MySQL Json 字段类型操作
创建表
CREATE TABLE `demo` (
`id` varchar(36) PRIMARY KEY ,
`username` varchar(100),
`password` varchar(100),
`nickname` varchar(100),
`roles` json,
`status` int
)
插入
json格式的字段,插入时会自动校验格式,如果格式不是json的,会报错
INSERT INTO `demo` VALUES ('833d52048c653ffd282b4d8bd44d6469', NULL, NULL, '李1', '[{\"id\": \"1\", \"code\": \"RoleCode11\", \"name\": \"普通用户11\"}, {\"id\": \"1\", \"code\": \"RoleCode12\", \"name\": \"普通用户12\"}, {\"id\": \"1\", \"code\": \"RoleCode13\", \"name\": \"普通用户13\"}]', 1);
INSERT INTO `demo` VALUES ('04bfdca6b2366206d590a508ab176ed8', NULL, NULL, '李2', '[{\"id\": \"2\", \"code\": \"RoleCode21\", \"name\": \"普通用户21\"}, {\"id\": \"2\", \"code\": \"RoleCode22\", \"name\": \"普通用户22\"}, {\"id\": \"2\", \"code\": \"RoleCode23\", \"name\": \"普通用户23\"}]', 1);
INSERT INTO `demo` VALUES ('25729744994a10b8986c4bab4baa9847', NULL, NULL, '李3', '[{\"id\": \"3\", \"code\": \"RoleCode31\", \"name\": \"普通用户31\"}, {\"id\": \"3\", \"code\": \"RoleCode32\", \"name\": \"普通用户32\"}, {\"id\": \"3\", \"code\": \"RoleCode33\", \"name\": \"普通用户33\"}]', 1);
INSERT INTO `demo` VALUES ('77d94515acb00db06c687bdae68196b5', NULL, NULL, '李4', '[{\"id\": \"4\", \"code\": \"RoleCode41\", \"name\": \"普通用户41\"}, {\"id\": \"4\", \"code\": \"RoleCode42\", \"name\": \"普通用户42\"}, {\"id\": \"4\", \"code\": \"RoleCode43\", \"name\": \"普通用户43\"}]', 1);
INSERT INTO `demo` VALUES ('b04e4a99d1892f2ad8b3ca5802e5e168', NULL, NULL, '李5', '[{\"id\": \"5\", \"code\": \"RoleCode51\", \"name\": \"普通用户51\"}, {\"id\": \"5\", \"code\": \"RoleCode52\", \"name\": \"普通用户52\"}, {\"id\": \"5\", \"code\": \"RoleCode53\", \"name\": \"普通用户53\"}]', 1);
INSERT INTO `demo` VALUES ('b04e4a99d1892f2ad8b3ca5802e5e166', NULL, NULL, '李6', '{\"id\": \"6\", \"code\": \"RoleCode61\", \"name\": \"普通用户61\"}', 1);
INSERT INTO `demo` VALUES ('b04e4a99d1892f2ad8b3ca5802e5e167', NULL, NULL, '可不带\线', '{"id": "7", "code": "RoleCode71", "name": "普通用户71"}', 1);
插入数据
# JSON_ARRAY()函数插入数组
insert into demo(id,nickname,roles) values('1','JSON_ARRAY',JSON_ARRAY(1, "JSON_ARRAY", null, true,curtime()));
# JSON_OBJECT()函数插入对象
insert into demo(id,nickname,roles) values('2','JSON_OBJECT',json_object('id',11, 'name','JSON_OBJECT'));
JSON_OBJECT()函数插入对象
对于 JSON 文档,KEY 名不能重复。
如果插入的值中存在重复 KEY,在 MySQL 8.0.3 之前,遵循 first duplicate key wins 原则,会保留第一个 KEY,后面的将被丢弃掉。
从 MySQL 8.0.3 开始,遵循的是 last duplicate key wins 原则,只会保留最后一个 KEY。
查询
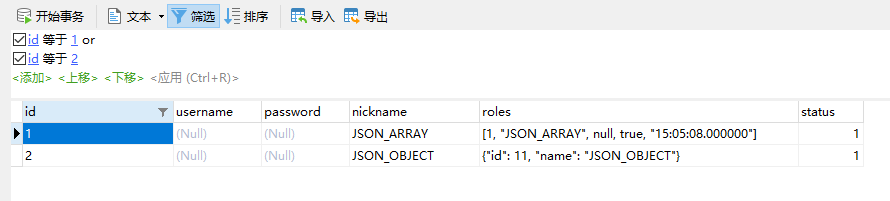
JSON_ARRAYAGG()和JSON_OBJECTAGG()将查询结果封装成json
# 将字段值,组装成 JSON ARRAYAGG 格式
SELECT id,nickname,JSON_ARRAYAGG(nickname) FROM demo GROUP BY id
# 将字段值,组装成 JSON_OBJECTAGG 格式
SELECT id,nickname,JSON_OBJECTAGG(id,nickname) FROM demo GROUP BY id
CAST()将字符串转成json
转了以后就不带\转义字符了
set @j = '{"a": 1, "b": [2, 3], "a c": 4}';
-- {"a": "{\"qq\": 22, \"ww\": 33}", "b": [2, 3], "a c": 4}
select JSON_SET(@j, '$.a', '{"qq": 22, "ww": 33}');
-- {"a": {"qq": 22, "ww": 33}, "b": [2, 3], "a c": 4}
select JSON_SET(@j, '$.a', CAST('{"qq": 22, "ww": 33}' as JSON));
JSON类型的解析
JSON_EXTRACT()解析json
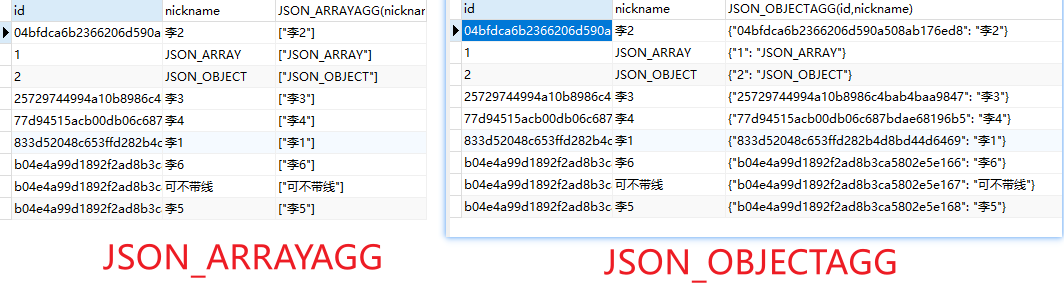
其中,JSON_doc 是 JSON 文档,path 是路径。该函数会从 JSON 文档提取指定路径(path)的元素。如果指定 path 不存在,会返回 NULL。可指定多个 path,匹配到的多个值会以数组形式返回。
非list
-- 解析数组
-- 取下标为1的数组值(数组下标从0开始),结果:20
SELECT JSON_EXTRACT('[10, 20, [30, 40]]', '$[1]');
-- 取多个,结果返回是一个数组,结果:[20, 10]
SELECT JSON_EXTRACT('[10, 20, [30, 40]]', '$[1]', '$[0]');
-- 可以使用*获取全部,结果:[30, 40]
SELECT JSON_EXTRACT('[10, 20, [30, 40]]', '$[2][*]');
-- 还可通过 [M to N] 获取数组的子集
-- 结果:[10, 20]
select JSON_EXTRACT('[10, 20, [30, 40]]', '$[0 to 1]');
-- 这里的 last 代表最后一个元素的下标,结果:[20, [30, 40]]
select JSON_EXTRACT('[10, 20, [30, 40]]', '$[last-1 to last]');
-- 解析对象:对象的路径是通过 KEY 来表示的。
set @j='{"a": 1, "b": [2, 3], "a c": 4}';
-- 如果 KEY 在路径表达式中不合法(譬如存在空格),则在引用这个 KEY 时,需用双引号括起来。
-- 结果: 1 4 3
select json_extract(@j, '$.a'), json_extract(@j, '$."a c"'), json_extract(@j, '$.b[1]');
-- 使用*获取所有元素,结果:[1, [2, 3], 4]
select json_extract('{"a": 1, "b": [2, 3], "a c": 4}', '$.*');
-- 这里的 $**.b 匹配 $.a.b 和 $.c.b,结果:[1, 2]
select json_extract('{"a": {"b": 1}, "c": {"b": 2}}', '$**.b');
json_extract解析出来的数据,可以灵活用于where、order by等等所有地方。
-> 箭头函数解析json
column->path,包括后面讲到的 column->>path,都是语法糖,在实际使用的时候都会在底层自动转化为 JSON_EXTRACT。
column->path 等同于 JSON_EXTRACT(column, path) ,只能指定一个path。
# roles -> '$.name' 会自动解析成 JSON_EXTRACT(roles,'$.name')
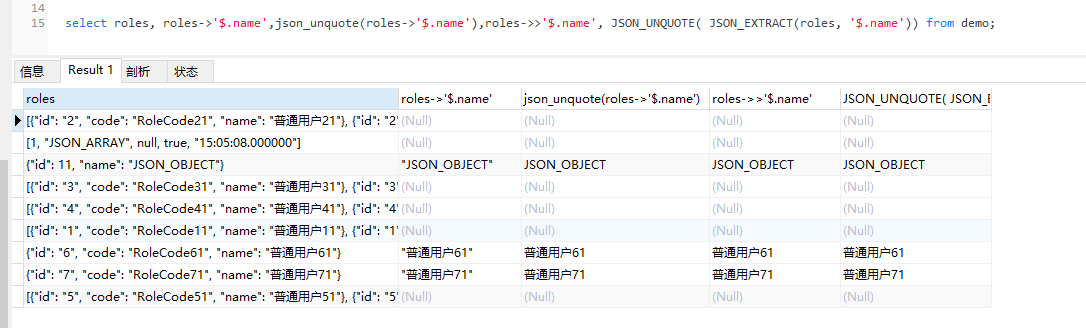
select roles,JSON_EXTRACT(roles,'$.name'), roles -> '$.name' from demo;
JSON_QUOTE()引用与JSON_UNQUOTE()取消引用
JSON_QUOTE(string),生成有效的 JSON 字符串,主要是对一些特殊字符(如双引号)进行转义。
-- 结果:"null" "\"null\"" "[1, 2, 3]"
select json_quote('null'), json_quote('"null"'), json_quote('[1, 2, 3]');
JSON_UNQUOTE(json_val),将 JSON 转义成字符串输出。常用于使用JSON_EXTRACT()和->函数解析完之后,去除引号。
JSON_UNQUOTE()特殊字符转义表:
转义序列由序列表示的字符
| 转义序列 | 由序列表示的字符 |
|---|---|
| \" | 双引号 |
| \b | 退格字符 |
| \f | 换页字符 |
| \n | 换行符 |
| \r | 回车符 |
| \t | 制表符 |
| \\ | 反斜杠()字符 |
| \uXXXX | Unicode XXXX 转UTF-8 |
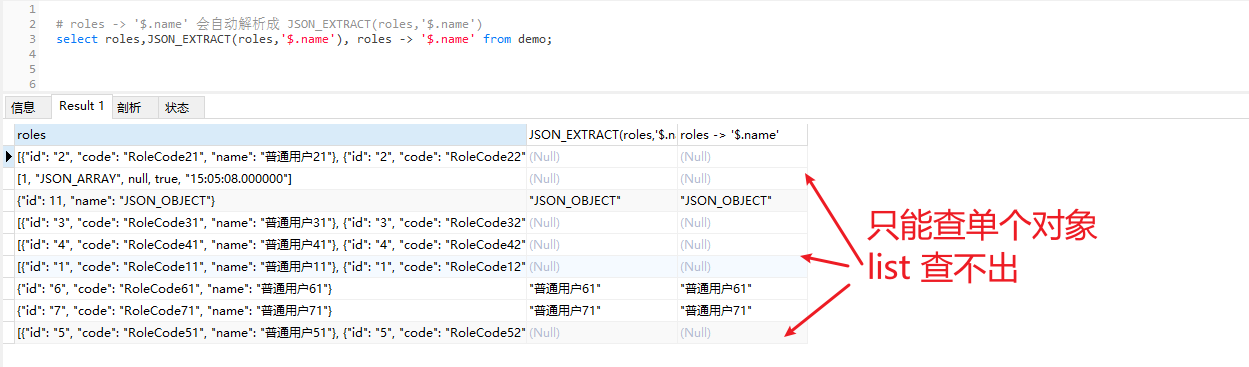
-- 字符串类型转换后会去掉引号,结果:"jack" jack 1 0
-- 数字类型不会有额外效果
select roles, roles->'$.name',json_unquote(roles->'$.name'),json_valid(roles->'$.name'),json_valid(json_unquote(roles->'$.name')) from demo;
直观地看,没加 JSON_UNQUOTE 字符串会用双引号引起来,加了 JSON_UNQUOTE 就没有。但本质上,前者是 JSON 中的 STRING 类型,后者是 MySQL 中的字符类型,这一点可通过 JSON_VALID 来判断。
->>箭头解析json
同 column->path 类似,只不过其返回的是字符串,相当于将字符串的双引号去掉了,是一个语法糖,本质上是执行了JSON_UNQUOTE( JSON_EXTRACT(column, path) )。
以下三者是等价的:
- JSON_UNQUOTE( JSON_EXTRACT(column, path) )
- JSON_UNQUOTE(column -> path)
- column->>path
select roles, roles->'$.name',json_unquote(roles->'$.name'),roles->>'$.name', JSON_UNQUOTE( JSON_EXTRACT(roles, '$.name')) from demo;
JSON类型的查询
JSON_CONTAINS()判断是否包含
判断 target 文档是否包含 candidate 文档,包含的话返回1,不包含的话返回0
如果带了path,就判断path中的数据是否等于candidate,等于的话返回1,不等于的话返回0
函数前加not可取反
SET @j = '{"a": 1, "b": 2, "c": {"d": 4}}';
SET @j2 = '{"a":1}';
-- 判断@j中是否包含@j2,结果:1
SELECT JSON_CONTAINS(@j, @j2);
SET @j2 = '1';
-- 判断@j字段中的a是否等于1,结果:1
SELECT JSON_CONTAINS(@j, @j2, '$.a');
-- 结果:0
SELECT JSON_CONTAINS(@j, @j2, '$.b');
SET @j2 = '{"d": 4}';
-- 结果:0
SELECT JSON_CONTAINS(@j, @j2, '$.a');
-- 结果:1
SELECT JSON_CONTAINS(@j, @j2, '$.c');
SET @j = '[1, "a", 1.02]';
SET @j2 = '"a"';
-- 判断@j数组中是否包含@j2,结果:1
SELECT JSON_CONTAINS(@j, @j2);
JSON_CONTAINS_PATH()判断
格式:JSON_CONTAINS_PATH(JSON_doc, one_or_all, path[, path] …)
判断指定的 path 是否存在,存在,则返回 1,否则是 0。
函数中的 one_or_all 可指定 one 或 all,one 是任意一个路径存在就返回 1,all 是所有路径都存在才返回 1。
SET @j = '{"a": 1, "b": 2, "c": {"d": 4}}';
-- a或者e 存在一个就返回1,结果:1
SELECT JSON_CONTAINS_PATH(@j, 'one', '$.a', '$.e');
-- a和e都存在返回1,结果:0
SELECT JSON_CONTAINS_PATH(@j, 'all', '$.a', '$.e');
-- c中的d存在返回1,结果:1
SELECT JSON_CONTAINS_PATH(@j, 'one', '$.c.d');
SET @j = '[1, 4, "a", "c"]';
-- @j是一个数组,$[1]判断第二个数据是否存在,结果为1
select JSON_CONTAINS_PATH(@j, 'one', '$[1]');
-- $[11]判断第11个数据不存在,结果为0
select JSON_CONTAINS_PATH(@j, 'one', '$[11]');
JSON_KEYS()获取keys
返回 JSON 文档最外层的 key,如果指定了 path,则返回该 path 对应元素最外层的 key。
-- 结果:["a", "b"]
SELECT JSON_KEYS('{"a": 1, "b": {"c": 30}}');
-- 结果:["c"]
SELECT JSON_KEYS('{"a": 1, "b": {"c": 30}}', '$.b');
JSON_OVERLAPS()比较两个json
MySQL 8.0.17 引入的,用来比较两个 JSON 文档是否有相同的键值对或数组元素,如果有,则返回 1,否则是 0。 如果两个参数都是标量,则判断这两个标量是否相等。
-- 结果: 1 0
select json_overlaps('[1,3,5,7]', '[2,5,7]'),json_overlaps('[1,3,5,7]', '[2,6,8]');
-- 部分匹配被视为不匹配,结果:0
SELECT JSON_OVERLAPS('[[1,2],[3,4],5]', '[1,[2,3],[4,5]]');
-- 比较对象时,如果它们至少有一个共同的键值对,则结果为真。
-- 结果:1
SELECT JSON_OVERLAPS('{"a":1,"b":10,"d":10}', '{"c":1,"e":10,"f":1,"d":10}');
-- 结果:0
SELECT JSON_OVERLAPS('{"a":1,"b":10,"d":10}', '{"a":5,"e":10,"f":1,"d":20}');
-- 如果两个标量用作函数的参数,JSON_OVERLAPS()会执行一个简单的相等测试:
-- 结果:1
SELECT JSON_OVERLAPS('5', '5');
-- 结果:0
SELECT JSON_OVERLAPS('5', '6');
-- 当比较标量和数组时,JSON_OVERLAPS()试图将标量视为数组元素。在此示例中,第二个参数6被解释为[6],如下所示:结果:1
SELECT JSON_OVERLAPS('[4,5,6,7]', '6');
-- 该函数不执行类型转换:
-- 结果:0
SELECT JSON_OVERLAPS('[4,5,"6",7]', '6');
-- 结果:0
SELECT JSON_OVERLAPS('[4,5,6,7]', '"6"');
JSON_SEARCH()返回字符串的位置
格式:JSON_SEARCH(JSON_doc, one_or_all, search_str[, escape_char[, path] …])
返回某个字符串(search_str)在 JSON 文档中的位置,其中,
one_or_all:匹配的次数,one 是只匹配一次,all 是匹配所有。如果匹配到多个,结果会以数组的形式返回。
search_str:子串,支持模糊匹配:% 和 _ 。
escape_char:转义符,如果该参数不填或为 NULL,则取默认转义符\。
path:查找路径。
SET @j = '["abc", [{"k": "10"}, "def"], {"x":"abc"}, {"y":"bcd"}]';
-- 结果:"$[0]"
SELECT JSON_SEARCH(@j, 'one', 'abc');
-- 结果:["$[0]", "$[2].x"]
SELECT JSON_SEARCH(@j, 'all', 'abc');
-- 结果:null
SELECT JSON_SEARCH(@j, 'all', 'ghi');
-- 结果:"$[1][0].k"
SELECT JSON_SEARCH(@j, 'all', '10');
-- 结果:"$[1][0].k"
SELECT JSON_SEARCH(@j, 'all', '10', NULL, '$');
-- 结果:"$[1][0].k"
SELECT JSON_SEARCH(@j, 'all', '10', NULL, '$[*]');
-- 结果:"$[1][0].k"
SELECT JSON_SEARCH(@j, 'all', '10', NULL, '$**.k');
-- 结果:"$[1][0].k"
SELECT JSON_SEARCH(@j, 'all', '10', NULL, '$[*][0].k');
-- 结果:"$[1][0].k"
SELECT JSON_SEARCH(@j, 'all', '10', NULL, '$[1]');
-- 结果:"$[1][0].k"
SELECT JSON_SEARCH(@j, 'all', '10', NULL, '$[1][0]');
-- 结果:"$[2].x"
SELECT JSON_SEARCH(@j, 'all', 'abc', NULL, '$[2]');
-- 结果:["$[0]", "$[2].x"]
SELECT JSON_SEARCH(@j, 'all', '%a%');
-- 结果:["$[0]", "$[2].x", "$[3].y"]
SELECT JSON_SEARCH(@j, 'all', '%b%');
-- 结果:"$[0]"
SELECT JSON_SEARCH(@j, 'all', '%b%', NULL, '$[0]');
-- 结果:"$[2].x"
SELECT JSON_SEARCH(@j, 'all', '%b%', NULL, '$[2]');
-- 结果:null
SELECT JSON_SEARCH(@j, 'all', '%b%', NULL, '$[1]');
-- 结果:null
SELECT JSON_SEARCH(@j, 'all', '%b%', '', '$[1]');
-- 结果:"$[3].y"
SELECT JSON_SEARCH(@j, 'all', '%b%', '', '$[3]');
JSON_VALUE()提取指定路径的元素
8.0.21 引入的,从 JSON 文档提取指定路径(path)的元素。
完整的语法如下所示:
JSON_VALUE(json_doc, path [RETURNING type] [on_empty] [on_error])
on_empty:
{NULL | ERROR | DEFAULT value} ON EMPTY
on_error:
{NULL | ERROR | DEFAULT value} ON ERROR
Json List 查询
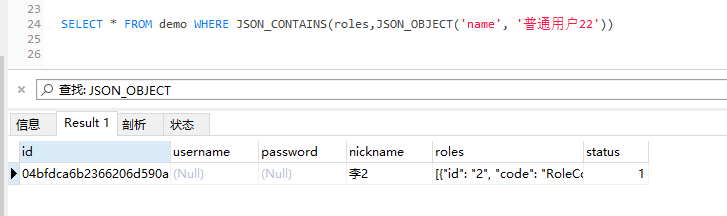
# 先通过 JSON_OBJECT('name', '普通用户22') 拼出 {"name": "普通用户22"}
# 再通过 JSON_CONTAINS(字段,需要包括的内容)
SELECT * FROM demo3 WHERE JSON_CONTAINS(roles,JSON_OBJECT('name', '普通用户22'))
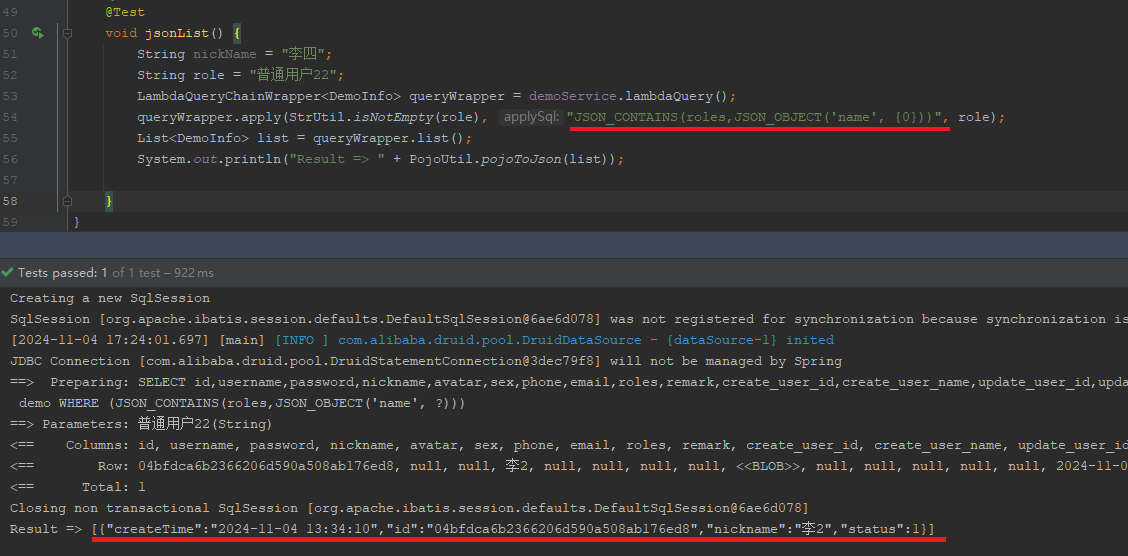
@Test
void jsonList() {
String nickName = "李四";
String role = "普通用户22";
LambdaQueryChainWrapper<DemoInfo> queryWrapper = demoService.lambdaQuery();
queryWrapper.apply(StrUtil.isNotEmpty(role), "JSON_CONTAINS(roles,JSON_OBJECT('name', {0}))", role);
List<DemoInfo> list = queryWrapper.list();
System.out.println("Result => " + PojoUtil.pojoToJson(list));
}
本文来自博客园,作者:VipSoft 转载请注明原文链接:https://www.cnblogs.com/vipsoft/p/18525621

 浙公网安备 33010602011771号
浙公网安备 33010602011771号