HanLP — 词性标注
词性(Part-Of-Speech,POS)指的是单词的语法分类,也称为词类。同一个类别的词语具有相似的语法性质
所有词性的集合称为词性标注集。
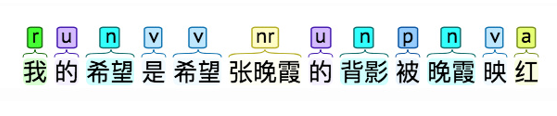
词性的用处
当下游应用遇到OOV时,可以通过OOV的词性猜测用法词性也可以直接用于抽取一些信息,比如抽取所有描述特定商品的形容词等
词性标注
词性标注指的是为句子中每个单词预测一个词性标签的任务
- 汉语中一个单词多个词性的现象很常见(称作兼类词)
- OOV是任何自然语言处理任务的难题
词性标注模型
联合模型
同时进行多个任务的模型称为联合模型(joint model)
商 B-名词
品 E-名词
和 S-连词
服 B-名词
务 E-名词
流水线式
中文分词语料库远远多于词性标注语料库
实际工程上通常在大型分词语料库上训练分词器
然后与小型词性标注语料库上的词性标注模型灵活组合为一个异源的流水线式词法分析器
词性标注语料库与标注集
目前还没有一个被广泛接受的汉语词性划分标准
本节选取其中一些授权宽松,容易获得的语料库作为案例,介绍其规模、标注集等特点
《人民日报》语料库与PKU标注集
http://file.hankcs.com/corpus/pku98.zip
https://www.fujitsu.com/cn/about/resources/news/press-releases/2001/0829.html
语料库中的一句样例为:
1997年/t 12月/t 31日/t 午夜/t ,/w 聚集/v 在/p 日本/ns 东京/ns 增上寺/ns 的/u 善男信女/i 放飞/v 气球/n ,/w 祈祷/v 新年/t 好运/n 。
国家语委语料库与863标注集
国家语言文字工作委员会建设的大型语料库
国家语委语料库的标注规范《信息处理用现代汉语词类标记集规范》在2006年成为国家标准
其词类体系分为20个一级类、29个二级类
《诛仙》语料库与CTB标注集
哈工大张梅山老师公开了网络小说《诛仙》上的标注语料
远处/NN ,/PU 小竹峰/NR 诸/DT 人/NN 处/NN ,/PU 陆雪琪/NR 缓缓/AD 从/P 张小凡/NR 身上/NN 收回/VV 目光/NN ,/PU 落到/VV 了/AS 前方/NN 碧瑶/NR 的/DEG 身上/NN ,/PU 默默/AD 端详/VV 著/AS 她/PN 。/PU
《诛仙》语料库采用的标注集与CTB(Chinese Treebank,中文树库)相同,一共33种词类
序列标注模型应用于词性标注
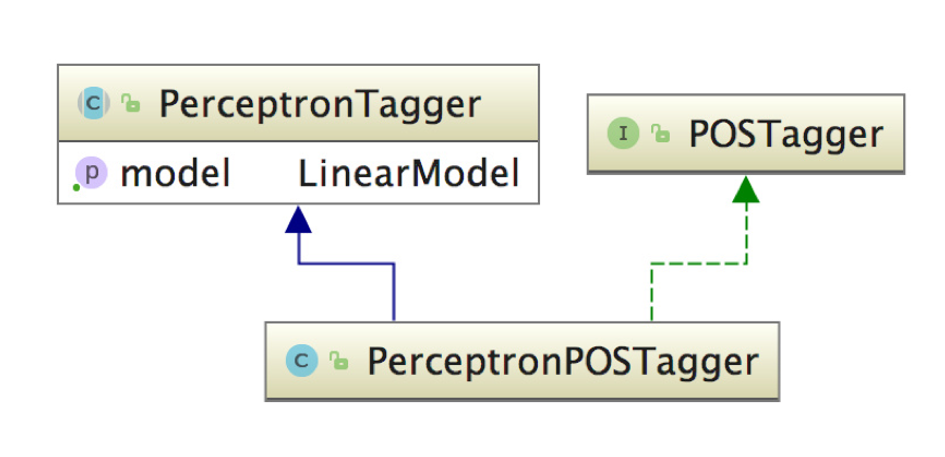
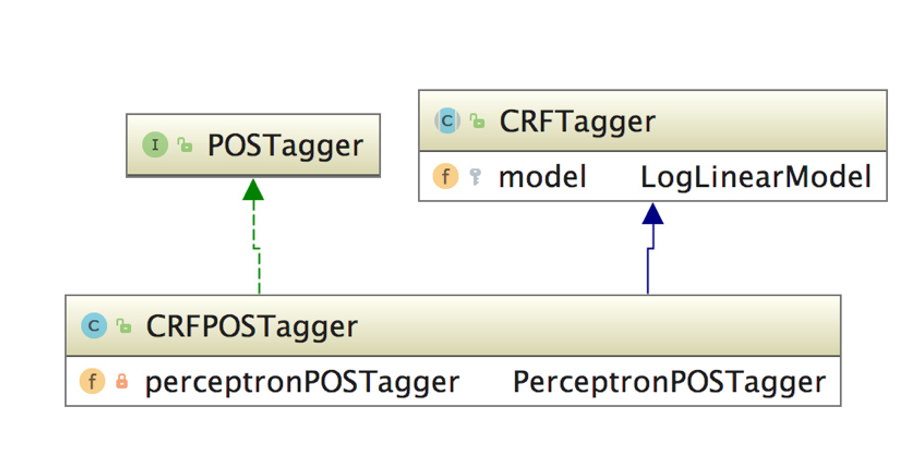
HanLP中词性标注由POSTagger接口提供
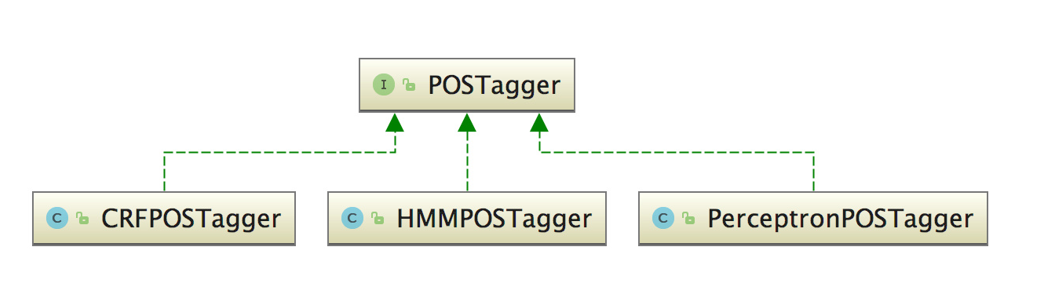
训练集转换成 Sentence 对像
IOUtility.loadInstance
/**
* 将语料库中每行文字,字符、词性,转换成 Sentence,由具体的实现类去做 handler.process 处理
* @param path
* @param handler
* @return
* @throws IOException
*/
public static int loadInstance(final String path, InstanceHandler handler) throws IOException {
ConsoleLogger logger = new ConsoleLogger();
int size = 0;
File root = new File(path);
File allFiles[];
if (root.isDirectory()) {
allFiles = root.listFiles(new FileFilter() {
@Override
public boolean accept(File pathname) {
return pathname.isFile() && pathname.getName().endsWith(".txt");
}
});
} else {
allFiles = new File[]{root};
}
for (File file : allFiles) {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(file), "UTF-8"));
String line;
while ((line = br.readLine()) != null) {
line = line.trim();
if (line.length() == 0) {
continue;
}
//line=迈向/v 充满/v 希望/n 的/u 新/a 世纪/n ——/w 一九九八年/t 新年/t 讲话/n (/w 附/v 图片/n 1/m 张/q )/w
Sentence sentence = Sentence.create(line);
//wordList[0].value="迈向"
//wordList[0].label="v"
if (sentence.wordList.size() == 0) continue;
++size;
if (size % 1000 == 0) {
logger.err("%c语料: %dk...", 13, size / 1000);
}
// debug
// if (size == 100) break;
if (handler.process(sentence)) break;
}
}
return size;
}
基于隐马尔可夫模型的词性标注
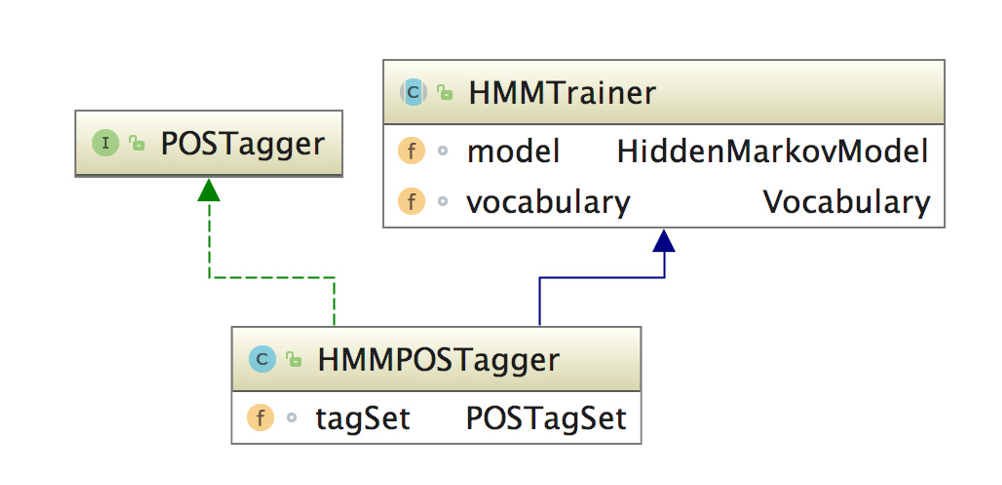
HanLP-1.7.5\src\main\java\com\hankcs\hanlp\model\hmm\HMMTrainer.java
/***
* HMM 训练
* @param corpus data/test/pku98/199801-train.txt
* @throws IOException
*/
public void train(String corpus) throws IOException
{
final List<List<String[]>> sequenceList = new LinkedList<List<String[]>>();
IOUtility.loadInstance(corpus, new InstanceHandler()
{
@Override
public boolean process(Sentence sentence)
{
sequenceList.add(convertToSequence(sentence));
return false;
}
});
TagSet tagSet = getTagSet();
List<int[][]> sampleList = new ArrayList<int[][]>(sequenceList.size());
for (List<String[]> sequence : sequenceList)
{
int[][] sample = new int[2][sequence.size()];
int i = 0;
for (String[] os : sequence)
{
sample[0][i] = vocabulary.idOf(os[0]);
assert sample[0][i] != -1;
sample[1][i] = tagSet.add(os[1]);
assert sample[1][i] != -1;
++i;
}
sampleList.add(sample);
}
model.train(sampleList);
vocabulary.mutable = false;
}
基于感知机的词性标注
/**
* 训练
*
* @param trainingFile 训练集
* @param developFile 开发集
* @param modelFile 模型保存路径
* @param compressRatio 压缩比
* @param maxIteration 最大迭代次数
* @param threadNum 线程数
* @return 一个包含模型和精度的结构
* @throws IOException
*/
public Result train(String trainingFile, String developFile,
String modelFile, final double compressRatio,
final int maxIteration, final int threadNum) throws IOException
{
if (developFile == null)
{
developFile = trainingFile;
}
// 加载训练语料
TagSet tagSet = createTagSet();
MutableFeatureMap mutableFeatureMap = new MutableFeatureMap(tagSet);
ConsoleLogger logger = new ConsoleLogger();
logger.start("开始加载训练集...\n");
Instance[] instances = loadTrainInstances(trainingFile, mutableFeatureMap);
tagSet.lock();
logger.finish("\n加载完毕,实例一共%d句,特征总数%d\n", instances.length, mutableFeatureMap.size() * tagSet.size());
// 开始训练
ImmutableFeatureMap immutableFeatureMap = new ImmutableFeatureMap(mutableFeatureMap.featureIdMap, tagSet);
mutableFeatureMap = null;
double[] accuracy = null;
if (threadNum == 1)
{
AveragedPerceptron model;
model = new AveragedPerceptron(immutableFeatureMap);
final double[] total = new double[model.parameter.length];
final int[] timestamp = new int[model.parameter.length];
int current = 0;
for (int iter = 1; iter <= maxIteration; iter++)
{
Utility.shuffleArray(instances);
for (Instance instance : instances)
{
++current;
int[] guessLabel = new int[instance.length()];
model.viterbiDecode(instance, guessLabel);
for (int i = 0; i < instance.length(); i++)
{
int[] featureVector = instance.getFeatureAt(i);
int[] goldFeature = new int[featureVector.length];
int[] predFeature = new int[featureVector.length];
for (int j = 0; j < featureVector.length - 1; j++)
{
goldFeature[j] = featureVector[j] * tagSet.size() + instance.tagArray[i];
predFeature[j] = featureVector[j] * tagSet.size() + guessLabel[i];
}
goldFeature[featureVector.length - 1] = (i == 0 ? tagSet.bosId() : instance.tagArray[i - 1]) * tagSet.size() + instance.tagArray[i];
predFeature[featureVector.length - 1] = (i == 0 ? tagSet.bosId() : guessLabel[i - 1]) * tagSet.size() + guessLabel[i];
model.update(goldFeature, predFeature, total, timestamp, current);
}
}
// 在开发集上校验
accuracy = trainingFile.equals(developFile) ? IOUtility.evaluate(instances, model) : evaluate(developFile, model);
out.printf("Iter#%d - ", iter);
printAccuracy(accuracy);
}
// 平均
model.average(total, timestamp, current);
accuracy = trainingFile.equals(developFile) ? IOUtility.evaluate(instances, model) : evaluate(developFile, model);
out.print("AP - ");
printAccuracy(accuracy);
logger.start("以压缩比 %.2f 保存模型到 %s ... ", compressRatio, modelFile);
model.save(modelFile, immutableFeatureMap.featureIdMap.entrySet(), compressRatio);
logger.finish(" 保存完毕\n");
if (compressRatio == 0) return new Result(model, accuracy);
}
else
{
// 多线程用Structure Perceptron
StructuredPerceptron[] models = new StructuredPerceptron[threadNum];
for (int i = 0; i < models.length; i++)
{
models[i] = new StructuredPerceptron(immutableFeatureMap);
}
TrainingWorker[] workers = new TrainingWorker[threadNum];
int job = instances.length / threadNum;
for (int iter = 1; iter <= maxIteration; iter++)
{
Utility.shuffleArray(instances);
try
{
for (int i = 0; i < workers.length; i++)
{
workers[i] = new TrainingWorker(instances, i * job,
i == workers.length - 1 ? instances.length : (i + 1) * job,
models[i]);
workers[i].start();
}
for (TrainingWorker worker : workers)
{
worker.join();
}
for (int j = 0; j < models[0].parameter.length; j++)
{
for (int i = 1; i < models.length; i++)
{
models[0].parameter[j] += models[i].parameter[j];
}
models[0].parameter[j] /= threadNum;
}
accuracy = trainingFile.equals(developFile) ? IOUtility.evaluate(instances, models[0]) : evaluate(developFile, models[0]);
out.printf("Iter#%d - ", iter);
printAccuracy(accuracy);
}
catch (InterruptedException e)
{
err.printf("线程同步异常,训练失败\n");
e.printStackTrace();
return null;
}
}
logger.start("以压缩比 %.2f 保存模型到 %s ... ", compressRatio, modelFile);
models[0].save(modelFile, immutableFeatureMap.featureIdMap.entrySet(), compressRatio, HanLP.Config.DEBUG);
logger.finish(" 保存完毕\n");
if (compressRatio == 0) return new Result(models[0], accuracy);
}
LinearModel model = new LinearModel(modelFile);
if (compressRatio > 0)
{
accuracy = evaluate(developFile, model);
out.printf("\n%.2f compressed model - ", compressRatio);
printAccuracy(accuracy);
}
return new Result(model, accuracy);
}
基于条件随机场的词性标注
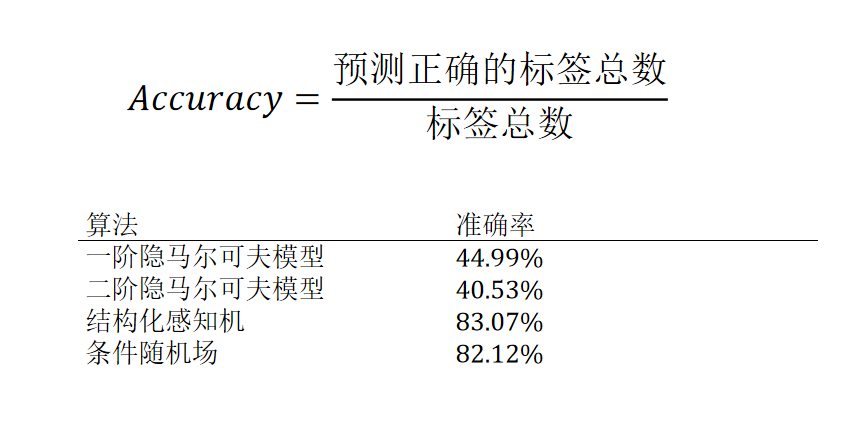
词性标注评测
PosTagUtil.evaluate
/**
* 评估词性标注器的准确率
*
* @param tagger 词性标注器
* @param corpus 测试集 data/test/pku98/199801-test.txt
* @return Accuracy百分比
*/
public static float evaluate(POSTagger tagger, String corpus)
{
int correct = 0, total = 0;
IOUtil.LineIterator lineIterator = new IOUtil.LineIterator(corpus);
//循环测试集中的每一行数据
for (String line : lineIterator)
{
Sentence sentence = Sentence.create(line);
if (sentence == null) continue;
//将字符,词性,转成二维数组
String[][] wordTagArray = sentence.toWordTagArray();
//根据测试字符获得预测的词性
String[] prediction = tagger.tag(wordTagArray[0]);
//看预测词性的长度和测试词性长度是否相等
assert prediction.length == wordTagArray[1].length;
// 199801-test.txt 中的所有字符个数
total += prediction.length;
for (int i = 0; i < prediction.length; i++)
{
//预测词性 = 测试词性,预测正确的标签总数 + 1
if (prediction[i].equals(wordTagArray[1][i])){
++correct;
}
}
}
if (total == 0) return 0;
//准确率 = 预测正确标签总数 / 标签总数
return correct / (float) total * 100;
}
自定义词性
在工程上,许多用户希望将特定的一些词语打上自定义的标签,称为自定义词性
朴素实现
规则系统,用户将自己关心的词语以及自定义词性以词典的形式交给HanLP挂载
CustomDictionary.insert("苹果", "手机品牌 1")
CustomDictionary.insert("iPhone X", "手机型号 1")
analyzer = PerceptronLexicalAnalyzer()
analyzer.enableCustomDictionaryForcing(True)
print(analyzer.analyze("你们苹果iPhone X保修吗?"))
print(analyzer.analyze("多吃苹果有益健康"))
你们/r 苹果/手机品牌 iPhone X/手机型号 保修/v 吗/y ?/w
多/ad 吃/v 苹果/手机品牌 有益健康/i
标注语料
PerceptronPOSTagger posTagger = trainPerceptronPOS(ZHUXIAN); // 训练
AbstractLexicalAnalyzer analyzer = new AbstractLexicalAnalyzer(new PerceptronSegmenter(), posTagger); // 包装
System.out.println(analyzer.analyze("陆雪琪的天琊神剑不做丝毫退避,直冲而上,瞬间,这两道奇光异宝撞到了一起。")); // 分词+标注
陆雪琪/NR 的/DEG 天琊神剑/NN 不/AD 做/VV 丝毫/NN 退避/VV ,/PU 直冲/VV 而/MSP 上/VV ,/PU 瞬间/NN ,/PU 这/DT 两/CD 道/M 奇光/NN 异宝/NN 撞/VV 到/VV 了/AS 一起/AD 。/PU
总结
隐马尔可夫模型、感知机和条件随机场三种词性标注器
为了实现自定义词性
依靠词典匹配虽然简单但非常死板,只能用于一词一义的情况
如果涉及兼类词,标注一份领域语料才是正确做法
本文来自博客园,作者:VipSoft 转载请注明原文链接:https://www.cnblogs.com/vipsoft/p/17998604

 浙公网安备 33010602011771号
浙公网安备 33010602011771号