大数据 - DWS层 业务实现
| 统计主题 | 需求指标【ADS】 | 输出方式 | 计算来源 | 来源层级 |
|---|---|---|---|---|
| 访客【DWS】 | pv | 可视化大屏 | page_log 直接可求 | dwd |
| UV(DAU) | 可视化大屏 | 需要用 page_log 过滤去重 | dwm | |
| UJ 跳出率 | 可视化大屏 | 需要通过 page_log 行为判断 | dwm | |
| 进入页面数 | 可视化大屏 | 需要识别开始访问标识 | dwd | |
| 连续访问时长 | 可视化大屏 | page_log 直接可求 | dwd | |
| 商品 | 点击 | 多维分析 | page_log 直接可求 | dwd |
| 收藏 | 多维分析 | 收藏表 | dwd | |
| 加入购物车 | 多维分析 | 购物车表 | dwd | |
| 下单 | 可视化大屏 | 订单宽表 | dwm | |
| 支付 | 多维分析 | 支付宽表 | dwm | |
| 退款 | 多维分析 | 退款表 | dwd | |
| 评论 | 多维分析 | 评论表 | dwd | |
| 地区 | PV | 多维分析 | page_log 直接可求 | dwd |
| UV | 多维分析 | 需要用 page_log 过滤去重 | dwm | |
| 下单 | 可视化大屏 | 订单宽表 | dwm | |
| 关键词 | 搜索关键词 | 可视化大屏 | 页面访问日志 直接可求 | dwd |
| 点击商品关键词 | 可视化大屏 | 商品主题下单再次聚合 | dws | |
| 下单商品关键词 | 可视化大屏 | 商品主题下单再次聚合 | dws |
DWS 层的定位是什么
- 轻度聚合,因为 DWS 层要应对很多实时查询,如果是完全的明细那么查询的压力是非常大的。
- 将更多的实时数据以主题的方式组合起来便于管理,同时也能减少维度查询的次数。
DWS 层-访客主题宽表的计算
| 统计主题 | 需求指标【ADS】 | 输出方式 | 计算来源 | 来源层级 |
|---|---|---|---|---|
| 访客【DWS】 | PV | 可视化大屏 | page_log 直接可求 | dwd |
| UV(DAU) | 可视化大屏 | 需要用 page_log 过滤去重 | dwm | |
| 跳出率 | 可视化大屏 | 需要通过 page_log 行为判断 | dwm | |
| 进入页面数 | 可视化大屏 | 需要识别开始访问标识 | dwd | |
| 连续访问时长 | 可视化大屏 | page_log 直接可求 | dwd |
设计一张 DWS 层的表其实就两件事:维度和度量(事实数据)
- 度量包括 PV、UV、跳出次数、进入页面数(session_count)、连续访问时长
- 维度包括在分析中比较重要的几个字段:渠道、地区、版本、新老用户进行聚合
需求分析与思路
- 接收各个明细数据,变为数据流
- 把数据流合并在一起,成为一个相同格式对象的数据流
- 对合并的流进行聚合,聚合的时间窗口决定了数据的时效性
- 把聚合结果写在数据库中
功能实现
封装 VisitorStatsApp,读取 Kafka 各个流数据
访客主题宽表计算
- 要不要把多个明细的同样的维度统计在一起?
- 因为单位时间内 mid 的操作数据非常有限不能明显的压缩数据量(如果是数据量够大,或者单位时间够长可以)
- 所以用常用统计的四个维度进行聚合 渠道、新老用户、app 版本、省市区域
- 度量值包括 启动、日活(当日首次启动)、访问页面数、新增用户数、跳出数、平均页面停留时长、总访问时长
- 聚合窗口: 10 秒
- 各个数据在维度聚合前不具备关联性,所以先进行维度聚合
- 进行关联 这是一个 fulljoin
- 可以考虑使用 FlinkSQL 完成
合并数据流
把数据流合并在一起,成为一个相同格式对象的数据流
合并数据流的核心算子是 union。但是 union 算子,要求所有的数据流结构必须一致。所以 union 前要调整数据结构。
根据维度进行聚合
- 设置时间标记及水位线,因为涉及开窗聚合,所以要设定事件时间及水位线
- 分组 分组选取四个维度作为 key , 使用 Tuple4 组合
- 开窗
- 窗口内聚合及补充时间字段
- 写入 OLAP 数据库
为何要写入 ClickHouse 数据库,ClickHouse 数据库作为专门解决大量数据统计分析的数据库,在保证了海量数据存储的能力,同时又兼顾了响应速度。而且还支持标准 SQL,即灵活又易上手。
flink-connector-jdbc 是官方通用的 jdbcSink 包。只要引入对应的 jdbc 驱动,flink 可以用它应对各种支持 jdbc 的数据库,比如 phoenix 也可以用它。但是这个 jdbc-sink 只支持数据流对应一张数据表。如果是一流对多表,就必须通过自定义的方式实现了,比如之前的维度数据。
虽然这种 jdbc-sink 只能一流对一表,但是由于内部使用了预编译器,所以可以实现批量提交以优化写入速度。
DWS 层-商品主题宽表的计算
| 商品 | 点击 | 多维分析 | page_log 直接可求 | dwd |
| 收藏 | 多维分析 | 收藏表 | dwd | |
| 加入购物车 | 多维分析 | 购物车表 | dwd | |
| 下单 | 可视化大屏 | 订单宽表 | dwm | |
| 支付 | 多维分析 | 支付宽表 | dwm | |
| 退款 | 多维分析 | 退款表 | dwd | |
| 评论 | 多维分析 | 评论表 | dwd |
需求分析与思路
- 从 Kafka 主题中获得数据流
- 把 Json 字符串数据流转换为统一数据对象的数据流
- 把统一的数据结构流合并为一个流
- 设定事件时间与水位线
- 分组、开窗、聚合
- 关联维度补充数据
- 写入 ClickHouse
功能实现
- 封装商品统计实体类 ProductStats
- 创建 ProductStatsApp,从 Kafka 主题中获得数据流
- 把 JSON 字符串数据流转换为统一数据对象的数据流
- 创建电商业务常量类 GmallConstant
- 把统一的数据结构流合并为一个流
- 设定事件时间与水位线
- 分组、开窗、聚合
- 补充商品维度信息
因为除了下单操作之外,其它操作,只获取到了商品的 id,其它维度信息是没有的 - 写入 ClickHouse product_stats
DWS 层-地区主题表(FlinkSQL)
| 地区 | PV | 多维分析 | page_log 直接可求 | dwd |
| UV | 多维分析 | 需要用 page_log 过滤去重 | dwm | |
| 下单 | 可视化大屏 | 订单宽表 | dwm |
需求分析与思路
- 定义 Table 流环境
- 把数据源定义为动态表
- 通过 SQL 查询出结果表
- 把结果表转换为数据流
- 把数据流写入目标数据库
如果是 Flink 官方支持的数据库,也可以直接把目标数据表定义为动态表,用 insert into 写入。由于ClickHouse目前官方没有支持的jdbc连接器(目前支持Mysql、PostgreSQL、Derby)。也可以制作自定义 sink,实现官方不支持的连接器。但是比较繁琐。
功能实现
DWS 层-关键词主题宽表的计算
| 关键词 | 搜索关键词 | 可视化大屏 | 页面访问日志 直接可求 | dwd |
| 点击商品关键词 | 可视化大屏 | 商品主题下单再次聚合 | dws | |
| 下单商品关键词 | 可视化大屏 | 商品主题下单再次聚合 | dws |
需求分析与思路
关键词主题这个主要是为了大屏展示中的字符云的展示效果,用于感性的让大屏观看者感知目前的用户都更关心的那些商品和关键词。
关键词的展示也是一种维度聚合的结果,根据聚合的大小来决定关键词的大小。
关键词的第一重要来源的就是用户在搜索栏的搜索,另外就是从以商品为主题的统计中获取关键词。
功能实现
关于分词
以我们需要根据把长文本分割成一个一个的词,这种分词技术,在搜索引擎中可能会用到。对于中文分词,现在的搜索引擎基本上都是使用的第三方分词器,咱们在计算数据中也可以,使用和搜索引擎中一致的分词器,IK。
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
有了分词器,那么另外一个要考虑的问题就是如何把分词器的使用揉进 FlinkSQL 中。
因为 SQL 的语法和相关的函数都是 Flink 内定的,想要使用外部工具,就必须结合自定义函数。
https://www.bilibili.com/video/BV1Ju411o7f8/?p=115
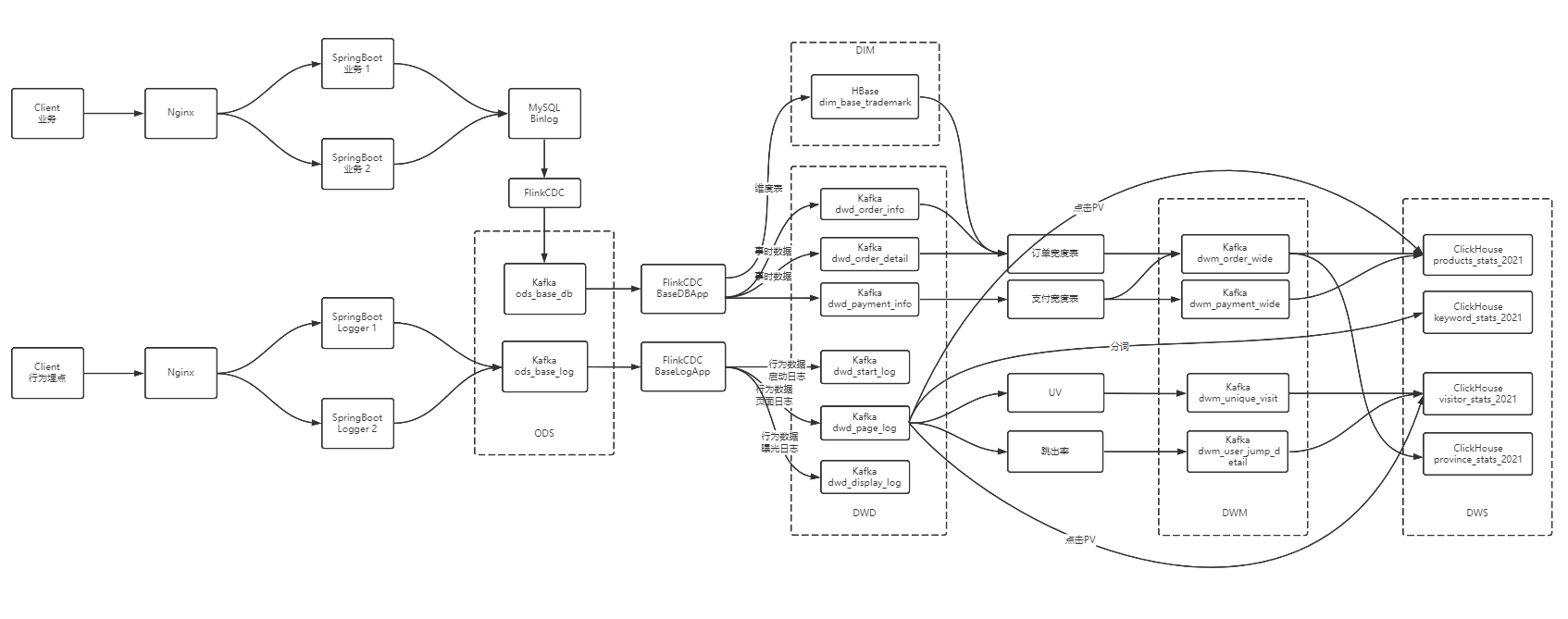
大数据 - 数据仓库-实时数仓架构分析
大数据 - 业务数据采集-FlinkCDC
大数据 - DWD&DIM 行为数据
大数据 - DWD&DIM 业务数据
大数据 - DWM层 业务实现
大数据 - DWS层 业务实现
大数据 - ADS 数据可视化实现
本文来自博客园,作者:VipSoft 转载请注明原文链接:https://www.cnblogs.com/vipsoft/p/17010578.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号