使用LabVIEW 实现物体识别、图像分割、文字识别、人脸识别等深度视觉
前言
哈喽,各位朋友们,这里是virobotics(仪酷智能),这两天有朋友私信问之前给大家介绍的工具包都可以实现什么功能,最新的一些模型能否使用工具包加载,今天就给大家介绍一下博主目前使用工具包已经实现的深度视觉模型及案例
下表为前期写过的一些范例介绍,朋友们可以按需点击查看
一、实现物体识别
无论使用何种框架训练物体检测模型,都可以无缝集成到LabVIEW中,并使用工具包提供的CUDA、tensorRT接口实现加速推理,模型包括但不限于:
- yolov3、yolov4、yolov5、yolov6、yolov7、pp-yoloe、yolox等
- torchvision中的图像分类、目标检测模型等
如下为已经实现中的一部分范例
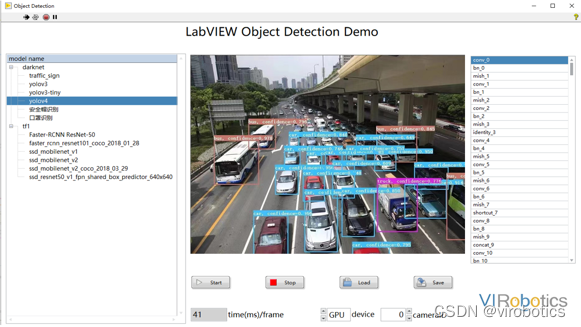
- yolov4实现目标检测:
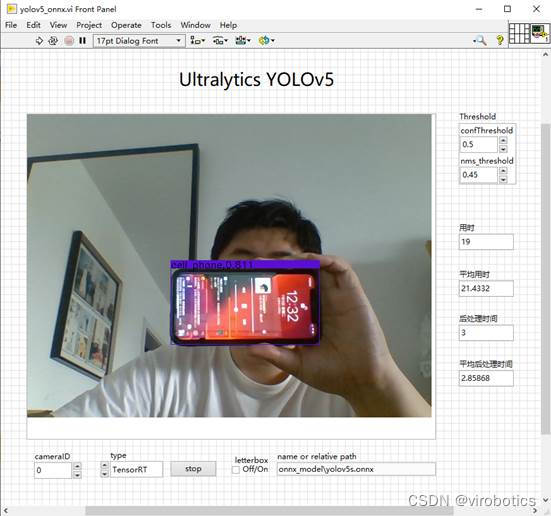
- 基于onnx,yolov5使用tensorRT实现推理加速:
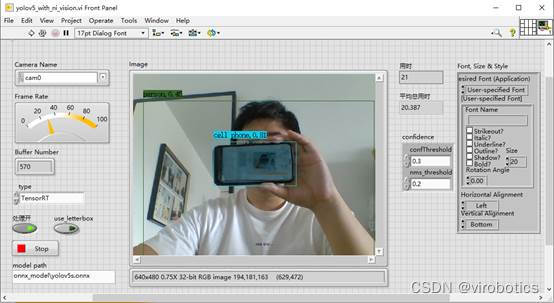
- NI vision采集图像、tensorRT加速实现yolov5目标检测
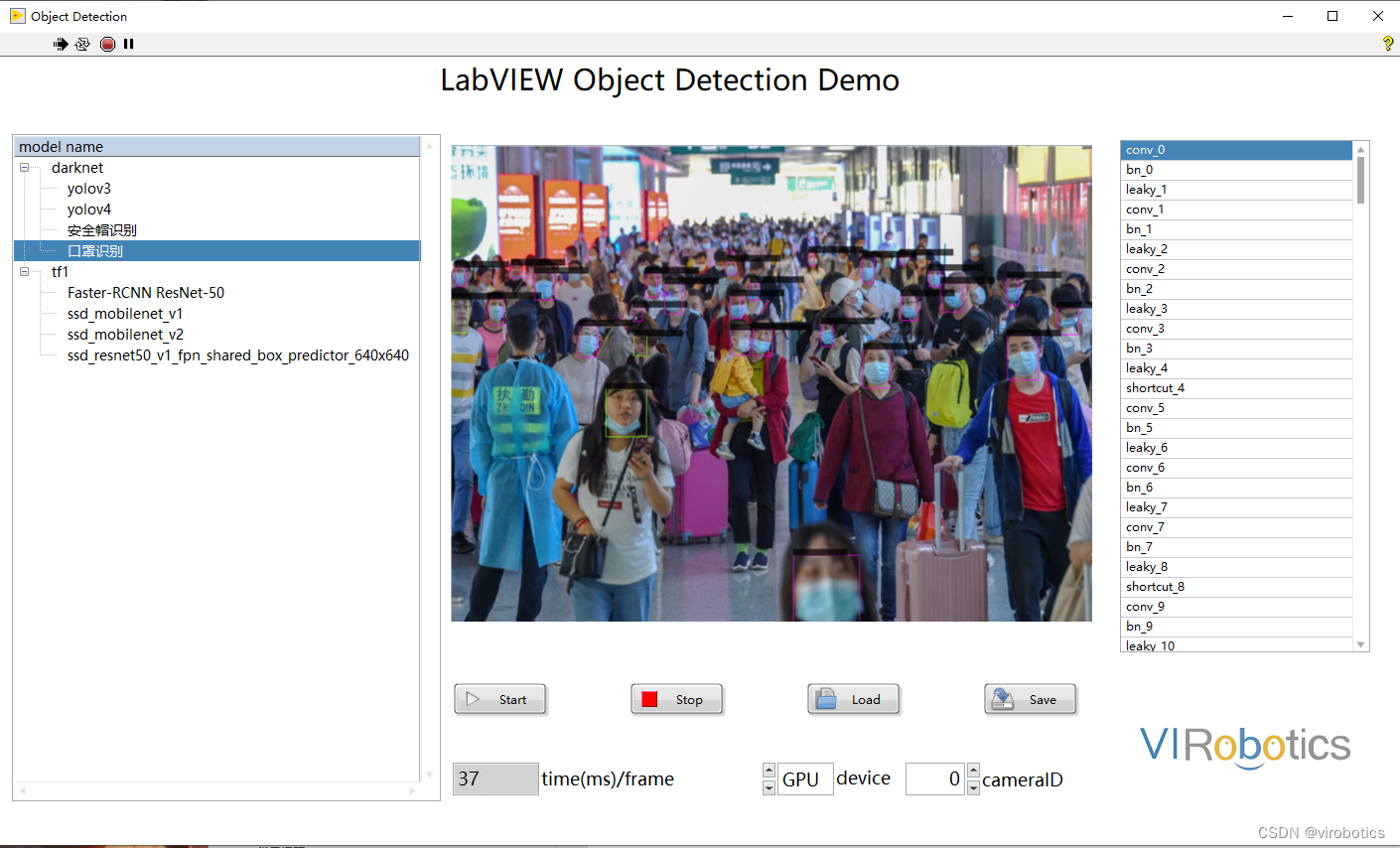
- yolov5实现口罩检测:
![在这里插入图片描述]()
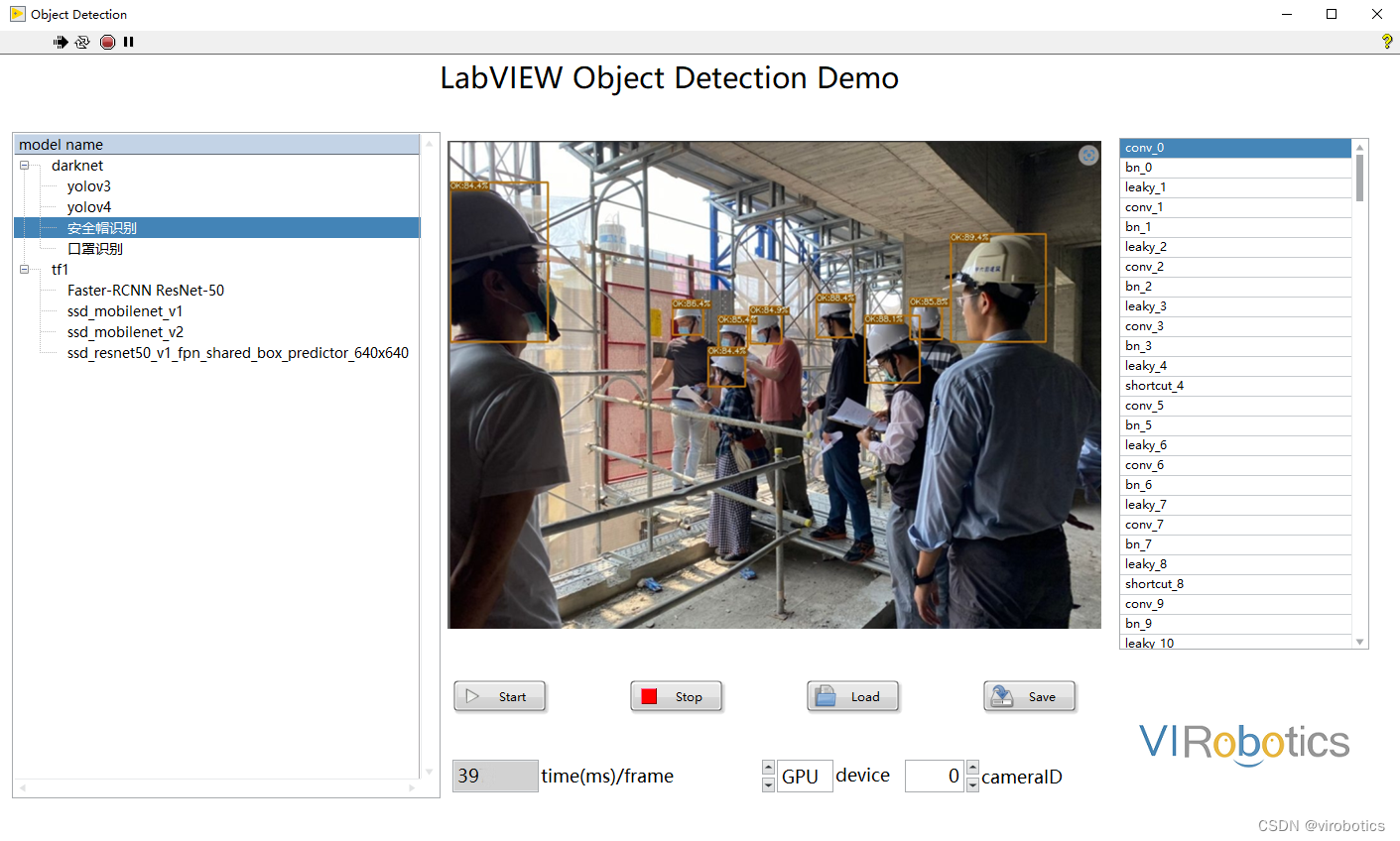
- yolov5实现安全帽检测:
![在这里插入图片描述]()
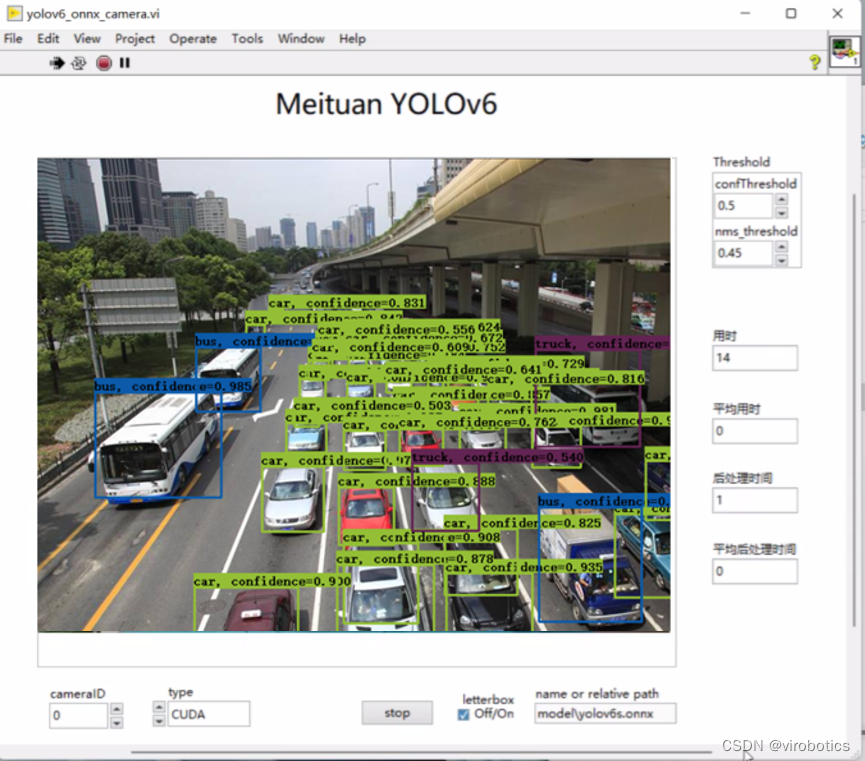
- yolov6实现目标检测:
![在这里插入图片描述]()
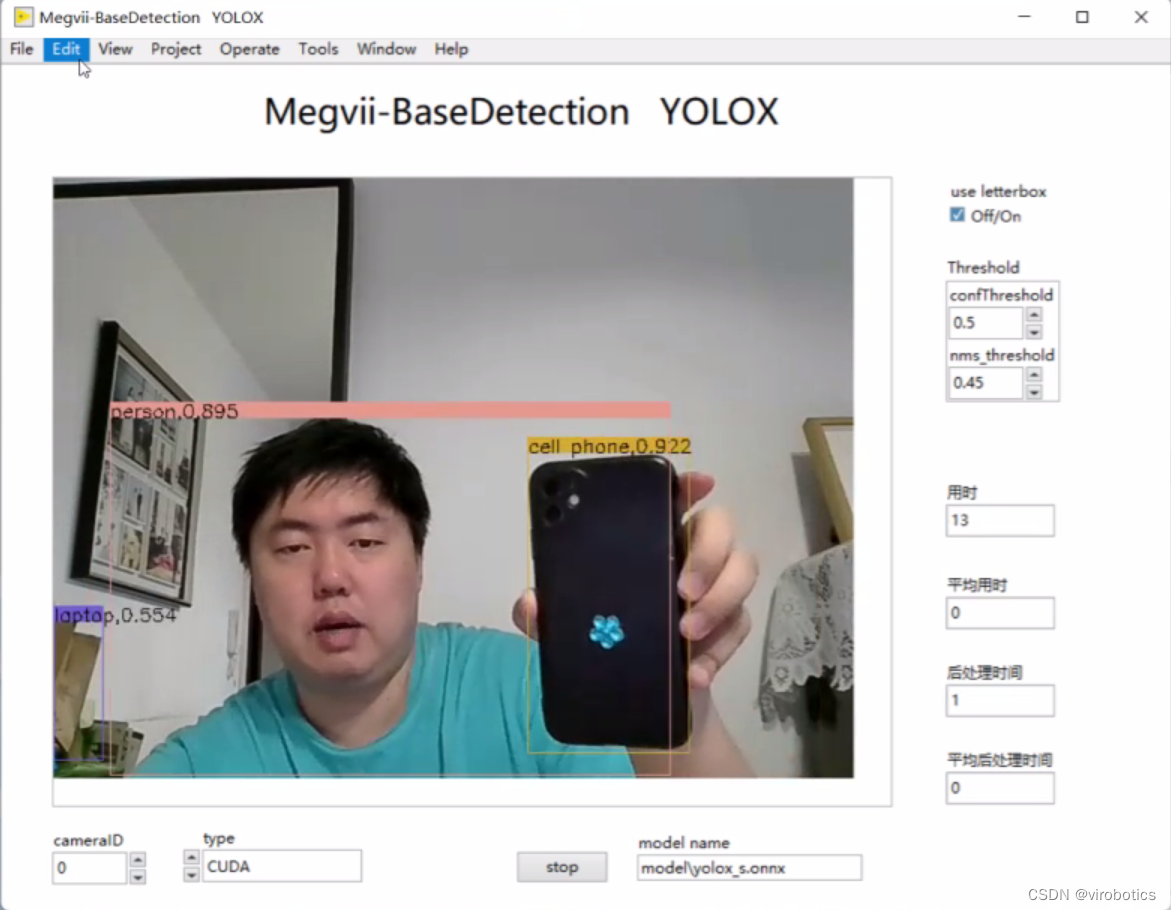
- yolox实现目标检测:
![在这里插入图片描述]()
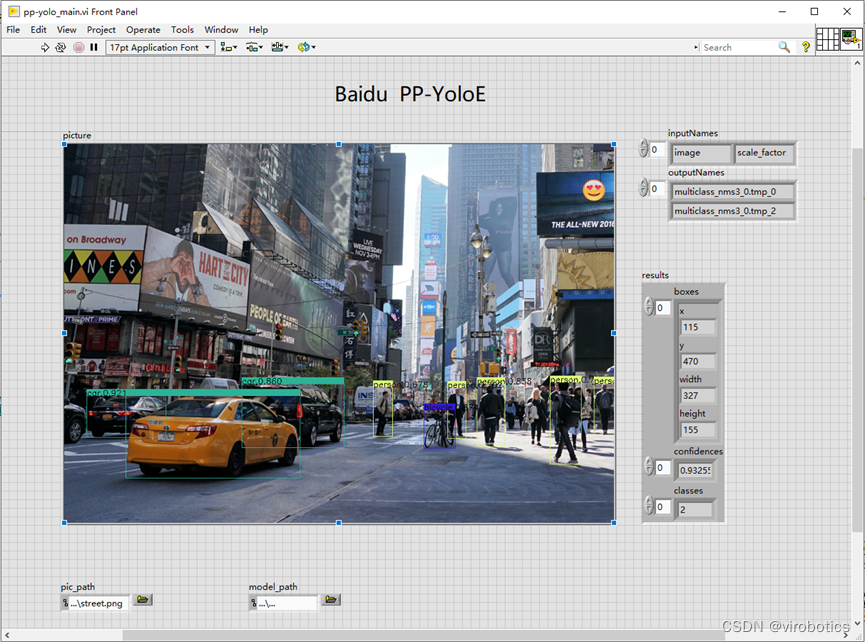
- 百度PP-YOLOE实现目标检测:
![在这里插入图片描述]()
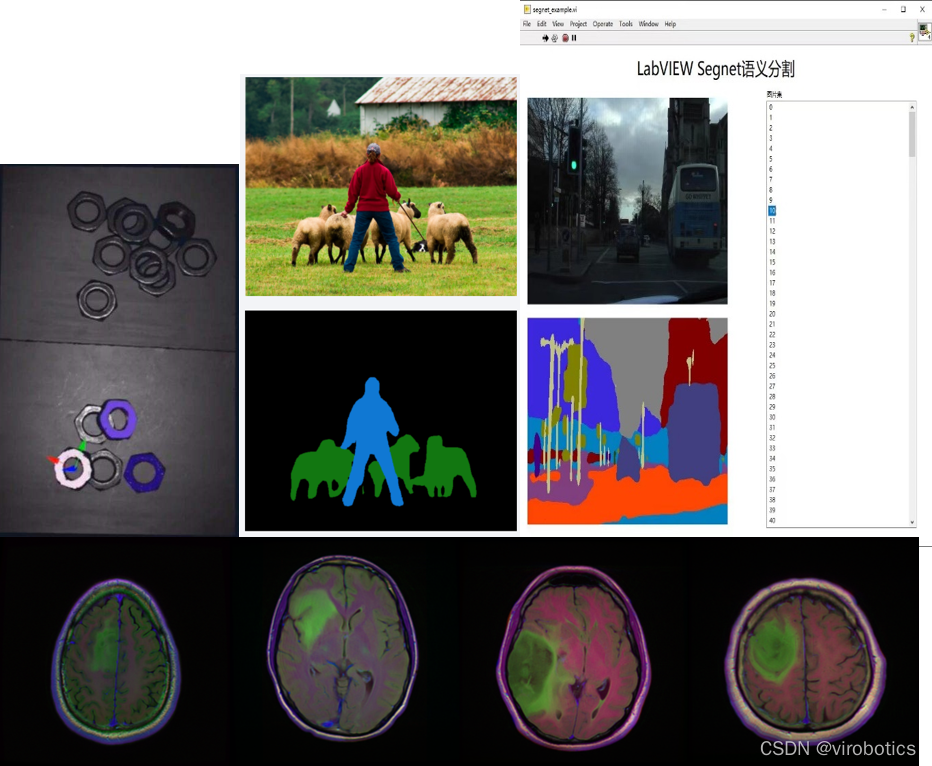
二、实现图像分割
图像分割是当今计算机视觉领域的关键问题之一。从宏观上看,图像分割是一项高层次的任务,为实现场景的完整理解铺平了道路。场景理解作为一个核心的计算机视觉问题,其重要性在于越来越多的应用程序通过从图像中推断知识来提供营养。随着深度学习软硬件的加速发展,一些前沿的应用包括自动驾驶汽车、人机交互、医疗影像等,都开始研究并使用图像分割技术。
本次集成的工具包提供了多种图像分割的调用模块,并实现了GPU模式下TensorRT的加速运行。如:
语义分割:Segnet、deeplabv1~deeplabv3、deeplabv3+、u-net等;
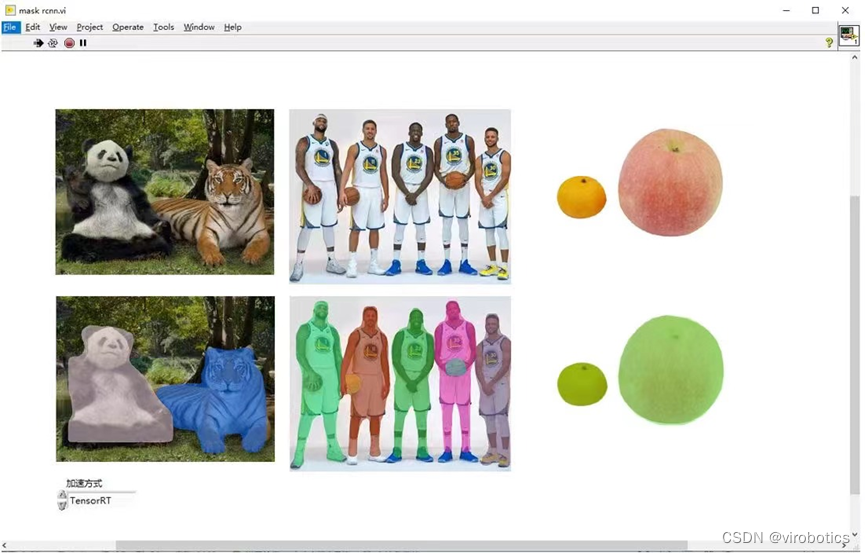
实例分割:Mask-RCNN、PANet等
- deeplab实现分割
![在这里插入图片描述]()
- mask Rcnn实现图像分割
![在这里插入图片描述]()
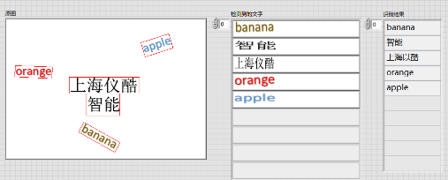
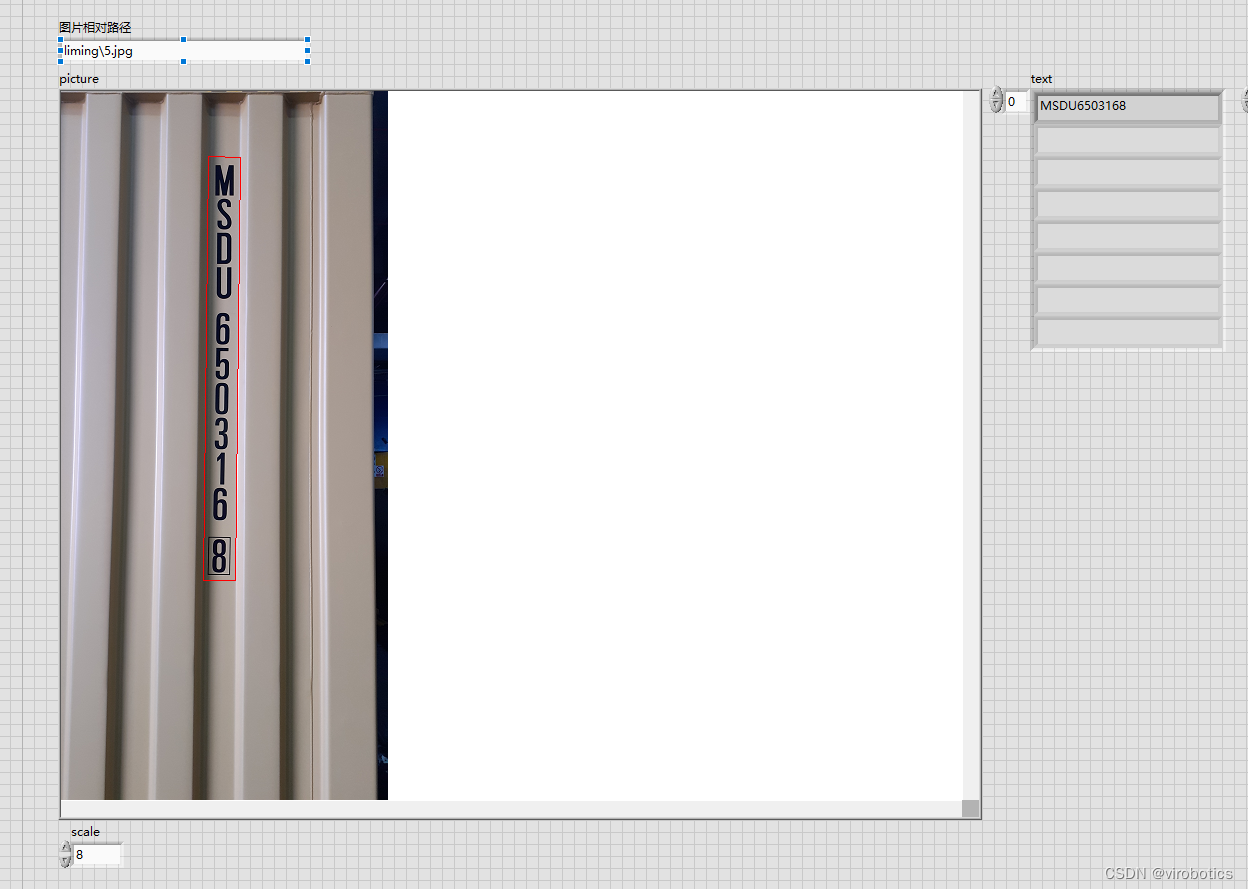
三、自然场景下的文字识别
工具包提供了文本检测定位(DB_TD500_resnet50、EAST)、文本识别的模块(CRNN),用户可以使用该模块实现自然场景下的中英文文字识别
应用:身份证识别、表单识别、包装盒标签检测等
- 简单文字识别
![在这里插入图片描述]()
- 包装盒标签检测
![]()
- 复杂背景字母数字检测
![在这里插入图片描述]()

四、人脸检测与识别
工具包提供了人脸检测与识别的模块,用户可以使用该模块实现人脸检测与识别
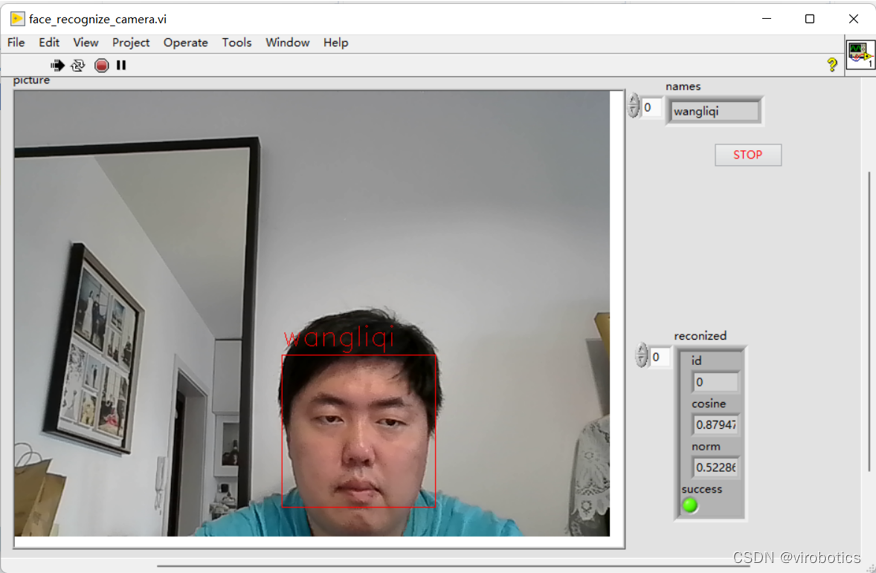
五、人体关键点检测
机器学习ML5扩展功能中的Keypoint Rcnn功能可以实现17个人体姿态识别以及追踪位置,通过此功能可以进行一些姿态控制应用,且此功能不用连接网络,只需要一个摄像头即可实现。
姿势估计是指计算机视觉技术,用于检测图像和视频中的人类图形,以便确定某人的肘部出现在图像中的位置。需要说明的是,该技术无法识别图像中的人员,不存在与姿势检测相关的个人身份信息。该算法只是估计关键体关节的位置
结合了Realsense的姿态识别,即可定位人体每个部位的精确位置。

六、工具包下载
如需下载工具包可查看指定博文,如需获取最新版本工具包,可关注微信公众号:VIRobotics,回复关键字:LabVIEW AI工具包
总结
以上就是今天要给大家分享的内容。如有笔误,还请各位及时指正。后续还会继续给各位朋友分享其他案例,欢迎大家关注博主。
如果有问题可以在评论区里讨论,提问前请先点赞支持一下博主哦,如您想要探讨更多关于LabVIEW与人工智能技术,欢迎点击下方卡片,加入我们的技术交流群:705637299,进群请备注:上海仪酷
**如果文章对你有帮助,欢迎✌关注、👍点赞、✌收藏

 浙公网安备 33010602011771号
浙公网安备 33010602011771号