计算机网络协议,UDP数据报的分析
一、UDP数据报的特点
1.基本特性
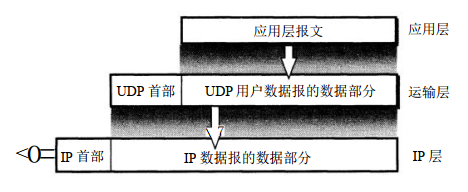
UDP是在IP数据报的基础上增加了复用和分用以及差错检测的功能
UDP的主要特点如下:
- UDP是无连接的;即发送数据之前不需要建立连接
- UDP使用尽最大努力交付,不保证可靠交付
- UDP面向报文;不会拆分、合并报文。
即在UDP对应用层返回的报文加首部,对IP层提交的报文去首部的过程中,处理的是这个报文的整体,即一次处理一个完整的报文
- UDP没有拥塞控制;
即网络的堵塞并不会导致发送UDP数据的一端采取任何措施(比如减慢速度以减轻网络拥塞),这种特性被一些实时性的应用钟爱,例如现场直播
- UDP支持一对一、一对多、多对一、多对多的交互通信
- UDP首部 8byte ;即首部开销较小
2.注意事项
- 当运输层从IP层解包得到UDP数据报后,就通过UDP首部中提供的目的端口,提供给当前系统的某个进程(我们知道进程或服务很多情况下是通过端口进行区分与进行作业的)
- 虽然在UDP之间的通信要用到其端口号,但由于UDP的通信是无连接的,因此不需要使用套接字(TCP的通信要在套接字已连接的前提下进行)。
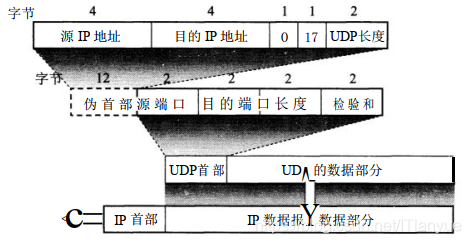
- UDP进行检验时。需要在数据报之前增加12个字节的“伪首部”。这些数据并不是数据报中真正的首部,只是在计算检验和时需要用到的临时数据。伪首部既不向下提供封装功能,也不向上提供解包功能,一旦检验完成,数据就失效。
二、UDP数据报结构
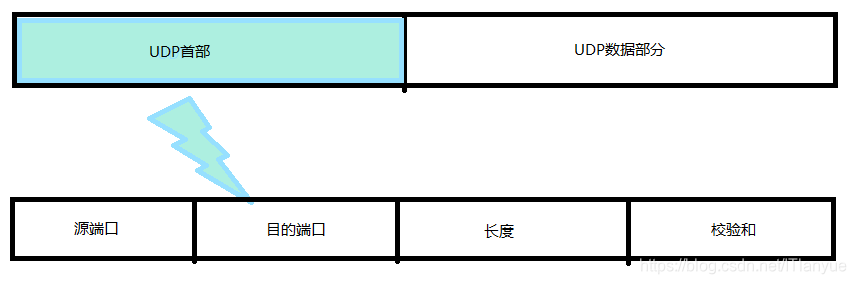
UDP的首部长8字节,其中分为源端口、目的端口、长度、校验和四部分,每部分2字节
- 源端口 ===> 数据报发送方的端口号;在需要对方回信时选用,不需要时可以设全0
- 目的端口 ===> 数据报接收方的端口号;
- 长度 ===> UDP数据报的长度;最小为8字节(即只有UDP首部)
- 校验和 ===> 检测UDP数据在传输中是否有错,出现错误就丢弃
三、UDP数据报分析之实战训练
我们利用Python写一个udp聊天程序,然后再利用wireshark抓取到其中的udp数据报。这样我们就可以更直观的分析udp数据报的特点了
1.实现代码
服务器端代码:
import socket
udp_server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
udp_server.bind(('', 8866)) # 绑定端口,接受这个端口的消息
#端口自己决定,第一个参数为空默认代表抓取本机数据
while True:
data = udp_server.recvfrom(1024)
#因为
clientAddr = data[1]
clientIp = clientAddr[0]
clientPort = clientAddr[1]
clientData = data[0]
clientData = str(clientData)
clientData = clientData.replace("'","")
clientData = clientData.replace(clientData[0],"")
print(clientData)
udp_server.close()客户端代码:
import socket
udp_client = socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
while True:
data = raw_input("please input the data: ")
data = str(data)
udp_client.sendto(data.encode('utf-8'),('xxx.xxx.xxx.xxx',8866))
#上面需要绑定接收端的IP地址和端口
udp_client.close()接着我们运行客户端和服务端程序,然后利用客户端向服务端发送数据:
客户端发送与服务器端接收:

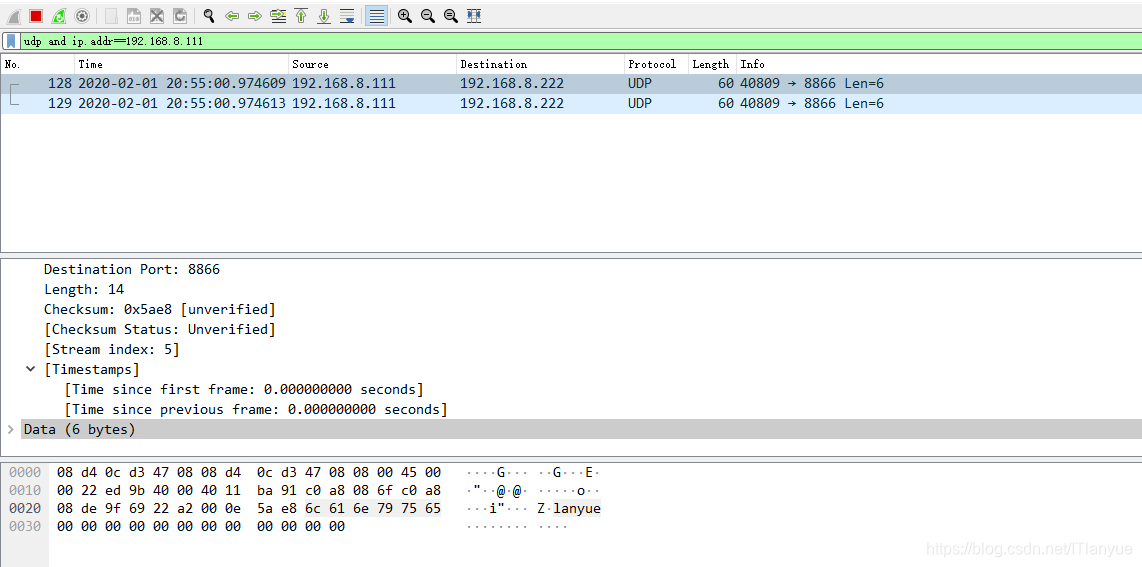
wireshark抓取:
2.数据报分析
(1)udp首部
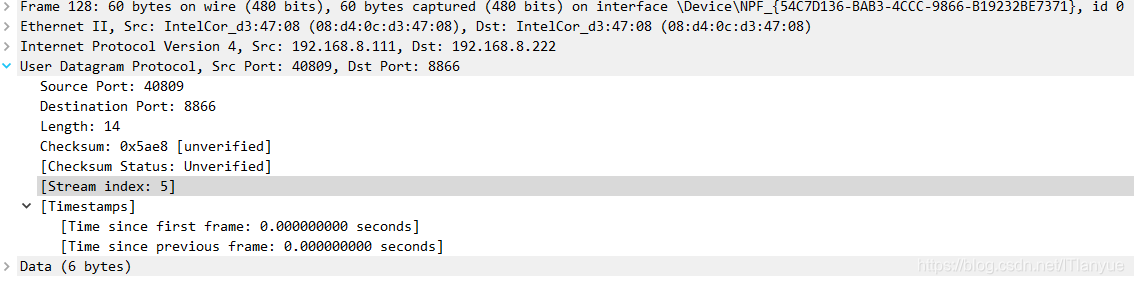
从上文中我们得知udp首部包括源端口、目的端口、长度、校验和,我们在wireshark中也可以看到这些数据
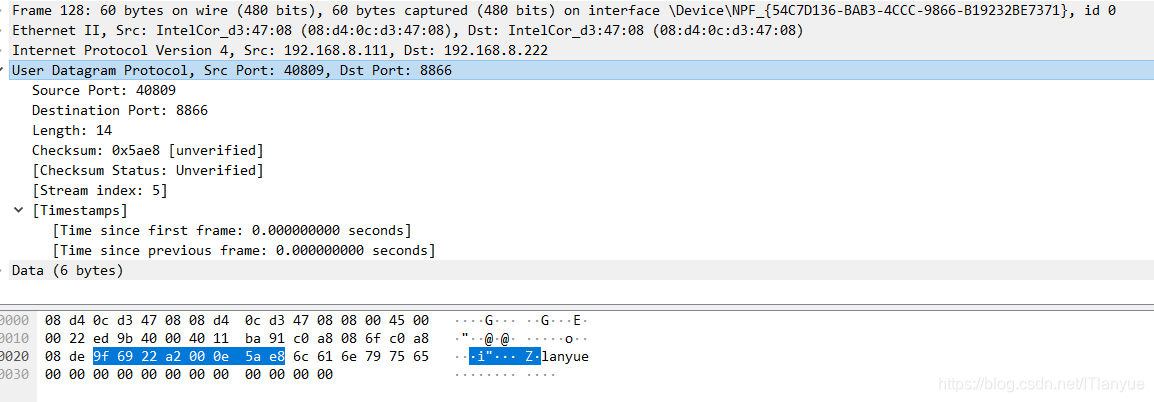
可以看到确确实实是8个字节,前两个字节对应的二进制分别如下:
1001 1111 0110 1001
0010 0010 1010 0010
(1001111101101001)B = (40809)D
(0010001010100010)B = (8866)D
言外之意就是说该UDP数据报的原端口为40809,目的端口为8866,这与wireshark分析出来的结果是一致的:

接下来我们看UDP首部的第三个字节
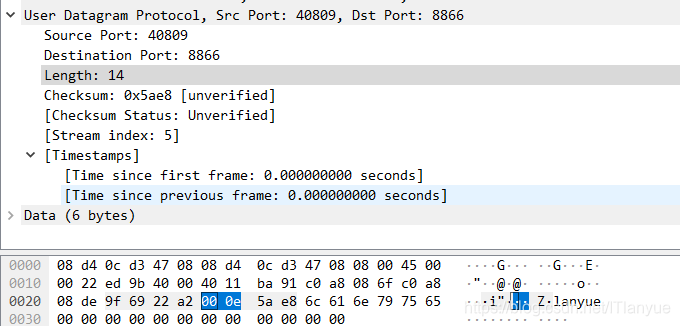
我们知道
(000E)H = (14)D,所以整个UDP数据报长14字节,而UDP首部固定长8字节,因此UDP数据部分为6字节,值如下:
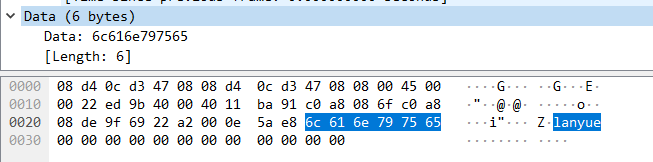
我们对这6个字节分别转换成十进制:
(6c)H = (108)D
(61)H = (97)D
(6e)H = (110)D
(79)H = (121)D
(75)H = (117)D
(65)H = (101)D
我们通过查阅ASCII码表:
| ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 |
|---|---|---|---|---|---|---|---|
| 0 | NUT | 32 | (space) | 64 | @ | 96 | 、 |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | " | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | , | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | HT | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DCI | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | TB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | / | 124 | | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ` |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
可以清楚地得知这六个字节便是 “lanyue”,即我们在客户端通过Udp协议发送的数据:
最后,我们再来分析udp首部的第7、8个也是最后两个字节 ===> 校验和,其在UDP中的数据值如下:
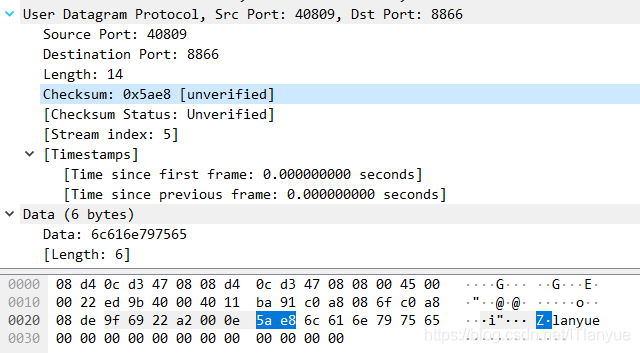
我们知道,UDP检验和的方法比较特殊。在计算检验和时,要在UDP数据报之前增加12个字节的“伪首部”。所谓“伪首部”是因为这种伪首部并不是UDP用户数 据报真正的首部,只是在计算检验和时,临时添加在UDP用户数据报前面,得到一个临时的 UDP用户数据报。检验和就是按照这个临时的UDP用户数据报来计算的。伪首部既不向下提供封装功能,也不向上提供解包功能,而仅仅是临时的为了计算检验和的数据。
具体检验方法如下:
UDP的检验和把首部和数据部分一起都检验。
在发送方:
首先,把全零放入检验和字段。
然后,把伪首部以及UDP用户数据报看成是由许多16位的字串接起来的。若UDP用户数据报的数据部分不是偶数个字节,则要填入一个全零字节(但此字节不发送)。
最后,按二进制反码计算出这些16位字的和。将此和的二进制反码 写入检验和字段后,就发送这样的UDP用户数据报。
在接收方:
首先,把收到的UDP用户数据报连同伪首部(以及可能的填充全零字节)一起,按二进制反码求这些16位字的和。
当无差错时其结果应为全1。否则就表明有差错出现,接收方就应丢弃这个UDP用户数据报(也可以上交给应用层,但附上出现了差错的警告)
