数据实时增量同步之CDC工具—Canal、mysql_stream、go-mysql-transfer、Maxwell
@
[Mysql数据实时增量同步之CDC工具—Canal、mysql_stream、go-mysql-transfer、Maxwell:https://blog.csdn.net/weixin_42526326/article/details/121148721
什么是CDC?
CDC(Change Data Capture)是变更数据获取的简称。可以基于增量日志,以极低的侵入性来完成增量数据捕获的工作。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
简单来讲:CDC是指从源数据库捕获到数据和数据结构(也称为模式)的增量变更,近乎实时地将这些变更,传播到其他数据库或应用程序之处。
通过这种方式,CDC能够向数据仓库提供高效、低延迟的数据传输,以便信息被及时转换并交付给专供分析的应用程序。
与批量复制相比,变更数据的捕获通常具有如下三项基本优势:
- CDC通过仅发送增量的变更,来降低通过网络传输数据的成本。
- CDC可以帮助用户根据最新的数据做出更快、更准确的决策。例如,CDC会将事务直接传输到专供分析的应用上。
- CDC最大限度地减少了对于生产环境网络流量的干扰。
CDC工具对比
| 特色 | Canal | mysql_stream | go-mysql-transfer | Maxwell |
|---|---|---|---|---|
| 开发语言 | Java | Python | Golang | Java |
| 高可用 | 支持 | 支持 | 支持 | 支持 |
| 接收端 | 编码定制 | Kafka等(MQ) | Redis、MongoDB、Elasticsearch、RabbitMQ、Kafka、RocketMQ、HTTP API 等 | Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件等 |
| 全量数据初始化 | 不支持 | 支持 | 支持 | 支持 |
| 数据格式 | 编码定制 | Json(固定格式) | Json(规则配置) 模板语法 Lua脚本 | JSON |
| 性能(4-8TPS) |
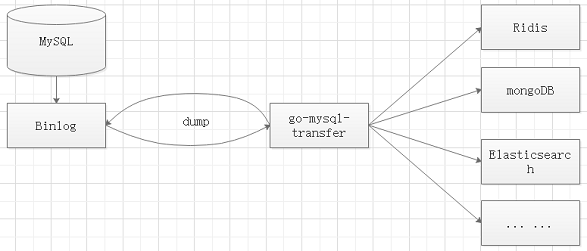
实现原理:
1、go-mysql-transfer将自己伪装成MySQL的Slave,
2、向Master发送dump协议获取binlog,解析binlog并生成消息
3、将生成的消息实时、批量发送给接收端
Mysql binlog 讲解:
MySQL的二进制日志可以说MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,
以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。
一般来说开启二进制日志大概会有1%的性能损耗。
二进制日志两个最重要的使用场景:
- MySQL Replication在Master端开启binlog,Master把它的二进制日志传递给slaves来达到master-slave数据一致的目的。
- 数据恢复,通过使用mysqlbinlog工具来使恢复数据。
二进制日志包括两类文件:
-
二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件
-
二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
binlog文件的滚动:
- 达到了滚动的大小
- mysql服务停止
mysql binlog的三种格式
在配置文件中可以选择配置 binlog_format= statement|mixed|row
-
ROW 模式(一般就用它)
日志会记录每一行数据被修改的形式,不会记录执行 SQL 语句的上下文相关信息,只记录要修改的数据,哪条数据被修改了,修改成了什么样子,只有 value,不会有 SQL 多表关联的情况。
优点:它仅仅只需要记录哪条数据被修改了,修改成什么样子了,所以它的日志内容会非常清楚地记录下每一行数据修改的细节,非常容易理解。
缺点:ROW 模式下,特别是数据添加的情况下,所有执行的语句都会记录到日志中,都将以每行记录的修改来记录,这样会产生大量的日志内容。
-
STATEMENT 模式
每条会修改数据的 SQL 语句都会被记录下来。
缺点:由于它是记录的执行语句,所以,为了让这些语句在 slave 端也能正确执行,那他还必须记录每条语句在执行过程中的一些相关信息,也就是上下文信息,以保证所有语句在 slave 端被执行的时候能够得到和在 master 端执行时候相同的结果。
但目前例如 step()函数在有些版本中就不能被正确复制,在存储过程中使用了 last-insert-id()函数,可能会使 slave 和 master 上得到不一致的 id,就是会出现数据不一致的情况,ROW 模式下就没有。
-
MIXED 模式
以上两种模式都使用。
常见的数据采集工具(相关知识):
DataX、Flume、Canal、Sqoop、LogStash
DataX (处理离线数据)
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,异构数据源离线同步指的是将源端数据同步到目的端,但是端与端的数据源类型种类繁多,在没有 DataX 之前,端与端的链路将组成一个复杂的网状结构,非常零散无法把同步核心逻辑抽象出来。
为了解决异构数据源同步问题,DataX 将复杂的网状的同步链路变成了星型数据链路,DataX 作为中间传输载体负责连接各种数据源。
所以,当需要接入一个新的数据源的时候,只需要将此数据源对接到 DataX,就可以跟已有的数据源做到无缝数据同步。
DataX本身作为离线数据同步框架,采用Framework+plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader: 它为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: 它为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:它用于连接Reader和Writer,作为两者的数据传输通道,并处理缓冲、并发、数据转换等问题。
核心模块介绍:
- DataX完成单个数据同步的作业,我们把它称之为Job,DataX接收到一个Job之后,将启动一个进程来完成整个作业同步过程。
- DataX Job启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader->Channel->Writer的线程来完成任务同步工作。
- DataX作业运行完成之后,Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出。
Flume(处理实时数据)
Flume主要应用的场景是同步日志数据,主要包含三个组件:Source、Channel、Sink。
Flume最大的优点就是官网提供了丰富的Source、Channel、Sink,根据不同的业务需求,我们可以在官网查找相关配置。另外,Flume还提供了自定义这些组件的接口。
Logstash(处理离线数据)
Logstash就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上过滤网,Logstash提供了很多功能强大的过滤网来满足各种应用场景。
Logstash是由JRuby编写,使用基于消息的简单架构,在JVM上运行。在管道内的数据流称之为event,它分为inputs阶段、filters阶段、outputs阶段。
Sqoop(处理离线数据)
Sqoop是Hadoop和关系型数据库之间传送数据的一种工具,它是用来从关系型数据库如MySQL到Hadoop的HDFS从Hadoop文件系统导出数据到关系型数据库。Sqoop底层用的还是MapReducer,用的时候一定要注意数据倾斜。
注:sqoop不是CDC工具 sqoop是基于查询的全量数据捕获.
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号