数据标注工具 doccano | 命名实体识别(Named Entity Recognition,简称NER)
命名实体识别(Named Entity Recognition,简称NER),是指识别文本中具有特定意义的实体。在开放域信息抽取中,抽取的类别没有限制,用户可以自己定义。
安装
详见:数据标注工具 doccano | 文本分类(Text Classification)
数据准备
上传的文件为txt格式,每一行为一条待标注文本,示例:
corpus.txt 随便找了几个,一般都是垂直领域的数据标注
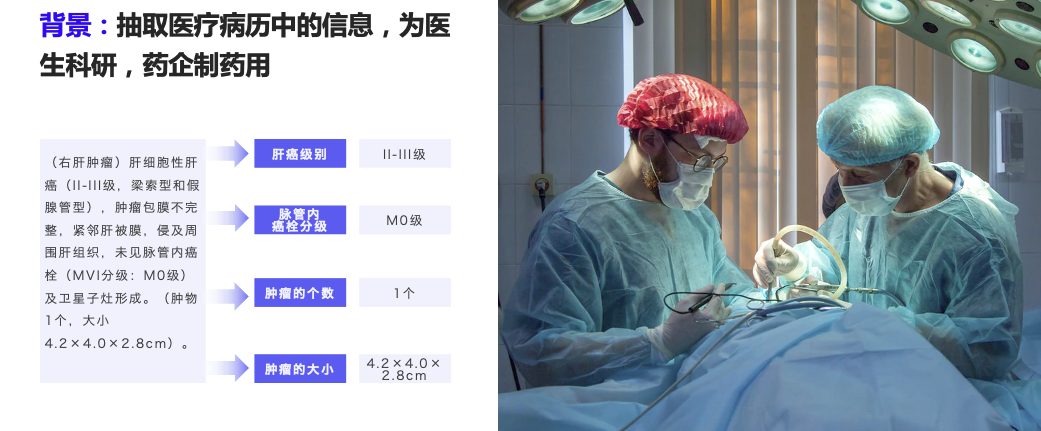
(右肝肿瘤)肝细胞性肝癌(II-III级,梁索型和假腺管型),肿瘤包膜不完整,紧邻肝被膜,侵及周围肝组织,未见脉管内癌栓(MVI分级:M0级)及卫星子灶形成。(肿物1个,大小4.2×4.0×2.8cm)。
患者20天前无明显诱因出现左侧胸背部持续性疼痛,于2025.02.01下城区中西医结合医院查胸部CT平扫示:右下肺少许炎症;肺气肿;慢性胰腺炎;建议追踪复查
双肺透亮度可,左下肺背段见一类圆开/结节影,大小约27X28mm,周围可见片状密度增高影,病变局部与胸膜粘连
创建项目
UIE 支持抽取与分类两种类型的任务,根据实际需要创建一个新的项目:
创建抽取式任务
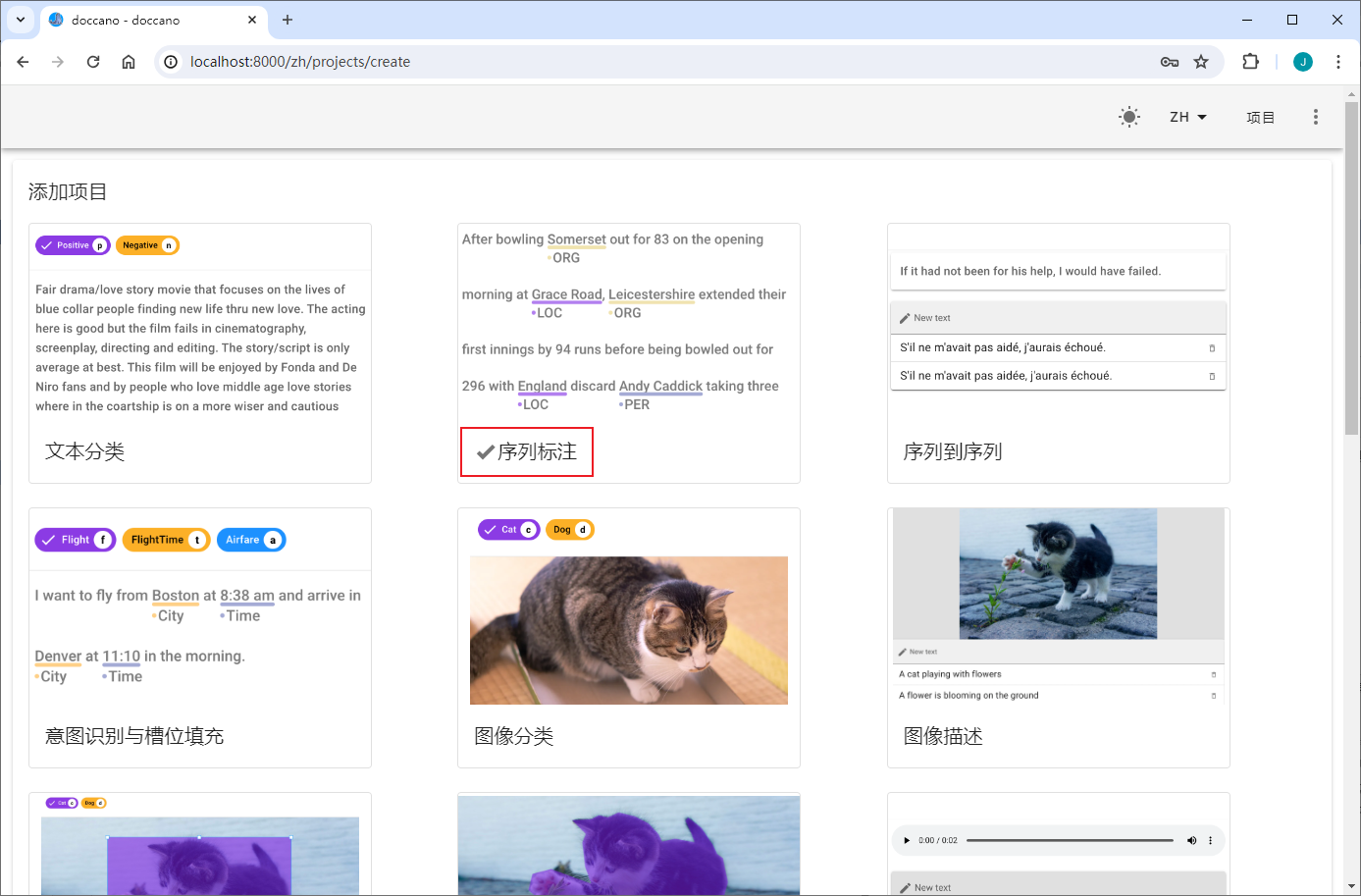
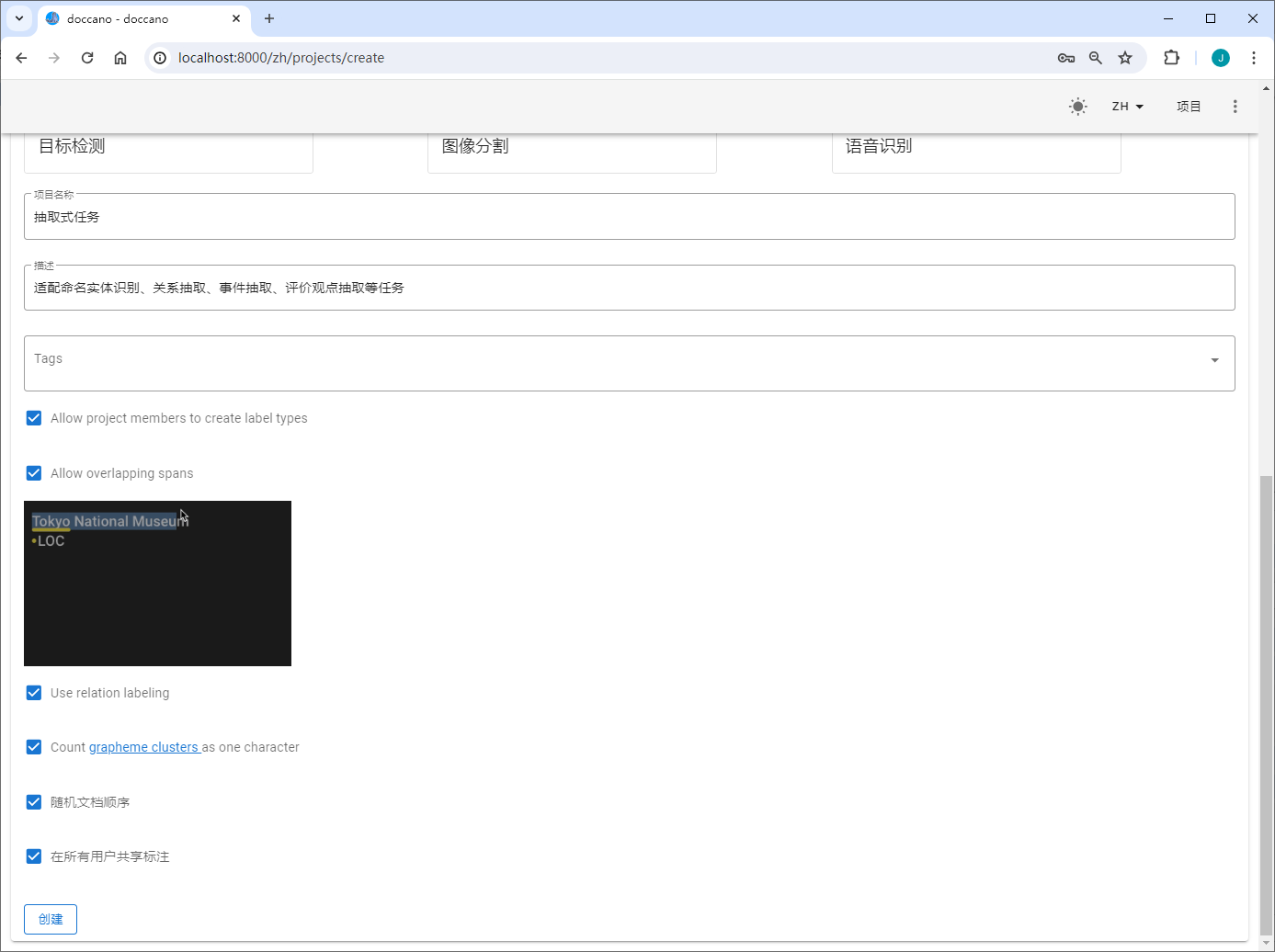
上传
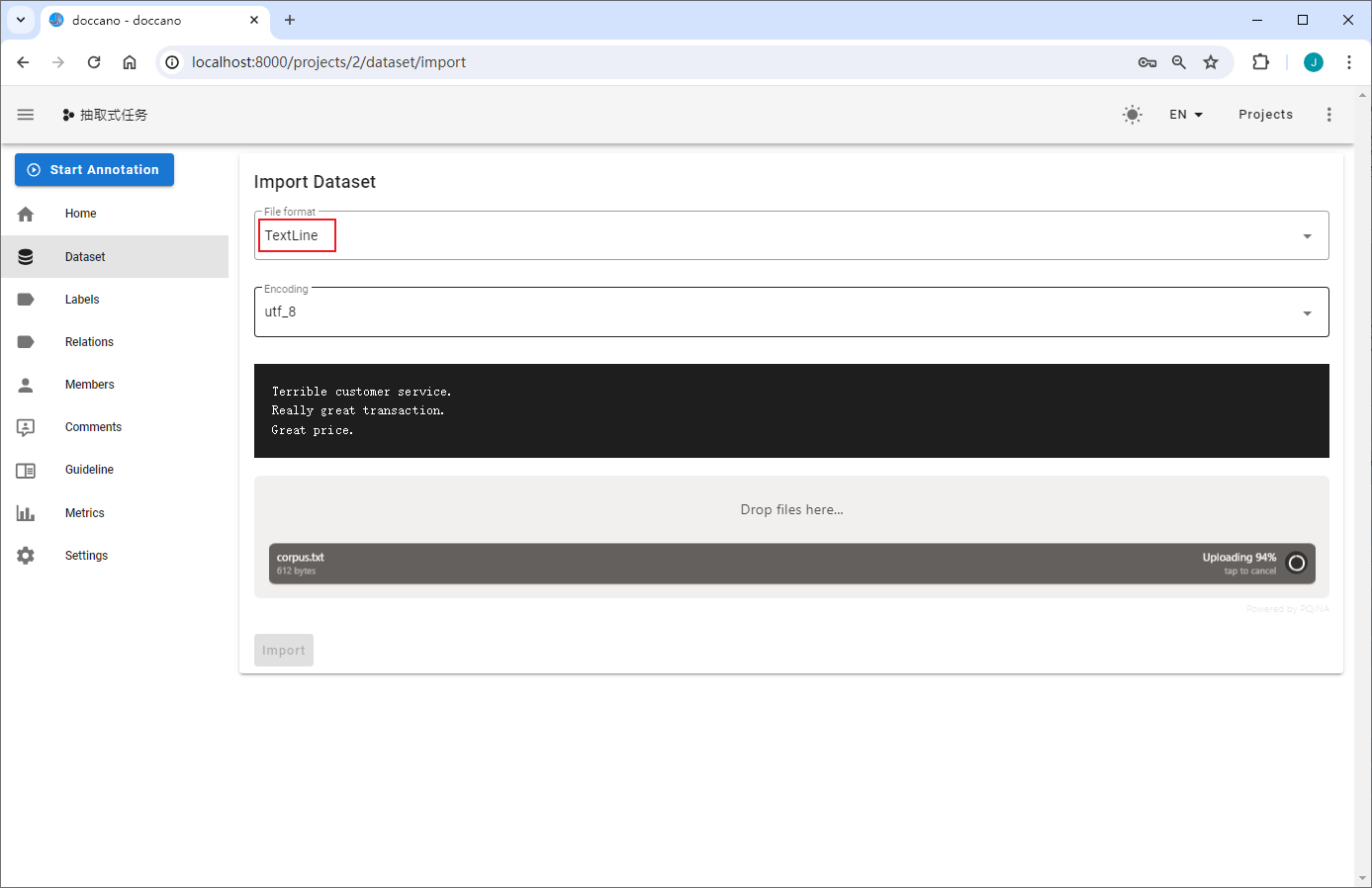
NOTE:doccano支持TextFile、TextLine、JSONL和CoNLL四种数据上传格式,UIE定制训练中统一使用TextLine这一文件格式,即上传的文件需要为txt格式,且在数据标注时,该文件的每一行待标注文本显示为一页内容。
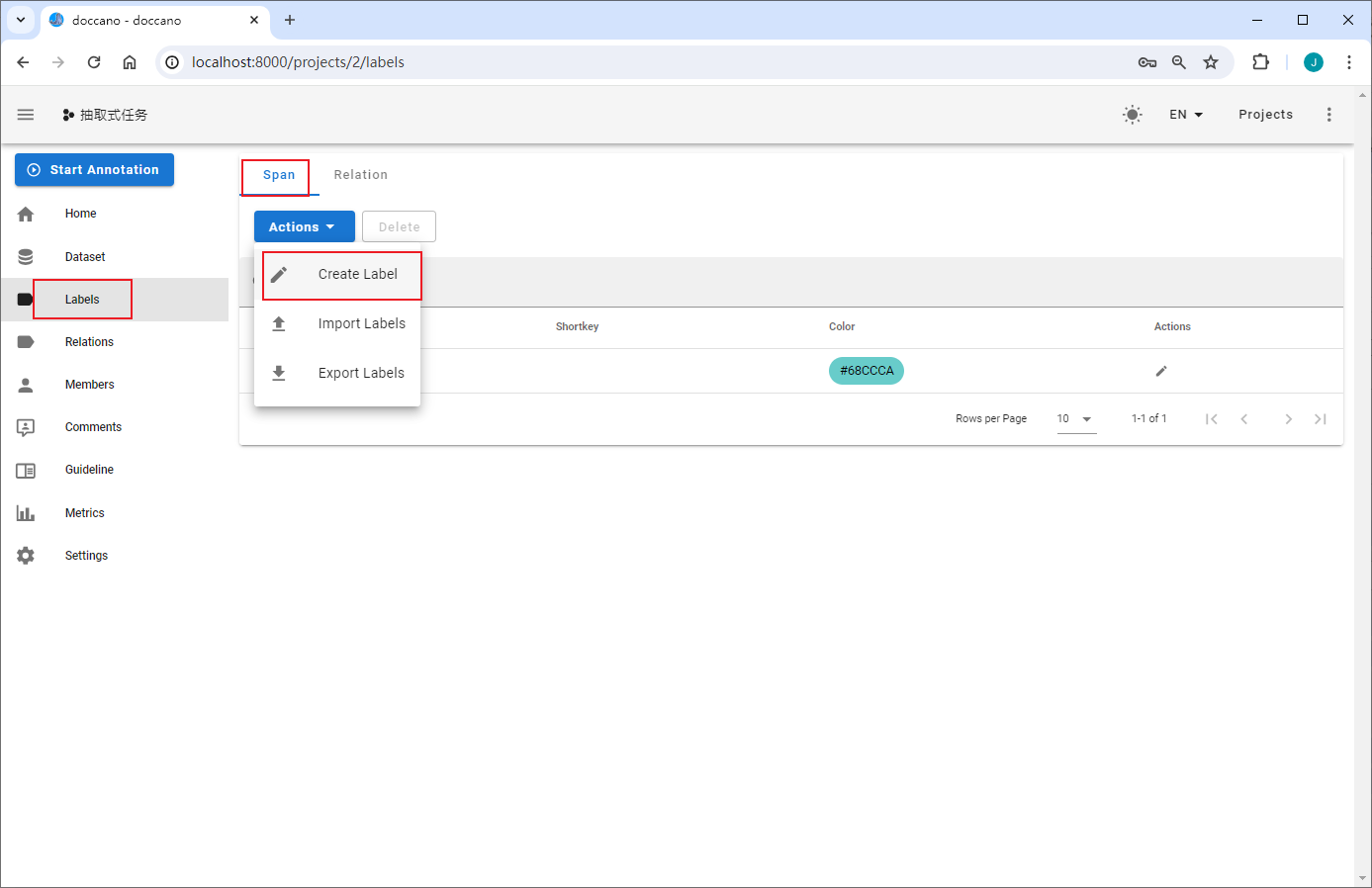
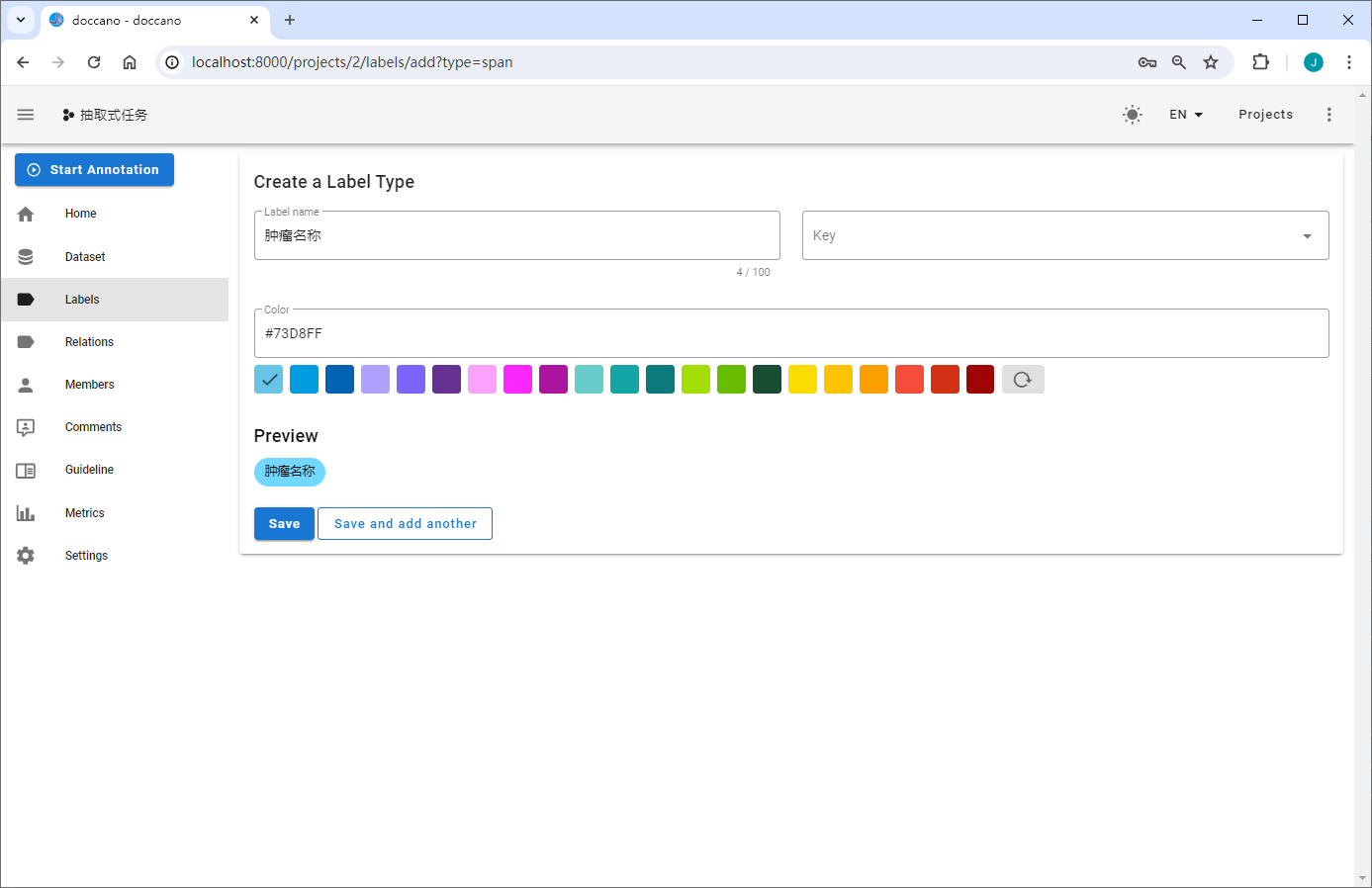
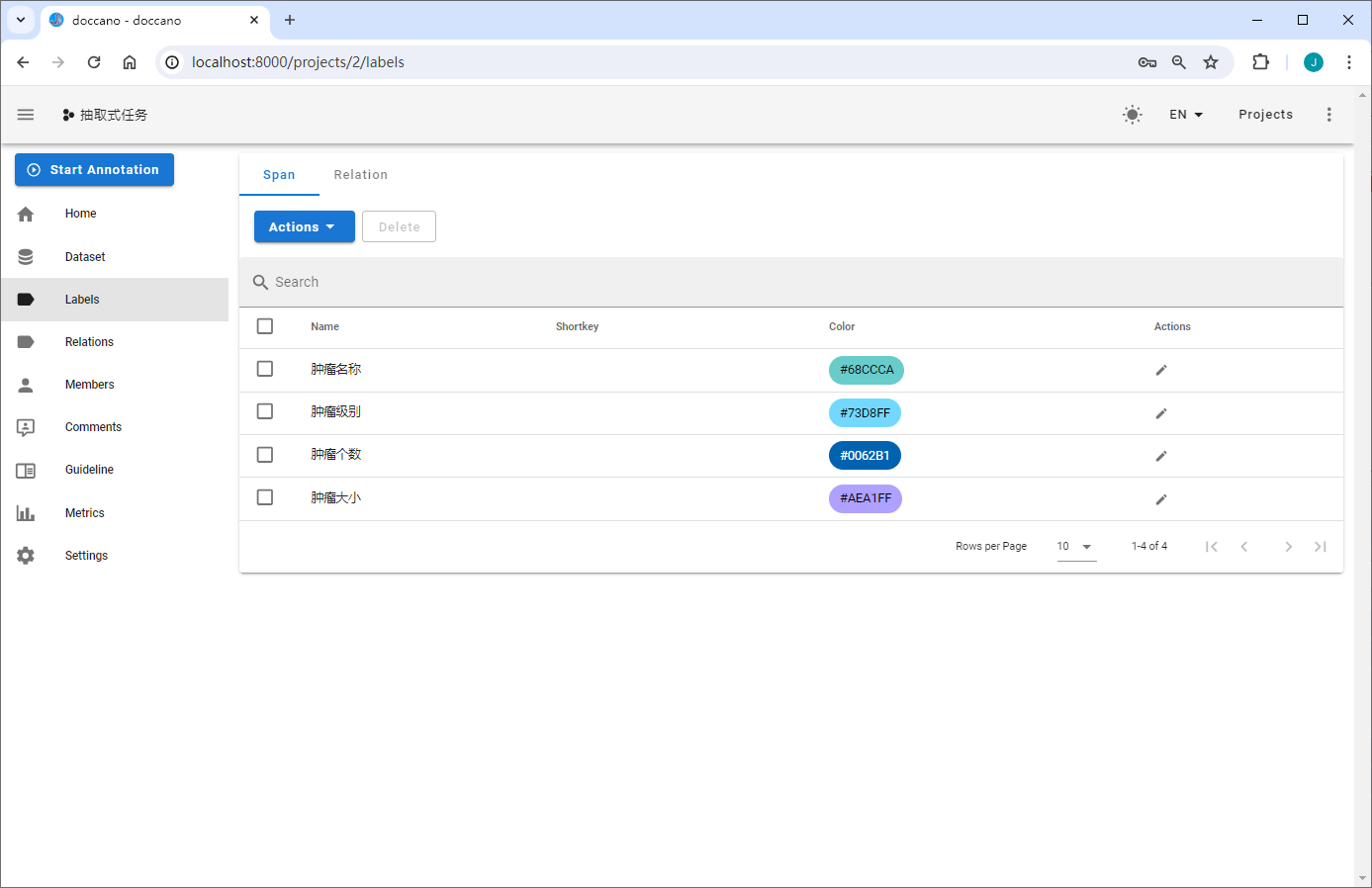
定义标签
构建抽取式任务标签
抽取式任务包含Span与Relation两种标签类型,Span指原文本中的目标信息片段,如实体识别中某个类型的实体,事件抽取中的触发词和论元;Relation指原文本中Span之间的关系,如关系抽取中两个实体(Subject&Object)之间的关系,事件抽取中论元和触发词之间的关系。
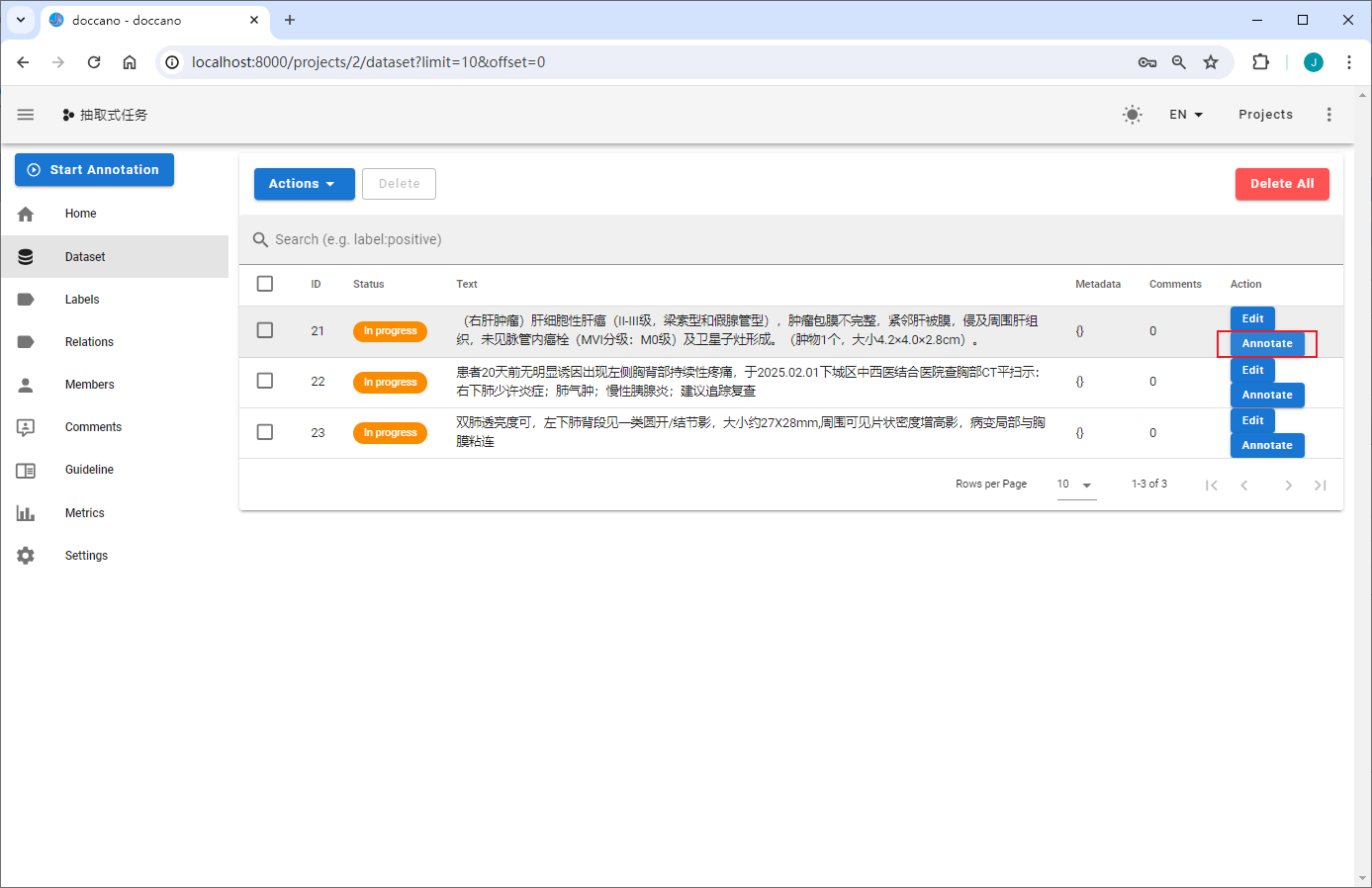
以 corpus.txt 中的第一条数据为例(医疗场景-专病结构化):
任务标注
命名实体识别
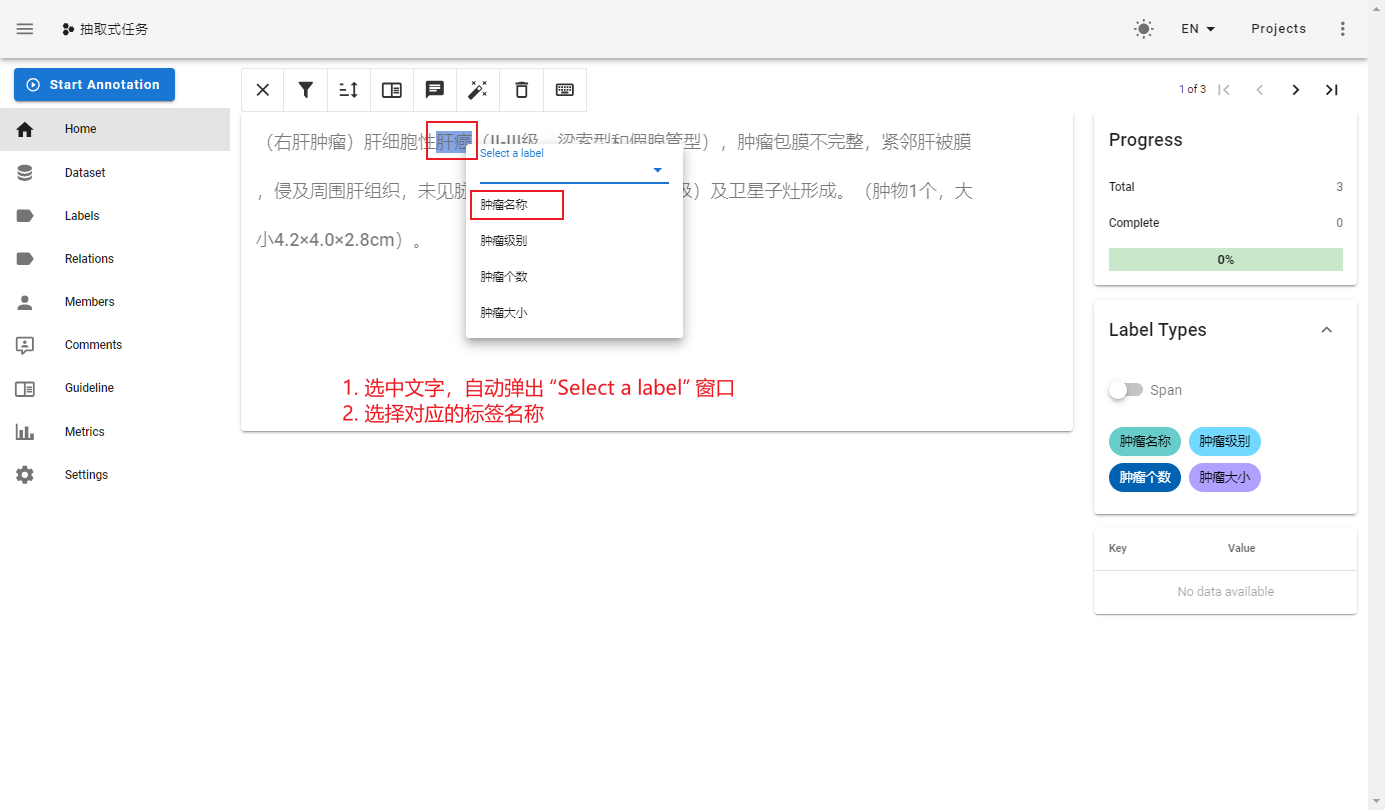
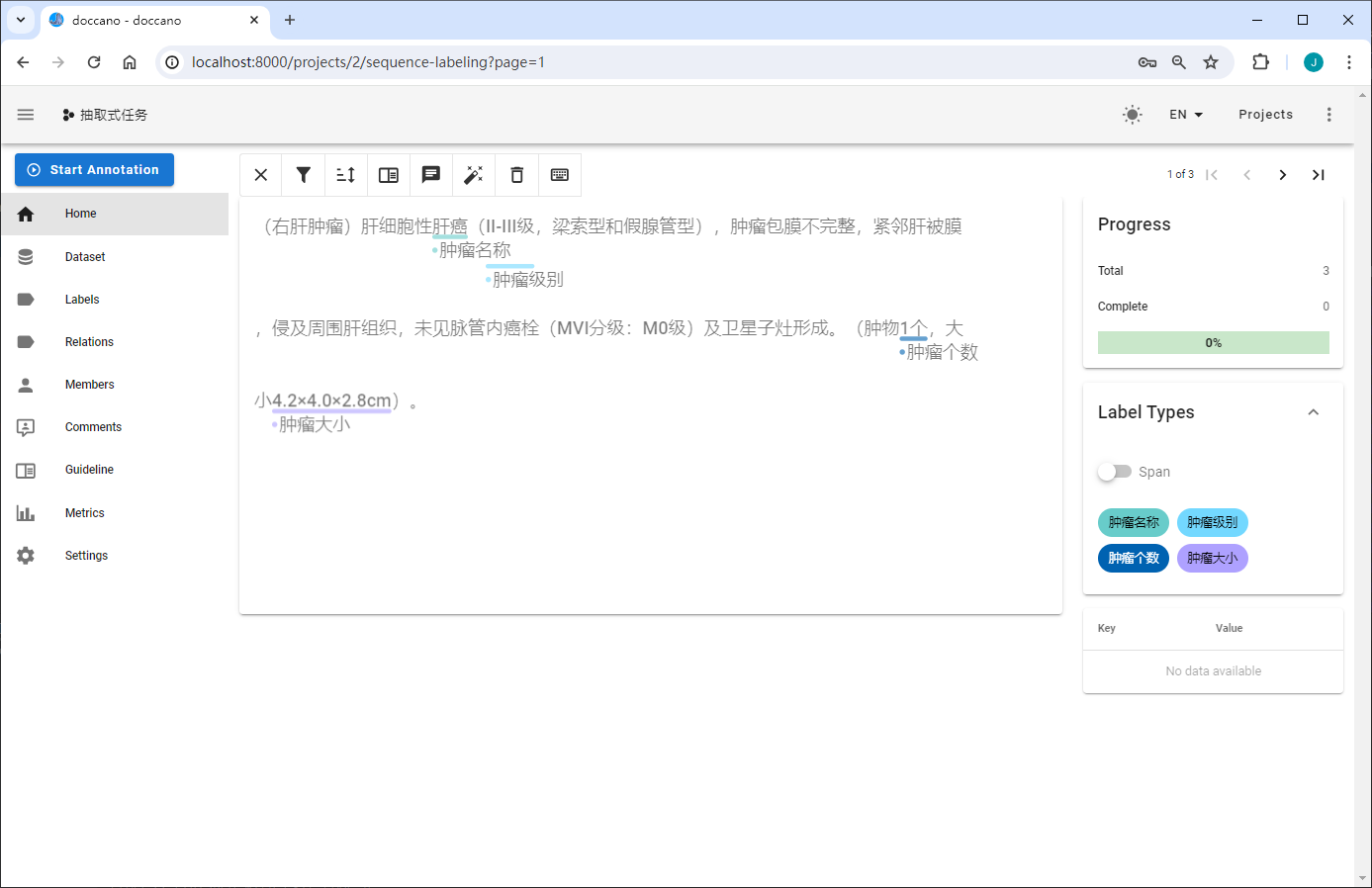
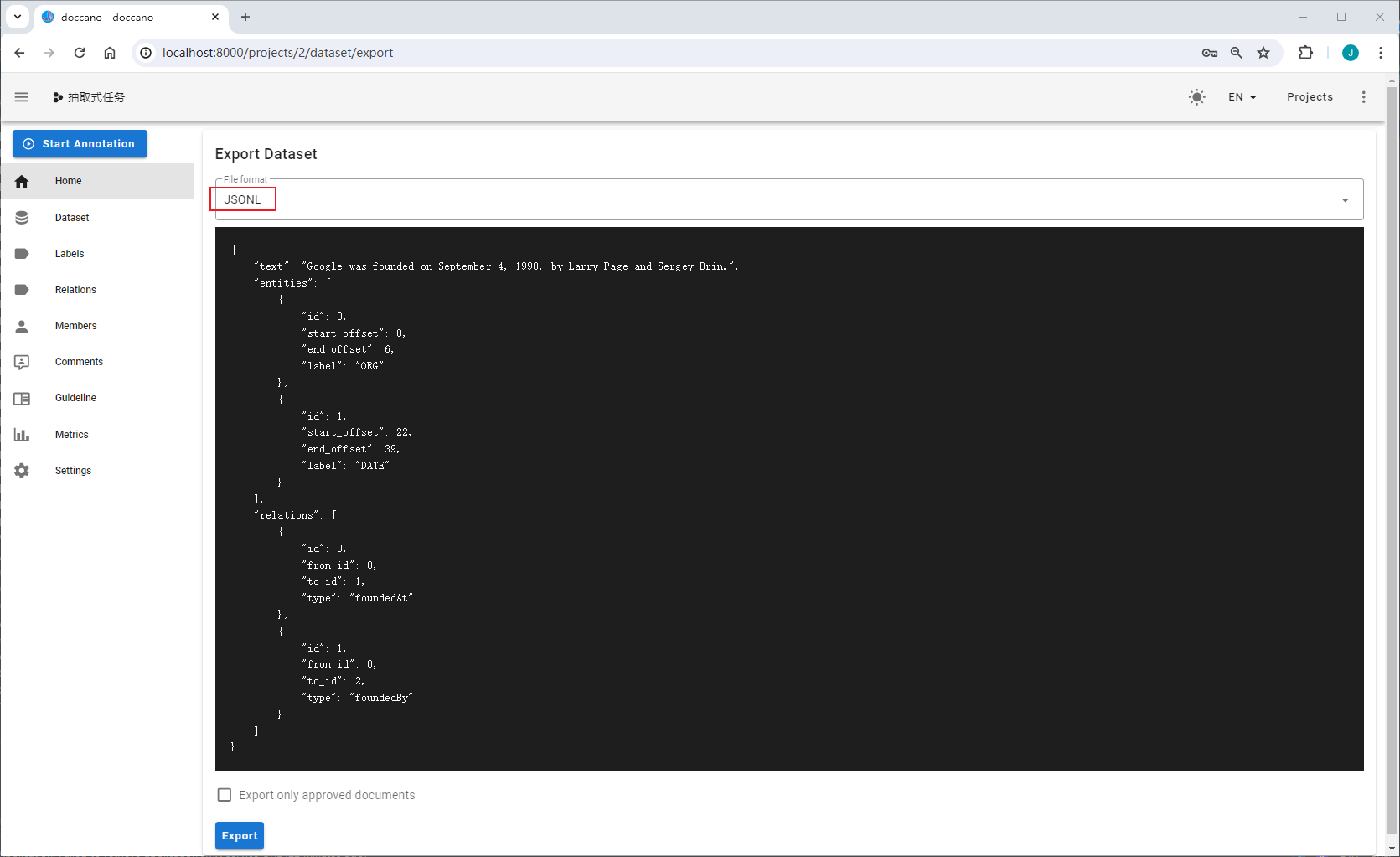
导出数据
选择导出的文件类型为JSONL(relation),导出数据示例:
查看数据
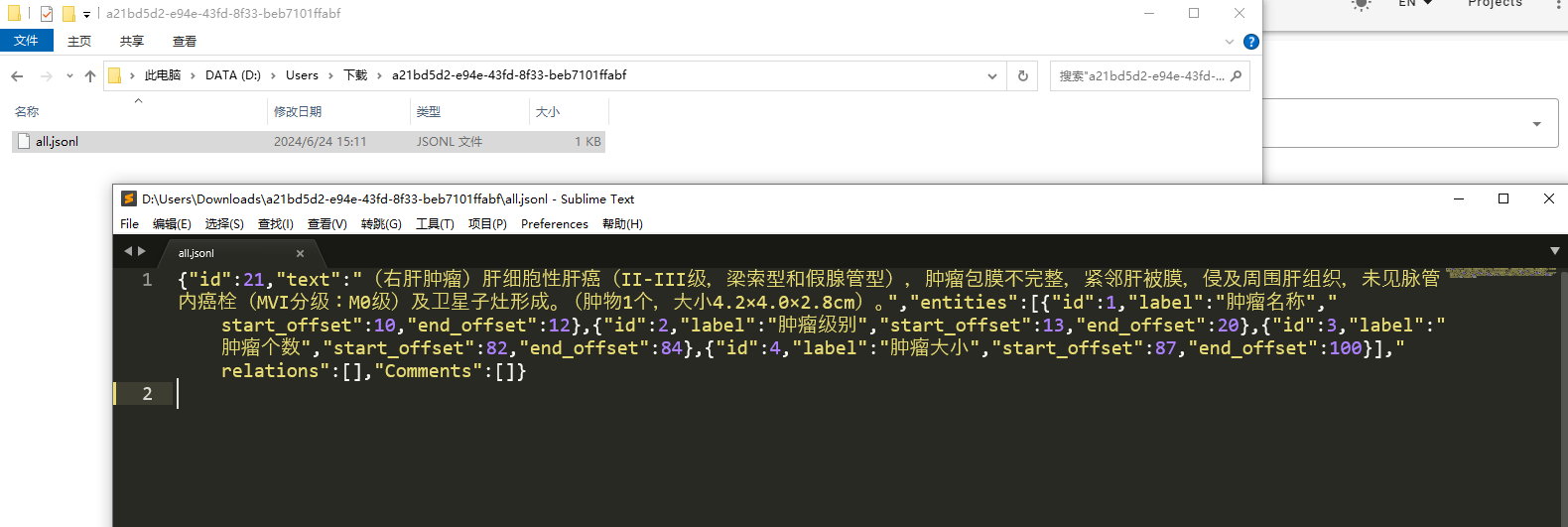
标注数据保存在同一个文本文件中,每条样例占一行且存储为json格式,其包含以下字段
id: 样本在数据集中的唯一标识ID。text: 原始文本数据。entities: 数据中包含的Span标签,每个Span标签包含四个字段:id: Span在数据集中的唯一标识ID。start_offset: Span的起始token在文本中的下标。end_offset: Span的结束token在文本中下标的下一个位置。label: Span类型。
relations: 数据中包含的Relation标签,每个Relation标签包含四个字段:id: (Span1, Relation, Span2)三元组在数据集中的唯一标识ID,不同样本中的相同三元组对应同一个ID。from_id: Span1对应的标识ID。to_id: Span2对应的标识ID。type: Relation类型。
应用实例
本文来自博客园,作者:VipSoft 转载请注明原文链接:https://www.cnblogs.com/vipsoft/p/18258382

 浙公网安备 33010602011771号
浙公网安备 33010602011771号