
面试官:limit 100w,10为什么慢?如何优化?

在 MySQL 中,limit X,Y 的查询中,X 值越大,那么查询速度也就越慢,例如以下示例:
- limit 0,10:查询时间大概在 20 毫秒左右。
- limit 1000000,10:查询时间可能是 15 秒左右(1秒等于 1000 毫秒),甚至更长时间。
所以,可以看出,limit 中 X 值越大,那么查询速度都越慢。
这个问题呢其实就是 MySQL 中典型的深度分页问题。那问题来了,为什么 limit 越往后查询越慢?如何优化查询速度呢?
为什么limit越来越慢?
在数据库查询中,当使用 LIMIT x, y 分页查询时,如果 x 值越大,查询速度可能会变慢。这主要是因为数据库需要扫描和跳过 x 条记录才能返回 y 条结果。随着 x 的增加,需要扫描和跳过的记录数也增加,从而导致性能下降。
例如 limit 1000000,10 需要扫描 1000010 行数据,然后丢掉前面的 1000000 行记录,所以查询速度就会很慢。
优化手段
对于 MySQL 深度分页比较典型的优化手段有以下两种:
- 起始 ID 定位法:使用最后查询的 ID 作为起始查询的 ID。
- 索引覆盖+子查询。
1.起始ID定位法
起始 ID 定位法指的是 limit 查询时,指定起始 ID。而这个起始 ID 是上一次查询的最后一条 ID。例如上一次查询的最后一条数据的 ID 为 6800000,那我们就从 6800001 开始扫描表,直接跳过前面的 6800000 条数据,这样查询的效率就高了,具体实现 SQL 如下:
select name, age, gender
from person
where id > 6800000 -- 核心实现 SQL
order by id limit 10;
其中 id 字段为表的主键字段。
为什么起始ID查询效率高呢?
因此这种查询是以上一次查询的最后 ID 作为起始 ID 进行查询的,而上次的 ID 已经定位到具体的位置了,所以只需要遍历 B+ 树叶子节点的双向链表(主键索引的底层数据结构)就可以查询到后面的数据了,所以查询效率就比较高,如下图所示:
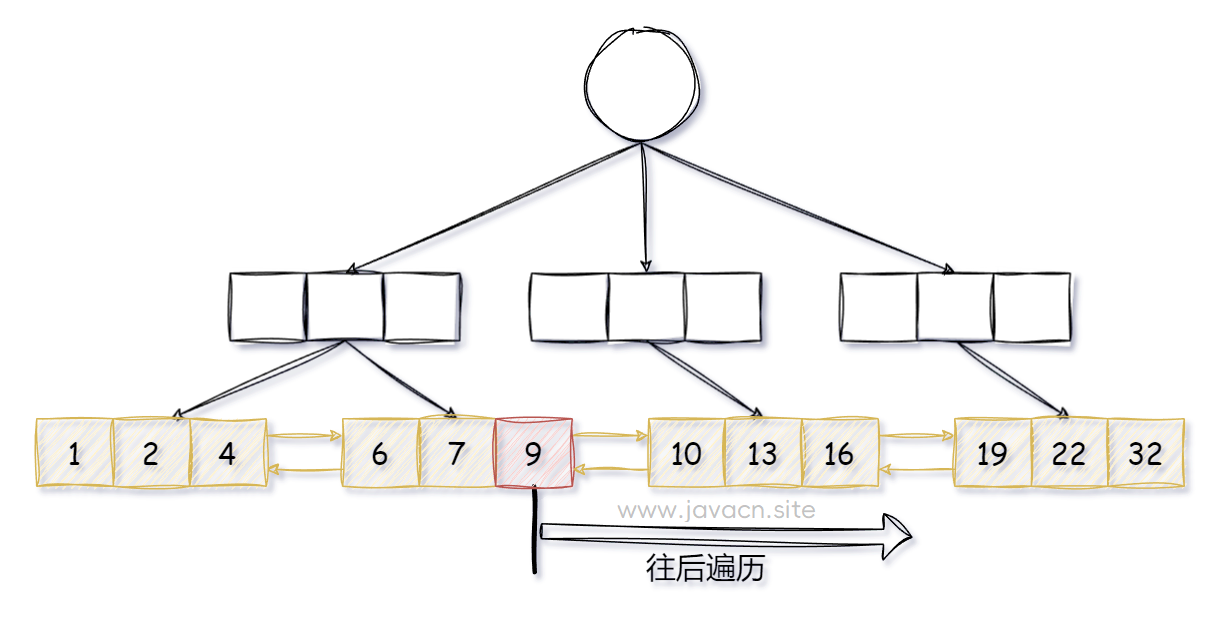
如果上次查询结果为 9,之后再查询时,只需要从 9 之后再遍历 N 条数据就能查询出结果了,所以效率就很高。
优缺点分析
这种查询方式,只适合一页一页的数据查询,例如手机 APP 中刷新闻时那种瀑布流方式。
但如果用户是跳着分页的,例如查询完第 1 页之后,直接查询第 250 页,那么这种实现方式就不行了。
2.索引覆盖+子查询
此时我们为了查询效率,可以使用索引覆盖加子查询的方式,具体实现如下。
假设,我们未优化前的 SQL 如下:
select name, age, gender
from person
order by createtime desc
limit 1000000,10;
在以上 SQL 中,createtime 字段创建了索引,但查询效率依然很慢,因为它要取出 100w 完整的数据,并需要读取大量的索引页,和进行频繁的回表查询,所以执行效率会很低。
此时,我们可以做以下优化:
SELECT p1.name, p1.age, p1.gender
FROM person p1
JOIN (
SELECT id FROM person ORDER BY createtime desc LIMIT 1000000, 10
) AS p2 ON p1.id = p2.id;
相比于优化前的 SQL,优化后的 SQL 将不需要频繁回表查询了,因为子查询中只查询主键 ID,这时可以使用索引覆盖来实现。那么子查询就可以先查询出一小部分主键 ID,再进行查询,这样就可以大大提升查询的效率了。
索引覆盖(Index Coverage)是一种数据库查询优化技术,它指的是在执行查询时,数据库引擎可以直接从索引中获取所有需要的数据,而不需要再回表(访问主键索引或者表中的实际数据行)来获取额外的信息。这种方式可以减少磁盘 I/O 操作,从而提高查询性能。
课后思考
你还知道哪些深度分页的优化手段呢?欢迎评论区留下你的答案。
本文已收录到我的面试小站 www.javacn.site,其中包含的内容有:Redis、JVM、并发、并发、MySQL、Spring、Spring MVC、Spring Boot、Spring Cloud、MyBatis、设计模式、消息队列等模块。





 浙公网安备 33010602011771号
浙公网安备 33010602011771号