剪枝决策树原理与Python实现
一、决策树模型
决策树(Decision Tree)是一种常见的机器学习算法,而其核心便是“分而治之”的划分策略。例如,以西瓜为例,需要判断一个西瓜是否是一个好瓜,那么就可以根据经验考虑“西瓜是什么颜色?”,如果是“青绿色”,那么接着考虑“它的根蒂是什么形态?”,如果是“蜷缩”,那么再接着考虑“敲打声音如何?”,如果是“浊响”,那么就可以判定这个西瓜可能是一个“好瓜”。
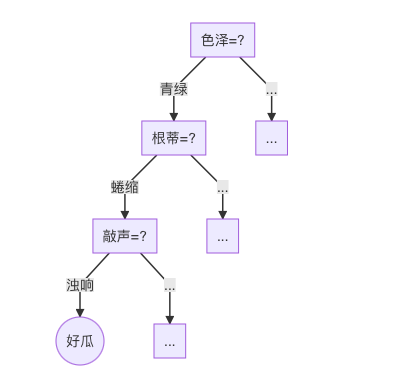
上图便是一个决策树模型基本决策流程。由上图可见,决策树模型通常包含一个根结点,若干中间节点和若干叶结点。其中,每个叶结点保存了当前特征分支\(x_i\)的标记\(y_i\),而其余的每个结点则保存了当前结点划分的特征和划分的依据(特征值)。
下面是决策树模型训练的伪代码:
生成决策树(D,F):# D为数据集,F为特征向量
生成一个结点node
1)如果无法继续划分,标记为D中样本数最多的类:
a. D中标记相同,无需划分
b. F为空,无法划分
c. D在F上取值相同,无需划分
2)如果可以继续划分:
选择最优划分属性f;
遍历D在f上的每一种取值f‘:
为node生成一个新的分支;
D‘为D在f上取值为f’的子集;
(1)如果D‘为空,将分支节点标记为D中样本最多的类;
(2)如果D’不为空,生成决策树(D',F \ {f})
二、选择划分
由前面的伪代码不难看出,生成决策树的关键在于选择最优的划分属性。为了衡量各个特征划分的优劣,这里引入了纯度(purity)的概念。即,希望随着划分的进行,决策树的分支节点所包含的样本尽可能属于同一类别。现在已经有了几种用来度量样本集纯度的指标:
2.1 信息熵和信息增益
信息熵(information entropy)是度量样本集纯度的常用指标,其定义如下:
其中,\(p_k\)为\(D\)中第\(k\)类样本所占比例,而\(Ent(D)\)越小,则说明样本集的纯度越高。
以一个选定的特征将样本划分为\(v\)个子集,则可以分别计算出这\(v\)个子集的信息熵\(Ent(D^i)\),赋予每个子集权重\(\frac{|D^i|}{|D|}\)求出各个子集信息熵的加权平均值,便可以得到划分后的平均信息熵。定义信息增益(information gain):
那么,信息增益越大,说明样本集以特征\(f\)进行划分获得的纯度提升越大(划分后子节点的平均信息熵越小)。著名的ID3决策树便是采用信息增益作为标准来选择划分属性。
2.2 增益率
通过对信息熵公式进行分析不难发现,信息增益对于可取值数目较多的特征有所偏好。因为如果D在f上可取值较多,那么划分后各个子集的纯度往往较高,信息熵也会较小,最后产生大量的分支,严重影响决策树的泛化性能。所以C4.5决策树在信息增益的基础上引入了增益率(gain rate)的概念:
其中\(IV\)称为属性f的固有值(intrinsic value),属性f的可取值数目越多,\(IV\)越大。不难看出,增益率对于属性f可取值较少的属性有所偏好,所以通常的策略是:先选择信息增益高于平均水平的属性,然后从中选择增益率最小的属性进行划分。
2.3 基尼指数
CART决策树(分类回归树)采用基尼指数(Gini index)来选择划分属性。样本集\(D\)的纯度可用基尼值来度量,其定义如下:
不难看出,\(Gini(D)\)反映了从\(D\)中任意抽取两个样本,其类标不一致的概率。因此,基尼值越小,样本集纯度越高。那么属性f的基尼指数则定义为:
因此,以基尼指数为评价标准的最优划分属性为\(f^*=\arg\min_{f\in F}Gini\_index(D, f)\)。
三、剪枝
在训练决策树模型的时候,有时决策树会将训练集的一些特有性质当作一般性质进行了学习,从而产生过多的分支,不仅效率下降还可能导致过拟合(over fitting)从而降低泛化性能。剪枝(pruning)就是通过主动去掉决策树的一些分支从而防止过拟合的一种手段。
3.1 预剪枝
预剪枝(prepruning)是指在生成决策树的过程中,对每个结点划分前进行模拟,如果划分后不能带来决策树泛化性能的提升,则停止划分并将当前结点标记为叶结点。
3.2 后剪枝
后剪枝(post-pruning)则是指在生成一棵决策树后,自下而上地对非叶结点进行考察,如果将该结点对应的子树替换为叶结点能带来泛化性能的提升,则进行替换。
3.3 剪枝示例
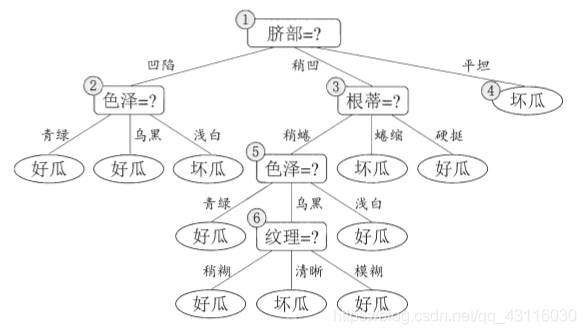
那么如何判断模型的泛化性能是否提升?举个栗子来说明(周志华《机器学习》P80-P83):假设生成的决策树如下,
预留的验证集如下:
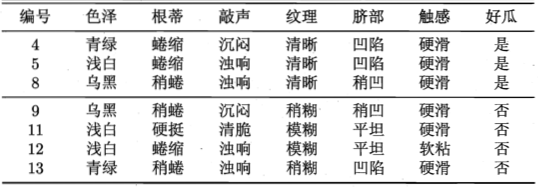
以预剪枝为例,首先看根结点。假设不进行划分,将结点1标记为\(D\)中样本最多的类别“是”,用验证集进行评估,易得准确率为\(\frac{3}{7}=42.9\%\)。如果进行划分,则结点2、3、4将分别被标记为“是”、“是”、“否”,用验证集评估则易得准确率为\(\frac{5}{7}=71.4\%>42.9\%\),所以继续划分。再看结点2,划分前验证集准确率为\(71.4\%\),划分后却下降到了\(57.1\%\),所以不进行划分。以此为例,最终可以将前面的决策树剪枝为如下形式:
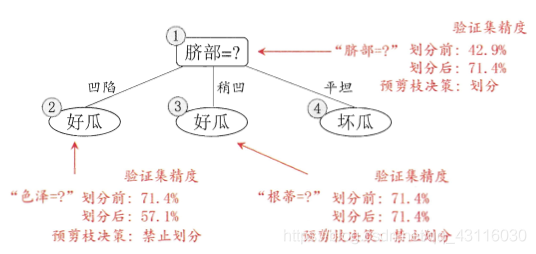
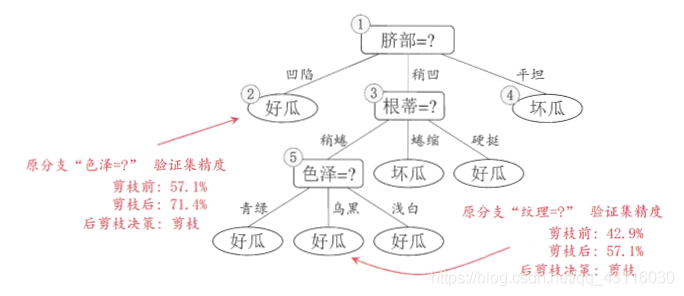
而后剪枝则只是在生成决策树后,从下往上开始判断泛化性能,这里不再赘述(详情可见周志华《机器学习》P82-P83)。后剪枝后决策树形式如下:
3.4 预剪枝和后剪枝对比
| 项目 | 预剪枝 | 后剪枝 | 不剪枝 |
|---|---|---|---|
| 时间 | 生成决策树时 | 生成决策树后 | \ |
| 方向 | 自上而下 | 自下而上 | \ |
| 效率 | 高 | 低 | 中 |
| 拟合度 | 欠拟合风险 | 拟合较好 | 过拟合风险 |
四、Python实现
4.1 基尼值和基尼指数
基尼值:
def _gini(self, y): # 基尼值
y_ps = []
y_unque = np.unique(y)
for y_u in y_unque:
y_ps.append(np.sum(y == y_u) / len(y))
return 1 - sum(np.array(y_ps) ** 2)
基尼指数:
def _gini_index(self, X, y, feature): # 特征feature的基尼指数
X_y = np.hstack([X, y.reshape(-1, 1)])
unique_feature = np.unique(X_y[:, feature])
gini_index = []
for uf in unique_feature:
sub_y = X_y[X_y[:, feature] == uf][:, X_y.shape[1] - 1]
gini_index.append(len(sub_y) / len(y) * self._gini(sub_y))
return sum(gini_index), feature
4.2 选择划分特征
划分特征的选择依赖于前面的基尼指数函数:
def _best_feature(self, X, y, features): # 选择基尼指数最低的特征
return min([self._gini_index(X, y, feature) for feature in features], key=lambda x:x[0])[1]
4.3 后剪枝算法
def _post_pruning(self, X, y):
nodes_mid = [] # 栈,存储所有中间结点
nodes = [self.root] # 队列,用于辅助广度优先遍历
while nodes: # 通过广度优先遍历找到所有中间结点
node = nodes.pop(0)
if node.sub_node:
nodes_mid.append(node)
for sub in node.sub_node:
nodes.append(sub)
while nodes_mid: # 开始剪枝
node = nodes_mid.pop(len(nodes_mid) - 1)
y_pred = self.predict(X)
from sklearn.metrics import accuracy_score
score = accuracy_score(y, y_pred)
temp = node.sub_node
node.sub_node = None
if accuracy_score(y, self.predict(X)) <= score:
node.sub_node = temp
4.4 训练算法
首先需要将数据集划分为训练集和验证集,训练集用于训练决策树,验证集用于后剪枝。训练算法按照伪代码编写即可。
def fit(self, X, y):
# 将数据集划分为训练集和验证集
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.7, test_size=0.3)
queue = [[self.root, list(range(X_train.shape[0])), list(range(X_train.shape[1]))]]
while queue: # 广度优先生成树
node, indexs, features = queue.pop(0)
node.y = ss.mode(y_train[indexs])[0][0] # 这里给每一个结点都添加了类标是为了防止测试集出现训练集中没有的特征值
# 如果样本全部属于同一类别
unique_y = np.unique(y_train[indexs])
if len(unique_y) == 1:
continue
# 如果无法继续进行划分
if len(features) < 2:
if len(features) == 0 or len(np.unique(X_train[indexs, features[0]])) == 1:
continue
# 选择最优划分特征
feature = self._best_feature(X_train[indexs], y_train[indexs], features)
node.feature = feature
features.remove(feature)
# 生成子节点
for uf in np.unique(X_train[indexs, feature]):
sub_node = Node(value=uf)
node.append(sub_node)
new_indexs = []
for index in indexs:
if X_train[index, feature] == uf:
new_indexs.append(index)
queue.append([sub_node, new_indexs, features])
self._post_pruning(X_valid, y_valid)
return self
4.6 导入鸢尾花数据集测试
导入鸢尾花数据集测试:
if __name__ == "__main__":
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import KBinsDiscretizer
from sklearn.metrics import classification_report
iris = datasets.load_iris()
X = iris.data
y = iris.target
X = KBinsDiscretizer(encode="ordinal").fit_transform(X) # 离散化
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, test_size=0.3)
classifier = DecisionTreeClassifier().fit(X_train, y_train)
y_pred = classifier.predict(X_test)
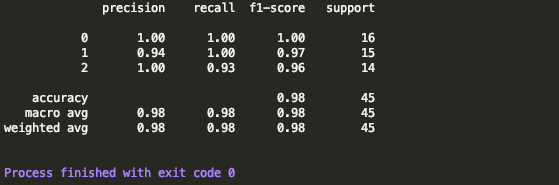
print(classification_report(y_test, y_pred))
分类报告: