UNet语义分割:大脑MRI海马体分离
相关技术:
Python、Pytorch、U-Net
Step 01 数据集
大脑MRI数据集源于Kaggle平台,链接如下:https://www.kaggle.com/sabermalek/mrihs
原数据集中包含100个病人的大脑MRI图像,存储在文件夹original中,每张MRI图像对应的海马体分割结果则存储在文件夹label中。
从原数据集中随机抽取150张大脑MRI图像及其对应的分割结果图像,即为此次实验所采用的数据集。此次实验数据集获取方式如下:链接: https://pan.baidu.com/s/1FVsVG6XgHqF201fPlRkCYg 密码: 655b
Step 02 自定义Dataset
在Pytorch中,一般通过DataLoader来完成数据的批量导入,而如果想将数据载入DataLoader,则需要继承Dataset类并实现自己的数据集。
数据集的实现和关键代码的注释如下:
class MRIDataset(Dataset):
def __init__(self, url, transform=None):
self.imgs = glob.glob(os.path.join(url, 'img/*.jpg'))
self.transform = transform
def augment(self, img, flip):
# flip = 1: 水平翻转
# flip = 0: 垂直翻转
# flip = -1: 同时进行水平翻转和垂直翻转
img_flipped = cv2.flip(img, flip)
return img_flipped
def __getitem__(self, index):
# 通过索引获取原图和标签的URL
img_url = self.imgs[index]
label_url = img_url.replace("img", "label").replace("ACPC", "L")
# 通过cv2库读取图像
image = cv2.imread(img_url)
label = cv2.imread(label_url)
# 转换为灰度图,3通道转换为1通道
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
label = cv2.cvtColor(label, cv2.COLOR_BGR2GRAY)
# 修正标签,将海马体部分像素设置为1,非海马体部分设置为0
if label.max() > 1:
label = label / 255
label[label >= 0.5] = 1
label[label < 0.5] = 0
# 进行随机的数据增强
flip = random.choice([-1, 0, 1, 2])
if flip != 2:
image = self.augment(image, flip)
label = self.augment(label, flip)
# 转换数据
if self.transform:
image = self.transform(image)
label = self.transform(label)
return image, label
def __len__(self):
return len(self.imgs)
Step 03 构建U-Net网络
U-Net网络在医疗领域进行语义分割时效果十分优异,其网络结构如下:
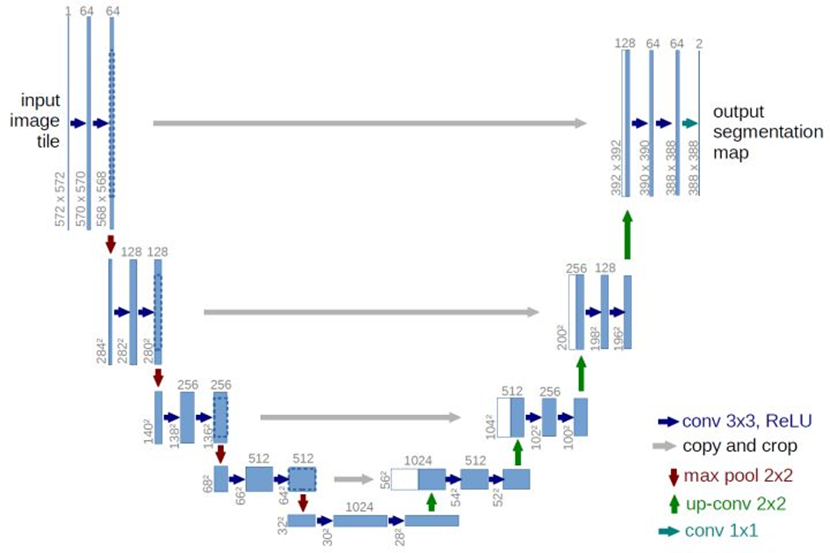
根据图示网络结构,可以知道U-Net由4个下采样层、4个上采样层以及若干卷积层构成。除此之外,还可以发现卷积往往会连续进行两次。因此,可以考虑将两个卷积层封装为一个卷积单元。
- 卷积单元
ConvUnit:
class ConvUnit(nn.Module):
def __init__(self, in_channels, out_channels):
super(ConvUnit, self).__init__()
self.unit = nn.Sequential(
# 保持图像大小
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
# 保持图像大小
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.unit(x)
- 下采样层
DownSampling:
class DownSampling(nn.Module):
def __init__(self, in_channels, out_channels):
super(DownSampling, self).__init__()
self.layer = nn.Sequential(
nn.MaxPool2d(2), # 最大池化,将图像大小变为原来的1/2
ConvUnit(in_channels, out_channels) # 卷积单元
)
def forward(self, x):
return self.layer(x)
- 上采样层
UpSampling:
class UpSampling(nn.Module):
def __init__(self, in_channels, out_channels):
super(UpSampling, self).__init__()
# 上采样层,将通道数变为1/2是为了在concat后保持通道数不变
self.layer = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
# 卷积单元
self.conv = ConvUnit(in_channels, out_channels)
def forward(self, x, r):
# 对x进行上采样,同时通道数减半
x = self.layer(x)
# 将x与r在通道维度连接,恢复原本通道数
x = torch.cat((x, r), dim=1)
return self.conv(x)
定义好了卷积单元、下采样层以及上采样层,便可以搭建一个U-Net网络,其具体实现和关键代码注释如下:
class UNet(nn.Module):
def __init__(self, in_channels, out_channels):
super(UNet, self).__init__()
# 输入层
self.conv = ConvUnit(in_channels, 64)
# 定义四个下采样层和四个上采样层
self.D1 = DownSampling(64, 128)
self.D2 = DownSampling(128, 256)
self.D3 = DownSampling(256, 512)
self.D4 = DownSampling(512, 1024)
self.U1 = UpSampling(1024, 512)
self.U2 = UpSampling(512, 256)
self.U3 = UpSampling(256, 128)
self.U4 = UpSampling(128, 64)
# 输出层,输出图像像素保持在0~1以进行二分类
self.out = nn.Sequential(
nn.Conv2d(64, out_channels, kernel_size=1),
nn.Sigmoid()
)
def forward(self, x):
# 输入和UNet的左半部分
L1 = self.conv(x)
L2 = self.D1(L1)
L3 = self.D2(L2)
L4 = self.D3(L3)
Bottom = self.D4(L4)
# UNet的右半部分和输出
R1 = self.U1(Bottom, L4)
R2 = self.U2(R1, L3)
R3 = self.U3(R2, L2)
R4 = self.U4(R3, L1)
return self.out(R4)
Step 04 训练与预测
首先定义数据加载函数如下:
def load_data(url="data", batch_size=4, shuffle=True, split=None):
# 实例化自定义Dataset,加载数据集
mri = MRIDataset(url, transform=transforms.Compose([
transforms.ToTensor()
]))
# 分割数据集
if split is None:
split = [0.7, 0.3]
n_total = len(mri)
n_train = int(split[0] * n_total)
n_test = n_total - n_train
train_set, test_set = random_split(mri, [n_train, n_test])
# 将数据集封装入DataLoader
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=shuffle)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=shuffle)
return train_loader, test_loader
定义训练函数:
def train(loader, lr=1e-3, epochs=10, model="model/model.pth", record="model/record.txt"):
assert(isinstance(loader, DataLoader))
net = UNet(1, 1) # 实例化网络
optimizer = optim.Adam(net.parameters(), lr=lr) # 优化器
criterion = nn.BCELoss() # 损失函数
record = open(record, "w")
# 开始训练
for epoch in range(epochs):
net.train()
batch_id = 1
total_batch = len(loader)
for image, label in loader:
logit = net(image)
loss = criterion(logit, label.float()) # 计算损失
# 更新模型参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_id % 4 == 0:
r = "[Epoch: {}/{}][Batch: {}/{}][Loss: {}]"\
.format(epoch + 1, epochs, batch_id, total_batch, loss.item())
print(r)
record.write(r + "\n")
batch_id += 1
record.write("[Training Finished]")
# 存储网络参数
torch.save(net.state_dict(), model)
定义预测函数:
def predict(loader, model="model/model.pth", pred_dir="data/pred"):
assert (isinstance(loader, DataLoader))
# 初始化网络并加载权重
net = UNet(1, 1)
net.load_state_dict(torch.load(model))
net.eval()
# 预测
order = 1
for image, label in loader:
pred = net(image)
for i, p in zip(image.detach().numpy(), pred.detach().numpy()):
# i: [1, w, h], p: [1, w, h]
i, p = i[0], p[0]
p[p >= 0.5] = 255
p[p < 0.5] = 0
# 存储预测结果
cv2.imwrite("{}/{}.jpg".format(pred_dir, order), i * 255)
cv2.imwrite("{}/{}_L.jpg".format(pred_dir, order), p * 255)
order += 1
训练30个epochs后效果如下: