HanLP — 双数组字典树 (Double-array Trie) 实现原理 -- 代码 + 图文,看不懂你来打我
学习HanLP时,碰到了 双数组字典树(Double-Array Trie)的概念,网上找了好多贴子,花了好久才整明白,结合看过的帖子重新做个梳理。
双数组字典树(Double-Array Trie,简称DAT或者Darts)就是这样一种状态转移复杂度为常数的数据结构。双数组字典树由日本人Jun-IchiAoe于1989 年提出它由base[]和check[]两个数组构成,又简称双数组。是一种高效的字典树数据结构,它将字符串映射为整数值,常用于字符串匹配、字符串检索和词频统计等领域。它的原理基于两个关键思想:压缩存储和公共前缀共享。
优点:Trie 字典树 是一种 以空间换时间 的数据结构,Trie对内存的消耗比较大,DAT正是为了优化该问题而提出,刻服了Tire树浪费空间的不足。
缺点:在插入和删除的时,往往需要对双数组结构进行全局调整,灵活性能较差。如果核心词典已经预先建立好并且有序的,并且不会添加或删除新词,那么这个缺点是可以忽略的。
Trie 字典树
由 ["清华", "清华大学", "清新", "中华", "华人"] 五个中文词构成的 Trie 树形
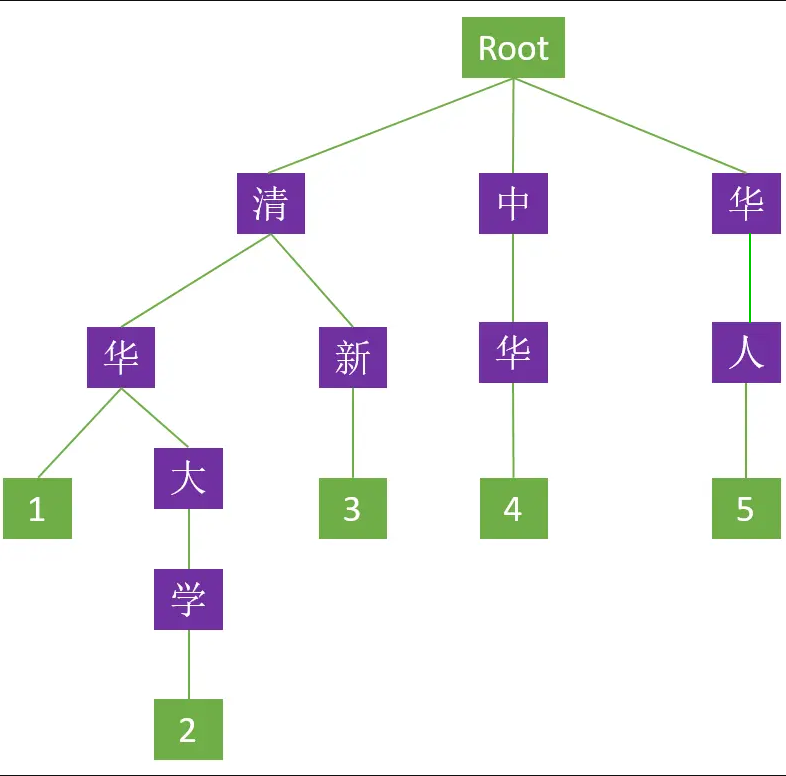
双数组Trie树 构建
双数组 Trie,是将所有节点的状态都记录到一个数组之中(Base Array),以此减少数组的大量空置。
建议实际应用中应首先对字典排个序,减少插入带来树的重构,再构建所有词的首字,然后逐一构建各个节点的子节点,这样一旦产生冲突,可以将冲突的处理局限在单个父节点和子节点之间,而不至于导致大范围的节点重构。
下文中,清【新】的变化导致 清【华】的变化,只是兄弟节点的小范围调整
字符编码
为了方便理解,将字典中5个词的字进行编码,实际使用中,可直接使用 (int)char 强转为ASCII码,或者 Unicode 码等
| char | 清 | 华 | 大 | 学 | 新 | 中 | 人 |
|---|---|---|---|---|---|---|---|
| code | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
计算规则
在Double Array Trie中,base 和 check 通常表示Trie树的两种状态。
- base数组:数组的每个元素表示一个Trie节点,即一个状态(分为空闲状态和占用状态),负责记录状态,用于状态转移。
- check数组:数组的每个元素表示某个状态的前驱状态,负责检查各个字符串是否是从同一个状态转移而来。
当状态 s 接受字符 c转移到状态 t时,双数组满足:
# s 表示当前状态的下标
# c 代表输入字符的值 => code("清")
# t 表示转移状态的下标
base[s] + c = t # 表示一次状态转移
check[t] = s # 等于 前驱状态(位置索引),检验状态转移是否成功,
# HanLP 书上写的是 check[p] = base[b],不知道是不是勘误,感觉 当前转移基数 = 前驱转移基数 不太保险
Base Array 计算
- 当前状态 = base[s]
- 转移下标 = 当前状态 + 字符值 = base[s] + code("字符")
也就是下一个 “字符” 要写入的位置
- 转移基数 = 前驱节点转移基数。
有冲突时,处理步骤如下:
- 重新计算前驱转移基数 = 所放位置值 - 字符Code值。
- 再遍历前驱下面的子节点,看看新的转移基数,对其它子节点有没有引起冲突,如果有,回到第1步再进行计算
- 前驱节点下所有的子节点,都找到可放的位置后,更新所有节点的转移基数
Check Array 计算
- 检验值 = 前驱节点的 位置
清华,清的位置 2,check[5] = 2,check[5] == 2, 说明 "清华" 这个词在构建的树字典中
人大,人的位置 3,check[6] = 5, check[6] != 3, 说明 "人大" 这个词不在构建的树字典中
处理叶子节点
如果是叶子节点。将值转为负数,这样相比在后面加上 \0 要省节点空间
构建 Base Array、Check Array
对下列5组词进行构建: [“清华”、“清华大学”、“清新”、“中华”、“华人”]
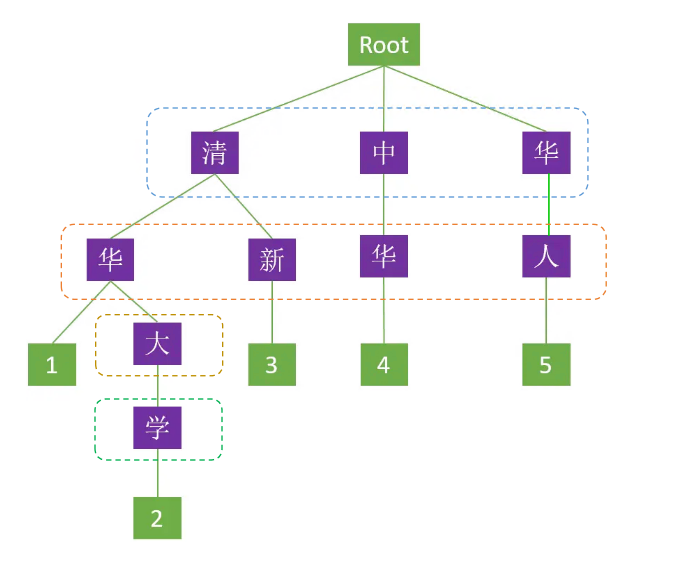
分四轮构建,先处理第一层【清、中、华】,再处理第二层【华、新、华、人】,然后处理【大】,【学】
初始化root的 base 转移基数为 1, check 的值为 -1。
base数组初始化大小,一般为 65535 + N ,放大些,足够容纳下字符就可以了。
本文图中紫色有9个字符,由于 root(base[0]) 的转移基数初始赋值 = 1,第一个字的字符编码 = 1,1+1 = 2,所以第1个字符放的位置是从 base[2] 开始,base[1] 会空在那,因此 Base Array 大小初始化为 base[0] + base[1] + 9个字符 11,如下图:

处理字典首字
先处理字典的首字【清、中、华】,逐字处理
先不考虑叶子节点的情况下,这样方便理解(后面会说处理逻辑),实际编码时 base、check、叶子节点,会一并处理
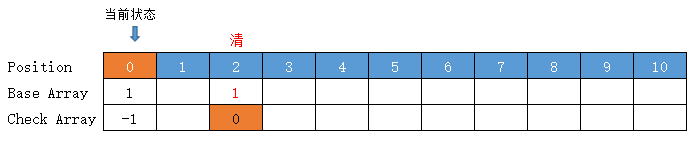
【清】
当前状态 = root 根状态 = base[0] = 1
转移下标 = 当前状态 + 字符值 = base[0] + code("清") = 1 + 1 = 2 位置 2 空闲,(放入位置 2)
前驱转移基数 = base[0] = 1 (位置 2 空闲,不需重新计算)
转移后的前驱,也就是【清】的前驱,其实也就是上面提到的当前状态
转移基数 = 前驱转移基数 = base[0] = 1
Check = 前驱的位置 = 0
【中】
当前状态 = root 根状态 = base[0] = 1
转移下标 = base[0] + code("中") = 1 + 6 = 7 位置 2 空闲,(放入位置 7)
前驱转移基数 = base[0] = 1 (位置 7 空闲,不需重新计算)
转移基数 = 前驱转移基数 = 1
Check = 前驱的位置 = 0
【华】
当前状态 = root 根状态 = base[0] = 1
转移下标 = base[0] + code("华") = 1 + 2 = 3 位置 2 空闲,(放入位置 3)
前驱转移基数 = base[0] = 1 (位置 3 空闲,前驱不需重新计算)
转移基数 = 前驱转移基数 = 1
Check = 前驱的位置 = 0
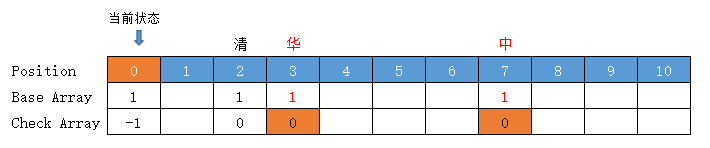
处理字典二层字
处理字典 ["清华", "清华大学", "清新", "中华", "华人"] 的第二层字【华、新、华、人】
【清华】
计算过程,要看上一张图,下面对应的图是计算后的结果图
当前状态 = "清"字状态 =base[0] + code("清") = 2
当前在“清”字上,要计算下一个“华”
转移下标 = base[2] + code("华") = 1 + 2 = 3 ,位置3有值,向后挪至空位4 (放入位置 4)
前驱转移基数 = base[2] = 所放位置值 - 字符Code值 = 4 - code("华") = 4 - 2 = 2
有冲突,前驱转移基数需要重新计算,并更新前驱转移基数的值
转移基数 = 前驱转移基数 = 2
Check = 前驱的位置 = 2
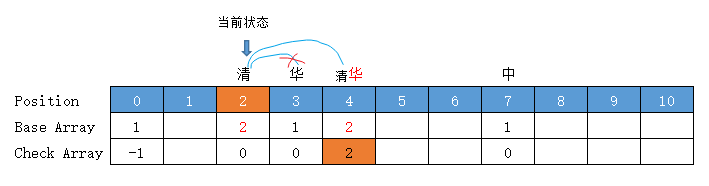
【清华大学】
和前面的【清华】一致,节点位置、转移基数无变化
【清新】
当前状态 = “清”字状态 = base[0] + code("清") = 2
转移下标 = base[2] + code("新") = 2 + 5 = 7,位置7有值,向后挪至空位8 (放入位置 8 )
前驱转移基数 = base[2] = 所放位置值 - 字符Code值 = 8 - code("新") = 8 - 5 = 3
此时 "清" 变为3了,再看下它的子节点,清【华】,base[2] + code("华") = 3 + 2 =5
此时需要将 base[4] 上原来的华,向后挪至 base[5],否则 【清华】就断连了
如果 base[5] 上有值,还需要继续往后挪,然后重新计算前驱 base[2] 转移基数
转移基数 = 前驱转移基数 = 3
【清华】 = base[5] = 3
【清新】 = base[8] = 3
Check = 前驱的位置 = 2
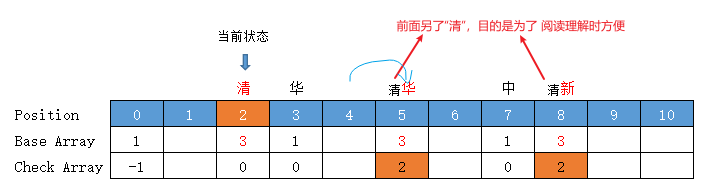
【中华】
当前状态 = “中”字状态 = base[0] + code("中") =1 + 6 = 7
转移下标 = base[7] + code("华") = 1 + 2 = 3,位置3有值,向后挪至空位4 (放入位置 4 )
前驱转移基数 = base[7] = 所放位置值 - 字符Code值 = 4 - code("华") = 4 - 2 = 2
转移基数 = 前驱转移基数 = base[7] = 2
Check = 前驱的位置 = 7
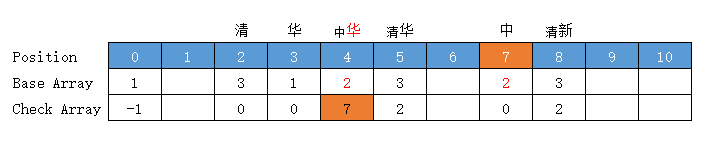
【华人】
当前状态 = "华"字状态 = "华"字位置下标 = base[0] + code("华") = 1 + 2 = 3
转移下标 = base[3] + code("人") = 1 + 7 = 8,位置 8 有值,向后挪至空位 9 (放入位置 9 )
前驱转移基数 = base[3] = 所放位置值 - 字符Code值 = 9 - 7 = 2
转移基数 = 前驱转移基数 = base[3] = 2
Check = 前驱的位置 = 7
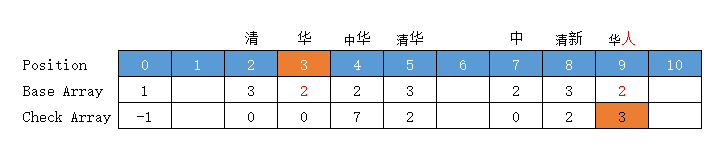
处理字典三层字
处理字典 ["清华", "清华大学", "清新", "中华", "华人"] 的第三层字【大】
【清华大学】
当前状态 = "华"字状态 = "华"字位置下标 = base[base[0] + code("清")] + code("华") = 3 + 2 = 5
当前状态下标要从头开始算,不能直接看 “华” 否则会被上面的 华人的华干扰,这也是图片上在文字前面加上小字前缀 的原因
转移下标 = base[5] + code("大") = 3 + 3 = 6,位置 6 空闲 (放入位置 6 )
前驱转移基数 = base[5] = 3 (位置 6 空闲,不需要重算)
转移基数 = 前驱转移基数 = base[5] = 3
Check = 前驱的位置 = 5

处理字典四层字
处理字典 ["清华", "清华大学", "清新", "中华", "华人"] 的第三层字【学】
【清华大学】
当前状态 = "大"字状态 = "大"字位置下标 = 6
转移下标 = base[6] + code("学") = 3 + 4 = 7,位置 7 有值,向后挪至空位 10 (放入位置 10 )
前驱转移基数 = base[6] = 所放位置值 - 字符Code值 = 10 - 6 = 6
转移基数 = 前驱转移基数 = base[6] = 6
Check = 前驱的位置 = 6
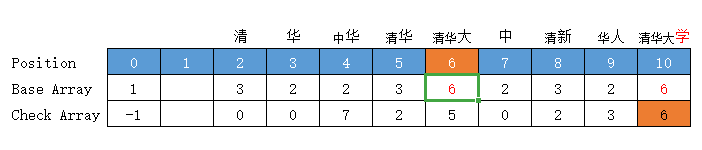
叶子节点处理
将每个词的词尾设置为转移基数的负数(只有词尾为负值),这样能够节省构建时间,不过进行转移时要将状态转移函数改为|base[b]|+code(字符)
//叶子节点转移基数标识为父节点转移基数的相反数,比起 \0 少加了节点,计算时加上绝对值
base[s]= (base[s] * -1);
处理后的效果图如下

核心代码
public void build(List<String> list) {
init();
String[] dir = list.toArray(new String[0]);
// 词的深度 -- 先处理首字
int depth = 1;
//循环处理字典列表,每层处理一次,直到所有的字典都处理完
while (!list.isEmpty()) {
// 根据相同前缀分组,存放每一次的字,key = 深度
Map<Integer, List<Node>> map = new HashMap<>();
for (int i = 0; i < list.size();) {
String word = list.get(i);
String pre = word.substring(0, depth - 1); //取前驱字
String k = word.substring(depth - 1, depth); //取当前要处理的字
Node n = new Node();
n.code = getCode(k);
n.s = depth == 1 ? 0 : indexOf(pre);
n.label = k;
if (depth == word.length()) {
list.remove(i); // 如果深度 = 字典长度,表示没有下一层,这时候从列表中移除
} else {
i++;
}
List<Node> siblings = map.getOrDefault(n.s, new ArrayList<>());
if(siblings.contains(n)){
continue;
}
siblings.add(n);
map.put(n.s, siblings);
}
//字典 第N层的字 组装好后,开始处理
map.forEach((s, siblings) -> {
int offset = 0;
for (int i = 0; i < siblings.size(); i++) {
Node node = siblings.get(i);
int c = node.code;
int t = base[s] + offset + c;
System.out.printf(" "+ node.label);
// 发现在节点已有值则偏移+1
if (check[t] != -1) {
offset++; //往后挪一位,重新计算时看看下一位有没有值,如果有值继续算
i = -1; //字符没地方放,倒回去,整个这一层的节点都需要,重新计算,新变了,导致清转移基数变了,这时候要重新计算清华的华,看华往后挪一个是不是可以,如果不可以继续调整
System.out.printf(" " + t + " 有值换 ");
}
else {
System.out.println(" "+ t);
}
}
base[s] = base[s] + offset; // offset 往后挪了1位,满足了 清【新】、清【华】,重新构建建树
//转移基数计算完成后,构建 base、check数组
for (Node node : siblings) {
int c = node.code;
int t = base[s] + c;
// 给上父结点
check[t] = s;
// 当前状态的转移基数 = 上一个节点的转移基数
base[t] = base[s];
}
});
depth++;
}
// 发现字节点,置为负数
for (String aDir : dir) {
int s = indexOf(aDir);
base[s] = -1 * base[s];
}
}
完整代码
参考:
小白详解 Trie 树 -- 图中数值有些错误
双数组字典树(DATrie)详解及实现 -- 它是按每个词去处理的,代码有些问题,有冲突没有重构树
本文来自博客园,作者:VipSoft 转载请注明原文链接:https://www.cnblogs.com/vipsoft/p/17774393.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号