坐标的值, 代表纵坐标的值。
代表纵坐标的值。
和均方差损失函数不同,这个似然函数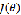 是需要最大化的。所以需要采用梯度上升法对似然函数进行最大化。与梯度下降法一样,只需要求出似然函数的对各个参数的偏导数即可对函数进行迭代更新。经过计算,可以得出对参数的更新方式如下:
是需要最大化的。所以需要采用梯度上升法对似然函数进行最大化。与梯度下降法一样,只需要求出似然函数的对各个参数的偏导数即可对函数进行迭代更新。经过计算,可以得出对参数的更新方式如下:

其中,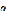 是学习率。这里用梯度上升法优化极大似然函数与用梯度下降法优化均方误差函数是等价的,有兴趣的读者可以证明一下。
是学习率。这里用梯度上升法优化极大似然函数与用梯度下降法优化均方误差函数是等价的,有兴趣的读者可以证明一下。
现在我们用梯度上升法对上面提到的200个样本进行分类,可以得到如下分界线(学习率设为0.00001):
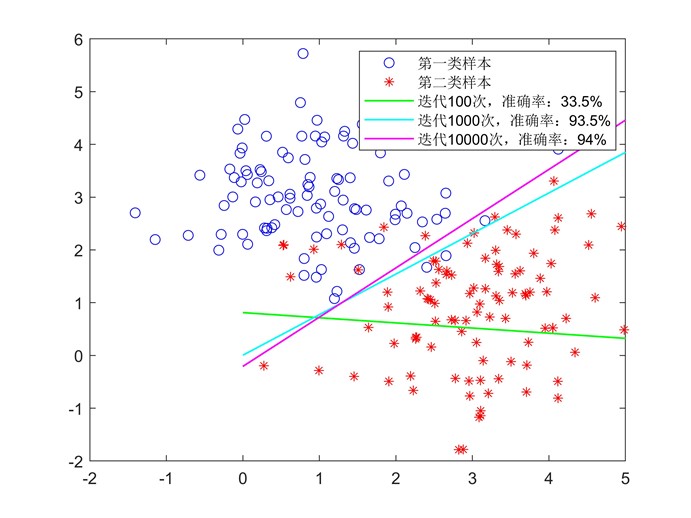
图8 逻辑回归分类
可以看到随着迭代数的增加,对原数据的分类准确率越来越高。对迭代过程进行可视化,我们可以看到似然函数随着参数改变的迭代优化过程:
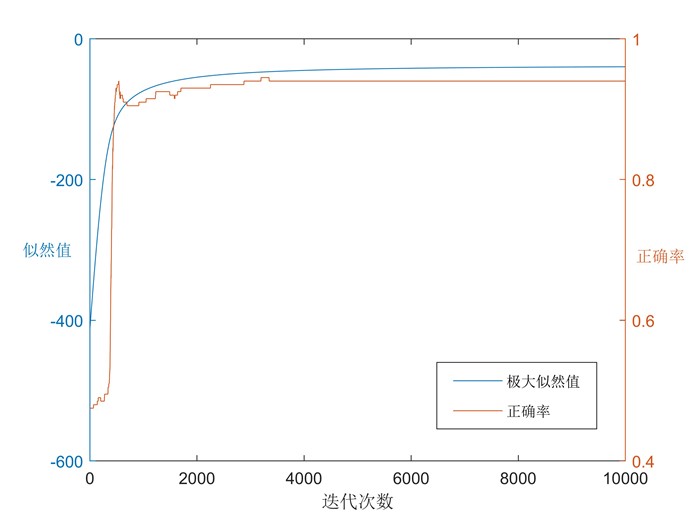
图9 逻辑回归优化过程
上面介绍的逻辑回归实际上是一个没有隐含层的简单神经网络,sigmoid函数对应于神经网络中的激活函数。深度学习是具有多个隐含层的神经网络,优化方法还是基本的梯度上升或梯度下降法,所以逻辑回归是深度学习的基石,在深度学习中也占有重要地位。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号