
面试官:项目中如何实现布隆过滤器?
谈起“布隆过滤器”相信大家都不陌生,它也算日常面试中的常见面试题了。例如,当面试官在问到 Redis 模块的相关问题时,可能会问到缓存穿透(Redis 四大经典问题之一),而缓存穿透的经典解决方案之一,则是“布隆过滤器”。
但是,对于布隆过滤器是什么?以及布隆过滤器的实现原理?相信大部分同学都能回答个七七八八。当如果被问道:项目当中是如何实现布隆过滤器的?这个时候大部分同学就又回答不上来了,所以今天咱们就来探讨一下这个问题。
1. 什么是布隆过滤器?
布隆过滤器(Bloom Filter)是一种高效的数据结构,由布隆在 1970 年提出。它主要用于判断一个元素可能是否存在于集合中,其核心特性包括高效的插入和查询操作,但存在一定的假阳性(False Positives)可能性。
布隆过滤器实现如下图所示:
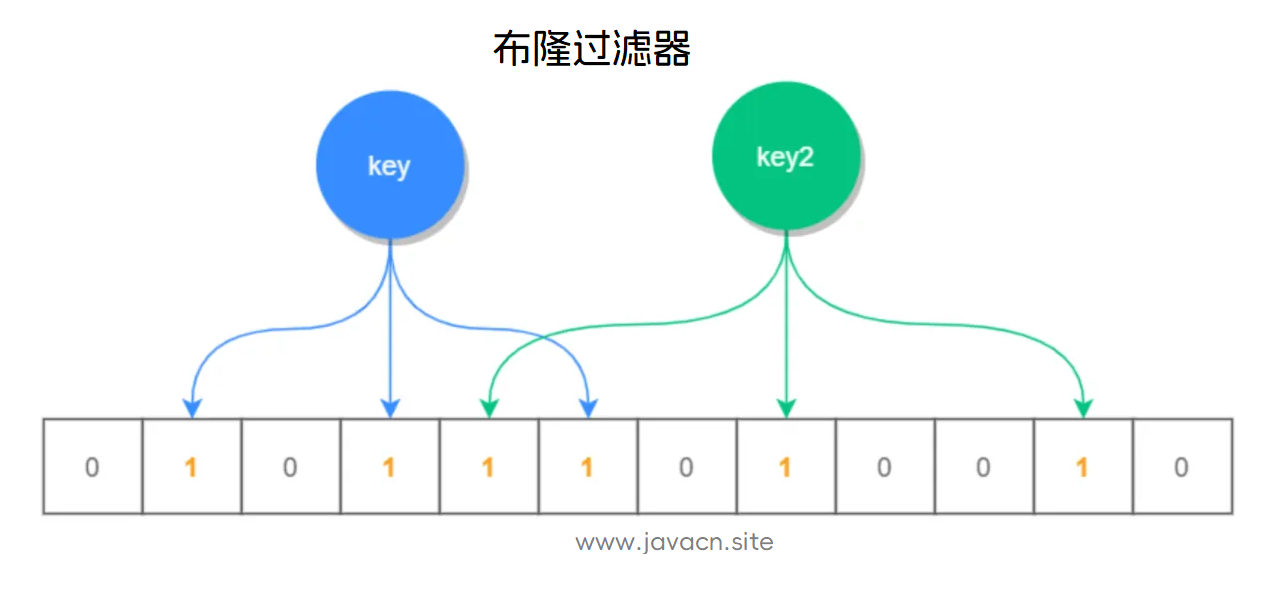
根据 key 值计算出它的存储位置,然后将此位置标识全部标识为 1(未存放数据的位置全部为 0),查询时也是查询对应的位置是否全部为 1,如果全部为 1,则说明数据是可能存在的,否则一定不存在。
也就是说,如果布隆过滤器说一个元素不在集合中,那么它一定不在这个集合中;但如果它说一个元素在集合中,则有可能是不存在的(存在误差,假阳性)。
2.布隆过滤器特征
- 高效节省空间:布隆过滤器不存储数据本身,只存储数据对应的哈希比特位,因此占用空间非常小。
- 快速的插入和查询:插入和查询操作的时间复杂度都为 O(k),其中 k 为哈希函数的个数,这使得布隆过滤器在处理大量数据时非常高效。
- 存在假阳性:由于哈希碰撞的可能性,布隆过滤器在判断元素存在时可能会出现误判,即元素实际上不在集合中,但过滤器错误地认为其存在。这种误判率取决于哈希函数的个数和位数组的长度。
- 不支持删除操作:一旦一个元素被添加到布隆过滤器中,很难将其准确地删除。因为多个元素可能会共用位数组中的某些位,删除一个元素可能会影响其他元素的判断结果。
- 灵活性与可配置性:布隆过滤器的误判率、位数组的长度和哈希函数的个数都是可以根据具体应用场景进行调整的,以达到最优的性能和误判率平衡。
3.使用场景
布隆过滤器的主要使用场景有以下几个:
- 大数据量去重:可以用布隆过滤器来进行数据去重,判断一个数据是否已经存在,避免重复插入。
- 防止缓存穿透问题:可以用布隆过滤器来过滤掉恶意请求或请求不存在的数据,避免对后端存储的频繁访问。
- 网络爬虫URL 去重:可以用布隆过滤器来判断 URL 是否已经被爬取,避免重复爬取。
4.布隆过滤器实现
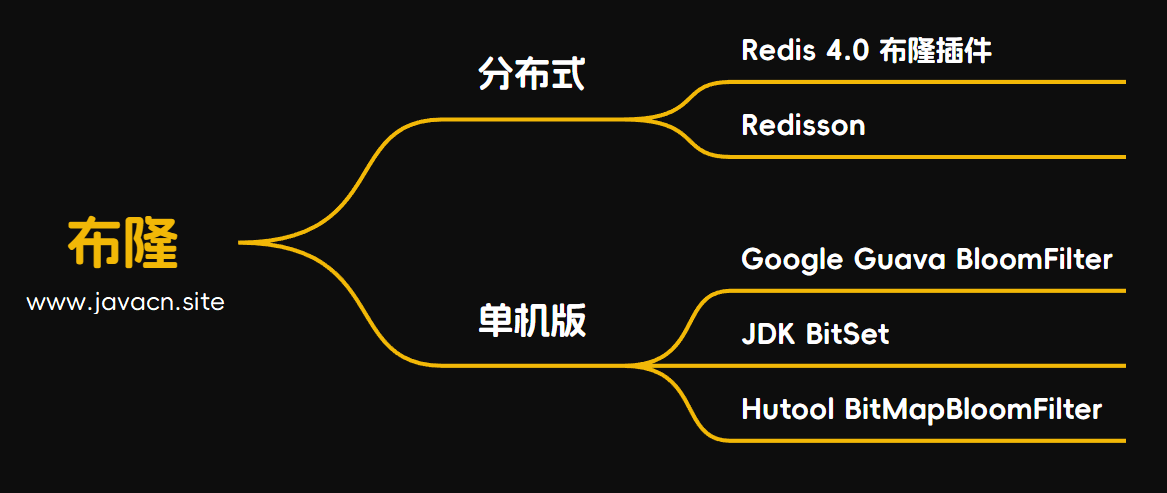
实现布隆过滤器的方法有很多,可以分为以下两类:
- 分布式布隆过滤器
- 使用 Redis 4.0 之后提供的插件来实现布隆过滤器。
- 使用 Redisson 框架实现布隆过滤器。
- 单机布隆过滤器
- 使用 Google Guava 实现布隆过滤器。
- 使用 Java 自带的数据结构 BitSet 来实现布隆过滤器。
- 使用 Hutool 框架实现布隆过滤器。
5.项目中具体实现
在项目开发当中,如果使用的是 Redis 4.0+ 版本,我们通常会使用 Redis 布隆过滤器插件来实现布隆过滤器,以下是具体的实现步骤。
1.下载编译RedisBloom插件
git clone https://github.com/RedisLabsModules/redisbloom.git
cd redisbloom
make # 编译redisbloom
编译正常执行完,会在根目录生成一个 redisbloom.so 文件。
2.启用RedisBloom插件
重新启动 Redis 服务,并指定启动 RedisBloom 插件,具体命令如下:
redis-server redis.conf --loadmodule ./src/modules/RedisBloom-master/redisbloom.so
3.创建布隆过滤器
创建一个布隆过滤器,并设置期望插入的元素数量和误差率,在 Redis 客户端中输入以下命令:
BF.RESERVE my_bloom_filter 0.01 100000
4.添加元素到布隆过滤器
在 Redis 客户端中输入以下命令:
BF.ADD my_bloom_filter leige
5.检查元素是否存在
在 Redis 客户端中输入以下命令:
BF.EXISTS my_bloom_filter leige
课后思考
早期 Redis 版本中如何实现布隆过滤器?说说 Redisson 框架实现布隆过滤器的底层原理?
本文已收录到我的面试小站 www.javacn.site,其中包含的内容有:Redis、JVM、并发、并发、MySQL、Spring、Spring MVC、Spring Boot、Spring Cloud、MyBatis、设计模式、消息队列等模块。





 浙公网安备 33010602011771号
浙公网安备 33010602011771号