MIT 6.828 实现简易操作系统 JOS
MIT 6.828 Lab1
MIT 课程实验本体 https://pdos.csail.mit.edu/6.828/2018/schedule.html
你可以在这里找到所有代码,一个实验一个分支 https://github.com/VioleshnvQuetsall/mit-6.828-lab
安装环境
编译 QEMU 并安装
QEMU 是一个虚拟机程序。
git clone https://github.com/mit-pdos/6.828-qemu.git qemu
cd qemu
./configure --disable-kvm --disable-werror --target-list="i386-softmmu x86_64-softmmu"
make && make install
编译 JOS
JOS 是我们要完善的操作系统内核。
git clone https://pdos.csail.mit.edu/6.828/2018/jos.git lab
cd lab
make
安装 32 位 gcc 后(即执行 apt-get install gcc-multilib 后)仍然报错
lib/printfmt.c:41: undefined reference to `__udivdi3'
lib/printfmt.c:49: undefined reference to `__umoddi3'
可能由于你的 gcc 版本太新了,比如我就是使用的 gcc-11。使用 update-alternatives --config gcc 切换到 gcc-7(如果没有安装需要先安装)。
运行虚拟机
运行 make qemu 开始运行虚拟机,看到 JOS 的终端。
开机
QEMU 程序
- 开始于
0xffff0执行一个跳转指令,跳转到真正的初始化程序中; - 进行一些 QEMU 已知的设备的初始化,比如时钟、VGA 显示;
- 搜索可引导扇区(以
0xaa55结尾的扇区,55在低地址,aa在高地址),读取引导扇区到内存0x7c00~0x7cdd共 256B 的位置,然后执行。
引导程序源文件为 boot/boot.S 和 boot/main.c,并且可以在 obj/boot/boot.asm 查看其编译后的汇编文件。
- 从实模式转移到 32 位保护模式以扩大寻址空间;
- 从硬盘中读取操作系统内核。
引导加载程序
现在让我们观察引导程序源文件,里面有非常丰富的注释,所以很好懂。
seta20.1:
inb $0x64,%al # Wait for not busy
testb $0x2,%al
jnz seta20.1
movb $0xd1,%al # 0xd1 -> port 0x64
outb %al,$0x64
seta20.2:
inb $0x64,%al # Wait for not busy
testb $0x2,%al
jnz seta20.2
movb $0xdf,%al # 0xdf -> port 0x60
outb %al,$0x60
轮询端口 0x64 并分别发送信号 0xd1, 0xdf 到端口 0x64, 0x60。这两个端口分别是键盘控制器的命令端口和数据端口。但键盘控制器不重要,重要的是键盘控制器有几个备用引脚被用于控制 A20 的启用/禁用。这一串命令就是为了启用 A20,作为从实模式到保护模式切换的一部分。
lgdt gdtdesc
movl %cr0, %eax
orl $CR0_PE_ON, %eax
movl %eax, %cr0
加载全局描述符 GDT,置位保护模式。
call bootmain
切换到 C 语言源文件中的程序。
// 读取 ELF 格式的操作系统内核文件,并开始执行
void bootmain(void);
// 读取内核文件指出的每个段到指定内存
void readseg(uint32_t, uint32_t, uint32_t);
// 读取一个扇区
void readsect(void*, uint32_t);
ELF(Executable and Linkable Format)是一种二进制文件的格式,(在 Linux 上)源代码经过编译和链接后获得的程序就是这种格式。这种格式包括程序的元信息、程序运行需要的被划分为多个段的数据、以及可执行代码。平时执行程序时是通过操作系统自动加载的,但这里是加载操作系统,所以需要手动加载。
至此完全进入操作系统中。
内核
地址变换
内核编译后生成的链接地址为 0xf0100000,这是一个很高的地址,机器无法提供,因此通过 kern/kernel.ld 控制链接器行为,将内核代码的加载地址设置为 0x00100000,再通过处理器的内存管理机构提供的虚拟地址变换将链接地址和加载地址映射到一起。
代码位于 kern/entry.S:
# Load the physical address of entry_pgdir into cr3.
# entry_pgdir is defined in entrypgdir.c.
movl $(RELOC(entry_pgdir)), %eax
movl %eax, %cr3
# Turn on paging.
movl %cr0, %eax
orl $(CR0_PE|CR0_PG|CR0_WP), %eax
movl %eax, %cr0
将页目录基址(定义于 kern/entrypgdir.c)的物理地址放入 CR3,其中宏 RELOC 就是为了将虚拟地址手动变换为物理地址。启动 CR0 的保护模式位(Protection Enable)、分页允许位(Paging Enable)和写保护位(Write Protect)。其中分页允许位置位时要求寻址前通过页目录进行地址变换。
格式化打印
现在终于可以开始写代码了,通过修改 kern/printf.c、lib/printfmt.c 和 kern/console.c 来实现 printf() 函数。
monitor.c就像一个简易的 Shell,交互地执行命令;printf.c格式化打印的接口cprintf();printfmt.c格式化的实现vprintfmt()。
最终打印到终端是通过位于 kern/console.c 中的函数 cputchar() 实现的,不过我们不需要太深入这个函数。只需知道是用来打印一个字符的即可。
实现八进制打印 %o,参照十进制和十六进制 %u,%x 即可。
case 'o':
num = getuint(&ap, lflag);
base = 8;
goto number;
可变参数
cprintf("x=%d y=%d", 3);
可变参数通过 va_start() 在堆栈中寻找得到,具体来说:参数从右到左依次从高到低压入堆栈。我们可以模仿这种方法来获得实际上 y 的取值。修改函数 cprintf() 为
int cprintf(const char *fmt, ...)
{
va_list ap;
int cnt;
if (*fmt == 'x')
cprintf("%d\n", *(int*)((void*)&fmt + sizeof(void*) + sizeof(int)));
va_start(ap, fmt);
cnt = vcprintf(fmt, ap);
va_end(ap);
return cnt;
}
其中 if (*fmt == 'x') 只是为了选择 "x=%d y=%d" 这个字符串;重要的是后面的 *(int*)((void*)&fmt + sizeof(void*) + sizeof(int)) 代表了一个字符串指针加一个整型的偏移,这正是 y 的输出。
然后再执行 cprintf("x=%d y=%d", 3); 可以看到两次打印的数字是相同的。
栈
调用函数时,
- 参数从右到左依次从高到低压入堆栈;
- 保存程序计数器,即
%eip入栈,修改为函数入口; - 所以程序遵守约定,将
%ebp入栈,将%esp载入%ebp。
因此可以通过 %ebp 追溯堆栈(实际上是间接通过 %esp 来追溯)。
int
mon_backtrace(int argc, char **argv, struct Trapframe *tf)
{
// Your code here.
uint32_t *p = (uint32_t *)read_ebp(); // p -> stack
while (p != 0) {
cprintf("ebp %08x "
"eip %08x "
"args %08x %08x %08x %08x %08x\n",
p, p[1], p[2], p[3], p[4], p[5], p[6]);
p = (uint32_t *)*p;
}
return 0;
}
p 是指向堆栈的指针,p 所指的内容从低到高分别是被保存的 %ebp, %eip 和五个参数。
查看操作系统入口 kern/entry.S 可知 %ebp 被初始化为 0,%esp 被初始化为 bootstacktop,指向一个大小为 KSTKSIZE 的预留空间。
movl $0x0,%ebp
movl $(bootstacktop),%esp
因此不断追溯 %ebp,最终会变为 0,将这一点作为终止条件。
通过位于 kern/kdebug.c 函数 debuginfo_eip() 还可以获得更多信息。这个函数是通过查找 ELF 格式文件的符号表段 .stab 和 .stabstr 来实现的。
.stab 段是一个 Stab 结构组成的数组。
// Entries in the STABS table are formatted as follows.
struct Stab {
uint32_t n_strx; // index into string table of name
uint8_t n_type; // type of symbol
uint8_t n_other; // misc info (usually empty)
uint16_t n_desc; // description field
uintptr_t n_value; // value of symbol
};
n_strx:根据此索引可在.stabstr找到源文件名;n_type:代表符号类型,N_FUN为函数,N_SO为源文件;n_value:这个符号的起始位置,对于源文件来说是代码起始位置,对于函数来说是入口地址。
利用函数 stab_binsearch(stabs, region_left, region_right, type, addr) 来查找类型为 type,包含 addr 的 Stab 结构,可以实现查找 %eip 所指的代码所在行。查阅 GDB 资料(粗体部分告诉我们通过查看 n_desc 可以获得行数)
An
N_SLINEsymbol represents the start of a source line. The desc field contains the line number and the value contains the code address for the start of that source line. On most machines the address is absolute; for stabs in sections (see Stab Sections), it is relative to the function in which theN_SLINEsymbol occurs.
stab_binsearch(stabs, &lline, &rline, N_SLINE, addr);
if (lline <= rline) {
// The desc field contains the line number
info->eip_line = stabs[lline].n_desc;
} else {
// Couldn't find the line number
info->eip_line = -1;
}
二分搜索获得 Stab 的索引 lline,如果没有搜索到那么将 eip_line 置为无效值 -1。
MIT 6.828 Lab2
切换到分支 lab2 后,需要关注两个旧文件和四个新文件
-
inc/memlayout.h和inc/mmu.h内存管理所需的各种定义
-
kern/pmap.c和kern/pmap.h实现内存管理文件
-
kern/kclock.h和kern/kclock.c时钟和 50B 的非易失性 RAM(NVRAM),用于在断电后保存数据,这里用于保存物理页面数。
内存管理
- 内存的分配
- 内存的映射
实现一个二级页表系统,实现后内存管理单元(mmu.h)可以控制 cr3 来达到虚拟地址空间的变换。
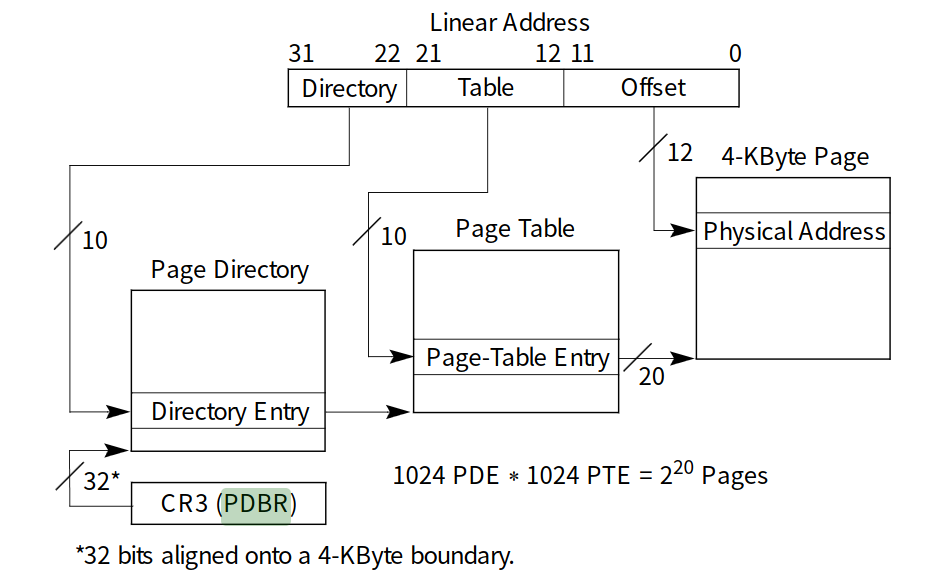
线性空间
i386_detect_memory()
basemem = nvram_read(NVRAM_BASELO);
extmem = nvram_read(NVRAM_EXTLO);
ext16mem = nvram_read(NVRAM_EXT16LO) * 64;
读取物理内存大小,这部分数据保存在 50B RAM 中。回顾物理地址空间的知识可知可用地址空间从小到大为 1MB,16MB,4GB;分别对应 20,24,32 位地址线;可用数量分别以 KB,KB,64KB 为单位储存在 NVRAM 中。
boot_alloc()
这个函数先简单分配一部分空间给内核用于建立页表系统。
result = nextfree;
n = ROUNDUP(n, PGSIZE);
if (n > ~(uint32_t)nextfree) {
panic("boot_alloc: out of memory");
}
nextfree += n;
return result;
JOS 对于内核在虚拟空间和物理空间的转换只使用了简单的线性映射,通过两个宏 PADDR(kva) KADDR(pa) 实现。所以分配物理空间和分配虚拟空间是一样的:nextfree 是虚拟地址,分配时只使用加减法,等同于对物理地址进行加减法。
注意代码中的空间变换,之前线性空间到物理空间的映射已经通过设置寄存器 cr0,cr3 启动了,而且是简单的线性映射。现在我们正在铺设给用户使用的虚拟空间,也就是建立页表。要分清代码中的地址到底是物理地址还是虚拟地址,最简单可以看类型是 physaddr_t 还是 void* uintptr_t,也可以看地址是在 KERNBASE 下还是上,还可以看所处的结构(比如页目录页表的键为虚拟、值为物理,比如 struct PageInfo 所指的是物理地址)。建立完页表后提供给 cr3 即可从硬件上进行地址变换。
虚拟空间和页表系统
mem_init()
对页表系统进行初始化,是这个文件中的顶层函数,要在实现其他函数的过程中慢慢完善它。
kern_pgdir = (pde_t *)boot_alloc(PGSIZE);
kern_pgdir[PDX(UVPT)] = PADDR(kern_pgdir) | PTE_U | PTE_P;
分配页目录,一个地址 4B,有 1024 个目录项对应 1024 个页表,这 1024 个目录项还根据 memlayout.h 中的虚拟地址空间分配。因为分配内存是按页进行分配的,页内地址(低 12 位)实际上都为 0,因此将这 12 位用作访问控制位,具体可以在 mmu.h 查看 PTE_*。
pages = (struct PageInfo *)boot_alloc(npages * (sizeof(struct PageInfo)));
memset(pages, 0, npages * sizeof(struct PageInfo));
设置好管理空闲页面(struct PageInfo)的数组 pages,数组元素全部置零(因为按页分配所以数组实际大小和元素所占大小可能不同)。接下来通过 page_init() 将空闲页面组织成链表。
page_init() 根据要求书写,不链接已经分配的页面,比如给内核分配空间时已经用的几个页面,IO 缺口的页面。最终数组中的空闲页面的链表头为 page_free_list。
void
page_init(void)
{
size_t i;
for (i = 0; i < npages; i++) {
if (i == 0 ||
(IOPHYSMEM / PGSIZE <= i && i < PADDR(boot_alloc(0)) / PGSIZE)) {
pages[i].pp_ref = 1;
pages[i].pp_link = NULL;
} else {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}
}
结合 Lab1 的物理地址来看,IOPHYSMEM 到 EXTPHYSMEM 其实就是 VGA 到 BIOS 的部分。之后就是内核使用的空间和空闲的空间。其中内核使用的也分为两部分,加载内核时使用的部分,调用 boot_alloc() 使用的部分。可以通过 boot_alloc(0) 查看空闲空间的起始地址。
+------------------+ <- 0x00100000 (1MB)
| BIOS ROM |
+------------------+ <- 0x000F0000 (960KB)
| 16-bit devices, |
| expansion ROMs |
+------------------+ <- 0x000C0000 (768KB)
| VGA Display |
+------------------+ <- 0x000A0000 (640KB)
| |
| Low Memory |
| |
+------------------+ <- 0x00000000
page_alloc() page_free()
控制页面的分配、回收
struct PageInfo *
page_alloc(int alloc_flags)
{
if (page_free_list == NULL) return NULL;
struct PageInfo *result = page_free_list;
page_free_list = page_free_list->pp_link;
result->pp_link = NULL;
if (alloc_flags & ALLOC_ZERO) {
memset(page2kva(result), 0, PGSIZE);
}
return 0;
}
void
page_free(struct PageInfo *pp)
{
if (pp->pp_ref != 0 || pp->pp_link != NULL) {
panic("page_free: pp_ref is %d and pp_link is %p",
pp->pp_ref, pp->pp_link);
}
pp->pp_link = page_free_list;
page_free_list = pp;
}
比较简单,在链表头添加元素,学过链表的一般都会了。
pgdir_walk()
尝试获取虚拟地址 va 对应页表项。
pte_t *
pgdir_walk(pde_t *pgdir, const void *va, int create)
{
pde_t *pde_p = pgdir + PDX(va);
if (!(*pde_p & PTE_P) && create) {
struct PageInfo *pt_page = page_alloc(1);
if (pt_page != NULL) {
pt_page->pp_ref++;
*pde_p = page2pa(pt_page) | PTE_U | PTE_W | PTE_P;
}
}
if (*pde_p & PTE_P) return (pte_t *)KADDR(PTE_ADDR(*pde_p)) + PTX(va);
return NULL;
}
+--------10------+-------10-------+---------12----------+
| Page Directory | Page Table | Offset within Page |
| Index | Index | |
+----------------+----------------+---------------------+
\--- PDX(la) --/ \--- PTX(la) --/ \---- PGOFF(la) ----/
\---------- PGNUM(la) ----------/
一个 32 位的地址被分为了 PDX, PTX, PGOFF 三部分,根据 PDX 找到页目录项,再根据 PTX 找到页表项。代码中 pdt_p 是页目录项的指针。由于页目录项的值为物理地址,所以需要转换为虚拟地址之后再查找页表项,也就是 pgt_p 和 PTX(va) 转换再相加的结果 (pte_t *)KADDR(PTE_ADDR(*pde_p)) + PTX(va) 则为页表项的指针。
boot_map_region()
static void
boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
// Fill this function in
size_t page_count = size / PGSIZE;
while (page_count--) {
pte_t *pte_p = pgdir_walk(pgdir, va, 1);
if (pte_p == NULL) panic("boot_map_region: pgdir_walk failed");
*pte_p = pa | perm | PTE_P;
va += PGSIZE;
pa += PGSIZE;
}
}
将虚拟地址 va~va+size 和 pa~pa+size 对应,通过 pgdir_walk 找到虚拟地址对应表项,再更改表项的地址和标志。好消息是这个函数只会被用于建立 UTOP 之上的对用户来说只读的部分的映射,不需要实际分配内存,因此不需要在函数中控制物理内存的分配;并且虚拟地址和物理地址都可以是连续的。
page_lookup() page_remove() page_insert()
查看、删除、建立虚拟内存和物理内存在页表中的映射
struct PageInfo *
page_lookup(pde_t *pgdir, void *va, pte_t **pte_store)
{
pte_t *pte_p = pgdir_walk(pgdir, va, 0);
if (pte_store != NULL) *pte_store = pte_p;
if (pte_p == NULL || !(*pte_p & PTE_P)) return NULL;
return pa2page(PTE_ADDR(*pte_p));
}
void
page_remove(pde_t *pgdir, void *va)
{
pte_t *pte_p;
struct PageInfo *pp = page_lookup(pgdir, va, &pte_p);
if (pp != NULL) {
page_decref(pp);
*pte_p = 0;
tlb_invalidate(pgdir, va);
}
}
int
page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
{
pp->pp_ref++;
page_remove(pgdir, va);
pte_t *pte_p = pgdir_walk(pgdir, va, 1);
if (pte_p == NULL) {
pp->pp_ref--;
return -E_NO_MEM;
}
*pte_p = page2pa(pp) | perm | PTE_P;
return 0;
}
重点关注 page_insert()。首先尝试直接移除对应表项的页面,不过页面有可能正好是 pp,所以先 pp_ref++,分配失败时再取消自增。
内核空间映射
之后在 mem_init() 的 check_page() 后面使用 boot_map_region() 补充更多的段映射。按照指示建立映射即可。
boot_map_region(kern_pgdir, UPAGES, PTSIZE,
PADDR(pages), PTE_U | PTE_P);
boot_map_region(kern_pgdir, KSTACKTOP - KSTKSIZE, KSTKSIZE,
PADDR(bootstack), PTE_W | PTE_P);
boot_map_region(kern_pgdir, KERNBASE, (uint32_t)0 - KERNBASE,
0, PTE_W | PTE_P);
于是就完成了 memlayout.h 中展示虚拟内存结构(的内核部分)。接下来要控制用户部分,也就是 0~UTOP 这部分。
* Virtual memory map: Permissions
* kernel/user
*
* 4 Gig --------> +------------------------------+
* | | RW/--
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* : . :
* : . :
* : . :
* |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~| RW/--
* | | RW/--
* | Remapped Physical Memory | RW/--
* | | RW/--
* KERNBASE, ----> +------------------------------+ 0xf0000000 --+
* KSTACKTOP | CPU0's Kernel Stack | RW/-- KSTKSIZE |
* | - - - - - - - - - - - - - - -| |
* | Invalid Memory (*) | --/-- KSTKGAP |
* +------------------------------+ |
* | CPU1's Kernel Stack | RW/-- KSTKSIZE |
* | - - - - - - - - - - - - - - -| PTSIZE
* | Invalid Memory (*) | --/-- KSTKGAP |
* +------------------------------+ |
* : . : |
* : . : |
* MMIOLIM ------> +------------------------------+ 0xefc00000 --+
* | Memory-mapped I/O | RW/-- PTSIZE
* ULIM, MMIOBASE --> +------------------------------+ 0xef800000
* | Cur. Page Table (User R-) | R-/R- PTSIZE
* UVPT ----> +------------------------------+ 0xef400000
* | RO PAGES | R-/R- PTSIZE
* UPAGES ----> +------------------------------+ 0xef000000
* | RO ENVS | R-/R- PTSIZE
* UTOP,UENVS ------> +------------------------------+ 0xeec00000
* | |
* | User |
* | |
* 0 ------------> +------------------------------+
MIT 6.828 Lab3
用户环境
JOS 使用环境来描述如何执行一个程序,包括程序的状态和地址空间两部分,前者又包括程序运行时的寄存器状态和其他信息,后者则用虚拟空间在页表系统中的入口表示。
struct Env
struct Env {
struct Trapframe env_tf; // Saved registers
struct Env *env_link; // Next free Env
envid_t env_id; // Unique environment identifier
envid_t env_parent_id; // env_id of this env's parent
enum EnvType env_type; // Indicates special system environments
unsigned env_status; // Status of the environment
uint32_t env_runs; // Number of times environment has run
// Address space
pde_t *env_pgdir; // Kernel virtual address of page dir
};
对于本实验只需要关注环境结构中的两个成员即可
env_pgdir该环境的虚拟地址空间。之后我们会通过lcr3(PADDR(pgdir))修改cr3的值来实现内核和用户虚拟地址空间的切换。注意代码中所有对所有常量变量的访问都会经过地址变换。env_tf该环境的各种寄存器的值,加载这些值就可以令程序运行了。
struct Segdesc
为访问代码中的一个地址中的值:
- 首先查看段寄存器的值,在全局描述符(GDT)找到其所属段;
- 段基址加上段偏移获得虚拟地址;
- 虚拟地址再经过页表系统转换获得物理地址;
- 物理地址在内存中读写数据。
以上地址转换的过程都由硬件自动完成。
struct Segdesc gdt[] =
{
// 0x0 - unused (always faults -- for trapping NULL far pointers)
SEG_NULL,
// 0x8 - kernel code segment
[GD_KT >> 3] = SEG(STA_X | STA_R, 0x0, 0xffffffff, 0),
// 0x10 - kernel data segment
[GD_KD >> 3] = SEG(STA_W, 0x0, 0xffffffff, 0),
// 0x18 - user code segment
[GD_UT >> 3] = SEG(STA_X | STA_R, 0x0, 0xffffffff, 3),
// 0x20 - user data segment
[GD_UD >> 3] = SEG(STA_W, 0x0, 0xffffffff, 3),
// 0x28 - tss, initialized in trap_init_percpu()
[GD_TSS0 >> 3] = SEG_NULL
};
GD_KD, GDKT, GD_UD, GD_UT 等都是段索引,会赋值给段寄存器。SEG(...) 就是用宏组合段基址、段长度、访问控制后的值。可以看到目前在 JOS 中段之间只有读写权限和 CPU 权限不同,因此可以说地址转换的主要部分还是在页表系统中。
初始化
mem_init()
在 mem_init() 中为环境数组分配内存,使内核开始控制环境。和物理页面 pages 的管理是类似的,做完 Lab2 应该很熟悉这些步骤了。
envs = (struct Env *)boot_alloc(NENV * sizeof(struct Env));
memset(envs, 0, NENV * sizeof(struct Env));
boot_map_region(kern_pgdir, UENVS, PTSIZE, PADDR(envs), PTE_U | PTE_P);
修改完后打算测试,发现全局变量 npages, kern_pgdir 等居然没有分配在 end 之后,导致 memset() 将它们置零。修改链接器的脚本文件的 .bss 段为
.bss : {
PROVIDE(edata = .);
*(.bss)
BYTE(0)
}
PROVIDE(end = .);
切换回 Lab2 分支才发现 Lab2 就已经有这个问题了,不过 end 此时不满一页,ROUNDUP 后剩下了一部分空间;到了 Lab3 end 又正好满一页了,没有多余的空间。
env_init()
void
env_init(void)
{
size_t i = NENV;
while (i--) {
envs[i].env_id = 0;
envs[i].env_link = env_free_list;
env_free_list = &envs[i];
}
env_init_percpu();
}
初始化环境数组和链表,要求我们数组顺序和链表顺序相同,所以从后往前连接链表。
设置环境
env_setup_vm()
建立环境的虚拟地址空间。虚拟地址空间可分为内核部分和用户部分,对于所有环境内核部分都是一样的(之后切换环境的时候也要注意),也就是说 UTOP 以上部分(除了 UVPT)env_pgdir kern_pgdir 是相同的,直接复制即可。
static int
env_setup_vm(struct Env *e)
{
int i;
struct PageInfo *p = NULL;
// Allocate a page for the page directory
if (!(p = page_alloc(ALLOC_ZERO)))
return -E_NO_MEM;
// set e->env_pgdir and initialize the page directory.
p->pp_ref++;
e->env_pgdir = (pde_t *)page2kva(p);
memcpy(e->env_pgdir + PDX(UTOP), kern_pgdir + PDX(UTOP),
PGSIZE - PDX(UTOP) * sizeof(pde_t));
// UVPT maps the env's own page table read-only.
// Permissions: kernel R, user R
e->env_pgdir[PDX(UVPT)] = PADDR(e->env_pgdir) | PTE_P | PTE_U;
return 0;
}
要建立环境的虚拟地址空间,那么需要一页物理空间来存放页目录。所有环境的虚拟地址空间的入口地址存放在内核部分 envs,以备需要的时候用 lrcr3() 切换虚拟地址空间。
env_alloc()
int
env_alloc(struct Env **newenv_store, envid_t parent_id)
{
int32_t generation;
int r;
struct Env *e;
if (!(e = env_free_list))
return -E_NO_FREE_ENV;
// Allocate and set up the page directory for this environment.
if ((r = env_setup_vm(e)) < 0)
return r;
// Generate an env_id for this environment.
generation = (e->env_id + (1 << ENVGENSHIFT)) & ~(NENV - 1);
if (generation <= 0) // Don't create a negative env_id.
generation = 1 << ENVGENSHIFT;
e->env_id = generation | (e - envs);
// Set the basic status variables.
e->env_parent_id = parent_id;
e->env_type = ENV_TYPE_USER;
e->env_status = ENV_RUNNABLE;
e->env_runs = 0;
// Clear out all the saved register state,
// to prevent the register values
// of a prior environment inhabiting this Env structure
// from "leaking" into our new environment.
memset(&e->env_tf, 0, sizeof(e->env_tf));
// Set up appropriate initial values for the segment registers.
// GD_UD is the user data segment selector in the GDT, and
// GD_UT is the user text segment selector (see inc/memlayout.h).
// The low 2 bits of each segment register contains the
// Requestor Privilege Level (RPL); 3 means user mode. When
// we switch privilege levels, the hardware does various
// checks involving the RPL and the Descriptor Privilege Level
// (DPL) stored in the descriptors themselves.
e->env_tf.tf_ds = GD_UD | 3;
e->env_tf.tf_es = GD_UD | 3;
e->env_tf.tf_ss = GD_UD | 3;
e->env_tf.tf_esp = USTACKTOP;
e->env_tf.tf_cs = GD_UT | 3;
// You will set e->env_tf.tf_eip later.
// commit the allocation
env_free_list = e->env_link;
*newenv_store = e;
cprintf("[%08x] new env %08x\n", curenv ? curenv->env_id : 0, e->env_id);
return 0;
}
env_alloc() 能给我们接下来的编程提供一点信息:
env_alloc()将已经建立好虚拟空间的环境做进一步设置,其中env_id包含了环境在数组envs中的位置。- 设置段寄存器,因为实际上地址转换要经过段、页两步,前者使用
GDT全局描述符表,后者使用 Lab2 建立的页表。 - 注释有提示之后要自己设置
tf_eip的值。
region_alloc()
为环境 e 的 va~va+len 部分分配物理空间。
static void
region_alloc(struct Env *e, void *va, size_t len)
{
// Hint: It is easier to use region_alloc if the caller can pass
// 'va' and 'len' values that are not page-aligned.
// You should round va down, and round (va + len) up.
// (Watch out for corner-cases!)
void *va_end = ROUNDUP(va + len, PGSIZE);
for (va = ROUNDDOWN(va, PGSIZE); va != va_end; va += PGSIZE) {
struct PageInfo *pp = page_alloc(0);
if (pp == NULL) panic("region_alloc: page_alloc failed");
page_insert(e->env_pgdir, pp, va, PTE_U | PTE_W | PTE_P);
}
}
注意 va + len 向上舍入,va 向下舍去,再用 page_insert() 映射物理空间和虚拟空间。
加载程序
load_icode()
加载程序到虚拟空间。
static void
load_icode(struct Env *e, uint8_t *binary)
{
struct Elf *elf = (struct Elf *)binary;
struct Proghdr *ph, *ph_end;
// is this a valid ELF?
if (elf->e_magic != ELF_MAGIC) panic("load_icode: bad ELF magic");
ph = (struct Proghdr *)((void *)elf + elf->e_phoff);
ph_end = ph + elf->e_phnum;
// change page directory
lcr3(PADDR(e->env_pgdir));
for (; ph < ph_end; ph++) {
// map and copy
if (ph->p_type != ELF_PROG_LOAD) continue;
region_alloc(e, (void *)ph->p_va, ph->p_memsz);
memcpy((void *)ph->p_va, binary + ph->p_offset, ph->p_filesz);
memset((void *)ph->p_va + ph->p_filesz, 0, ph->p_memsz - ph->p_filesz);
}
lcr3(PADDR(kern_pgdir));
// set eip to the entry point from the ELF header
e->env_tf.tf_eip = elf->e_entry;
// Now map one page for the program's initial stack
// at virtual address USTACKTOP - PGSIZE.
region_alloc(e, (void *)(USTACKTOP - PGSIZE), PGSIZE);
}
模仿 boot/main.c 中的 bootmain() 函数即可,需要注意:
- 加载程序到虚拟空间,程序是嵌入内核中的程序(因为现在没有文件系统,不能从外部调入程序),虚拟空间是属于这个程序的虚拟空间,所以需要通过
lcr3(PADDR(e->env_pgdir))切换。虚拟空间的内核是相同的,用户部分是不同的,弄明白各种变量属于内核还是用户。ebinary等代码中直接使用的变量(符号地址)在内核部分,ph->va指向的地址属于用户部分。 - 将程序入口放入
tf_eip等会载入eip时就自动完成了程序跳转。
创建和运行

env_create()
void
env_create(uint8_t *binary, enum EnvType type)
{
struct Env *e;
int r;
if ((r = env_alloc(&e, 0)) < 0) {
panic("env_create: env_alloc failed (%e)", r);
}
load_icode(e, binary);
e->env_type = type;
}
只要前面的函数正确就没多大问题。这里就完成了一个环境的建立,随时都可以调出来运行。
env_run()
void
env_run(struct Env *e)
{
if (curenv != NULL && curenv->env_status == ENV_RUNNING) {
curenv->env_status = ENV_RUNNABLE;
}
curenv = e;
e->env_status = ENV_RUNNING;
e->env_runs++;
lcr3(PADDR(e->env_pgdir));
env_pop_tf(&e->env_tf);
}
开始运行环境,设置环境运行所需的空间和状态。调用 env_pop_tf(&e->env_tf) 后 eip 被修改,跳转到环境运行入口。
env_pop_tf()
struct PushRegs {
/* registers as pushed by pusha */
uint32_t reg_edi;
uint32_t reg_esi;
uint32_t reg_ebp;
uint32_t reg_oesp; /* Useless */
uint32_t reg_ebx;
uint32_t reg_edx;
uint32_t reg_ecx;
uint32_t reg_eax;
} __attribute__((packed));
struct Trapframe {
struct PushRegs tf_regs;
uint16_t tf_es;
uint16_t tf_padding1;
uint16_t tf_ds;
uint16_t tf_padding2;
uint32_t tf_trapno;
/* below here defined by x86 hardware */
uint32_t tf_err;
uintptr_t tf_eip;
uint16_t tf_cs;
uint16_t tf_padding3;
uint32_t tf_eflags;
/* below here only when crossing rings, such as from user to kernel */
uintptr_t tf_esp;
uint16_t tf_ss;
uint16_t tf_padding4;
} __attribute__((packed));
void
env_pop_tf(struct Trapframe *tf)
{
asm volatile(
"\tmovl %0,%%esp\n"
"\tpopal\n"
"\tpopl %%es\n"
"\tpopl %%ds\n"
"\taddl $0x8,%%esp\n" /* skip tf_trapno and tf_errcode */
"\tiret\n"
: : "g" (tf) : "memory");
panic("iret failed"); /* mostly to placate the compiler */
}
movl %0,%esp将%esp指向tf以便之后用pop*加载其他寄存器popal将struct PushRegs中的通用寄存器加载- 然后依次加载
%es, %ds - 使用
iret间接弹出%eip(和%cs, %esp, %ss和eflag状态寄存器)完成程序跳转。
运行 hello 程序
i386_init() 已经提供了一个测试程序 hello,依次调用 mem_init() env_init() trap_init() env_create(_binary_obj_user_hello_start, ENV_TYPE_USER) env_run(&envs[0]) 运行。
make qemu-gdb make gdb
但如果直接运行 make qemu 那么会获得一个 Triple Fault,这是因为还没有设置中断。
尝试分别在两个终端中运行 make qemu-gdb make gdb 并观察 obj/user/hello.asm,看看是否成功跳转到程序 hello。具体来说
b *env_pop_tf在函数env_pop_tf()入口打上断点;c运行到断点处;- 连续
si单步运行,对照hello.asm,并在必要时info registers查看寄存器。
最终发现运行到 800b44: int $0x30 停止,这是一个中断命令,也是 Triple Fault 的原因。
中断和异常
中断分为陷入、异常和外部中断,Lab3 中先处理前两个。
中断或异常发生时,处理器
- 根据任务状态段(TSS)将堆栈切换为内核堆栈;
- 保存处理器状态,即各种寄存器的值
%ss%esp%eflags%cs%eip; - 根据中断号从中断描述符表(IDT)中取出中断程序入口,设置
%cs, %eip; - 将
%esp, %ss指向新的堆栈。
设置中断描述符表
查阅 Intel 80386 Reference Programmer's Manual 可知中断向量的 error code number
Description Interrupt Error CodeNumber Divide error 0 No Debug exceptions 1 No Breakpoint 3 No Overflow 4 No Bounds check 5 No Invalid opcode 6 No Coprocessor not available 7 No System error 8 Yes (always 0) Coprocessor Segment Overrun 9 No Invalid TSS 10 Yes Segment not present 11 Yes Stack exception 12 Yes General protection fault 13 Yes Page fault 14 Yes Coprocessor error 16 No Two-byte SW interrupt 0-255 No
trapentry.S
在 trapentry.S 中为中断添加入口点,.long handler##n 在代码中搜索入口地址 handler##n: 并存放到 .data 段中。
#define T(n) \
.data; \
.long handler##n; \
.text; \
TRAPHANDLER(handler##n, n)
#define T_NOEC(n) \
.data; \
.long handler##n; \
.text; \
TRAPHANDLER_NOEC(handler##n, n)
#define T_OC(n) \
.data; \
.long 0
.data
.global handler_entry
handler_entry:
.text
T_NOEC(0)
T_NOEC(1)
T_OC(2)
T_NOEC(3)
T_NOEC(4)
T_NOEC(5)
T_NOEC(6)
T_NOEC(7)
T(8)
T_NOEC(9)
T(10)
T(11)
T(12)
T(13)
T(14)
T_OC(15)
T_NOEC(16)
T_NOEC(17)
T_NOEC(18)
T_NOEC(19)
TRAPHANDLER_NOEC(handler_syscall, T_SYSCALL)
TRAPHANDLER_NOEC(handler_default, T_DEFAULT)
其中使用宏 T() 还是 T_NOEC() 要根据中断向量的 error code number 决定,T_OC() 则是占位用的(我特意令宏名称长度不一致方便区分)。此时在 .data 段中以 handler_entry 开头 handler* 依次排列,并且 handler_entry 通过 .global 导出,可以在 trap.c 中使用。
注意 .data .text 使符号表示的位置在数据段和代码段之间切换,要令 handler_entry 和 handler* 都处于 .data 段中,这样才可以通过 handler_entry 找 令其为中断入口地址到 handler*。(其实 handler_entry 就是 handler0)
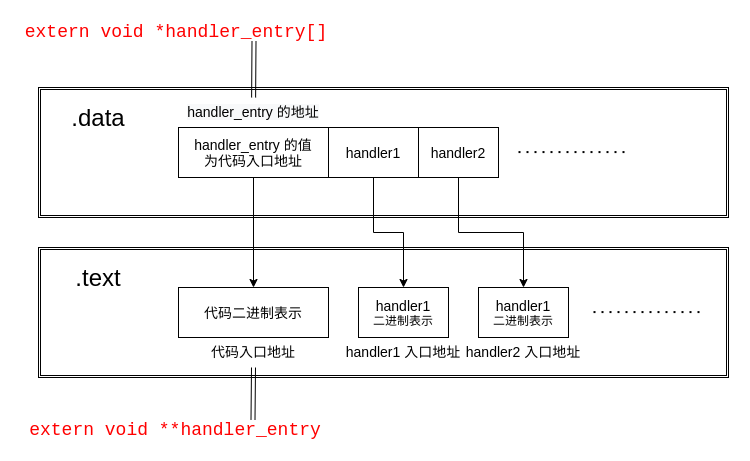
编译后的代码如下,其中
.data段中存放handler0的地址不明,handler0指向的入口地址为0xf0103f98,对应的代码二进制(前四字节)为0x006a006a;.data段中存放handler1的地址不明,handler1指向的入口地址为0xf0103f9e,对应的代码二进制(前四字节)为0x016a006a。
f0103f98 <handler0>:
.data
.global handler_entry
handler_entry:
.text
T_NOEC(0)
f0103f98: 6a 00 push $0x0
f0103f9a: 6a 00 push $0x0
f0103f9c: eb 4e jmp f0103fec <_alltraps>
f0103f9e <handler1>:
T_NOEC(1)
f0103f9e: 6a 00 push $0x0
f0103fa0: 6a 01 push $0x1
f0103fa2: eb 48 jmp f0103fec <_alltraps>
f0103fa4 <handler3>:
T_OCCU(2)
T_NOEC(3)
f0103fa4: 6a 00 push $0x0
f0103fa6: 6a 03 push $0x3
f0103fa8: eb 42 jmp f0103fec <_alltraps>
还要注意编译器在遇到 extern 时对数组和指针的对待方式不同
extern void *handler_entry[]此时handler_entry实际上是图中存放handler_entry数据的地址;extern void **handler_entry此时handler_entry实际上是图中handler_entry的值。
归根结底是因为数组和其他类型有不同,extern void** 和 extern int extern char* 等对编译器来说都是获取值(当做值);只有数组类型 extern void*[] extern char[] 之类的才会获取地址(当做数组)。
- 除此之外函数类型
extern void handler_entry()的处理方式跟数组相同。
trap_init()
最后通过 extern void *handler_entry[i] 获取 handleri 的值,在 trap.c 中补全 trap_init() 如下。注意汇编中的 handler_entry 和 C 语言中 handler_entry 的含义不同,前者为值,后者为地址。
void
trap_init(void)
{
extern struct Segdesc gdt[];
// LAB 3: Your code here.
extern void *handler_entry[];
extern void handler_syscall();
extern void handler_default();
cprintf("handler_entry %p\n", handler_entry);
for (size_t i = 0; i <= 16; i++) {
if (handler_entry[i] == 0) continue;
cprintf("handler%d %p\n", i, handler_entry[i]);
SETGATE(idt[i], 0, GD_KT, handler_entry[i], 0);
}
SETGATE(idt[T_BRKPT], 0, GD_KT, handler_entry[T_BRKPT], 3);
SETGATE(idt[T_SYSCALL], 0, GD_KT, handler_syscall, 3);
SETGATE(idt[T_DEFAULT], 0, GD_KT, handler_default, 0);
// Per-CPU setup
trap_init_percpu();
}
因为在 T_OC() 中将占位值设置为 0(前提是有效的入口地址不会为 0,这是显然的),可以检查 handler_entry[i] 是否为 0 判断是否是占位。
将有效的中断向量载入 IDT,用 SETGATE 设置为可嵌套中断,段基址为内核代码段,段偏移为中断入口地址,特权级为内核模式;不过断点中断和系统调用使用用户模式以供用户使用。
_alltraps:
其实可以观察一下函数 env_pop_tf(),其实接近是 _alltraps: 中压栈的反过程。
movl $0,%esp
popal
popl %es
popl %ds
addl $0x8,%esp
iret
iret反过来是压入%ss,%esp,%eflags,%cs,%eip,这个硬件在进入陷入时已经做好了;- 压入
%ds, %es和其他通用寄存器; - 设置
%esp为参数 0。
再通过题目中的提示
_alltraps:
pushl %ds
pushl %es
pushal
movw $GD_KD, %ax
movw %ax, %ds
movw %ax, %es
pushl %esp
call trap
处理中断
sys_call()
根据调用号处理即可
int32_t
syscall(uint32_t syscallno, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4, uint32_t a5)
{
// Call the function corresponding to the 'syscallno' parameter.
// Return any appropriate return value.
switch (syscallno) {
case SYS_cputs:
sys_cputs((const char *)a1, (size_t)a2);
return 0;
case SYS_cgetc:
return sys_cgetc();
case SYS_getenvid:
return sys_getenvid();
case SYS_env_destroy:
return sys_env_destroy((envid_t)a1);
default:
return -E_INVAL;
}
}
用户发起系统调用是通过 lib/syscall.c 中的 syscall() 而不是 kern/syscall.c 中的 syscall(),前者实际上又通过 int 0x30 跳转到后者进行处理。
我建议将 default 情况修改为
default:
panic("unsupported syscall");
return -E_INVAL;
以防忘记添加某个系统调用的转发。
trap_dispatch()
按要求实现即可,调用 syscall() 时寄存器按顺序放入。
static void
trap_dispatch(struct Trapframe *tf)
{
// Handle processor exceptions.
switch (tf->tf_trapno) {
case T_PGFLT:
page_fault_handler(tf);
return;
case T_BRKPT:
monitor(tf);
return;
case T_SYSCALL:
tf->tf_regs.reg_eax = syscall(tf->tf_regs.reg_eax,
tf->tf_regs.reg_edx,
tf->tf_regs.reg_ecx,
tf->tf_regs.reg_ebx,
tf->tf_regs.reg_edi,
tf->tf_regs.reg_esi);
return;
default:
break;
}
// Unexpected trap: The user process or the kernel has a bug.
print_trapframe(tf);
if (tf->tf_cs == GD_KT)
panic("unhandled trap in kernel");
else {
env_destroy(curenv);
return;
}
}
在 lib/libmain.c 中加入
thisenv = envs + ENVX(sys_getenvid());
使 hello 程序使用 thisenv 时不会出错。
内存检查
user_mem_check()
要考虑地址 [va, va+len] 哪里是访问异常的起始点,并赋值给 user_mem_check_addr。
- 判断是否访问
ULIM以上地址,否则出错起始点为MAX(ULIM, va); - 通过虚拟地址查找页表项的访问权限是否高于
perm,否则该页出错起始点为MAX(该页起点, va); - 赋值起始点。
int
user_mem_check(struct Env *env, const void *va, size_t len, int perm)
{
uintptr_t va_i = (uintptr_t)va;
uintptr_t va_end = ROUNDUP(va_i + len, PGSIZE);
if (va_end >= ULIM) {
user_mem_check_addr = MAX(va_i, ULIM);
return -E_FAULT;
}
pte_t *pte_p;
perm |= PTE_P;
for (va_i = ROUNDDOWN(va_i, PGSIZE); va_i != va_end; va_i += PGSIZE) {
pte_p = pgdir_walk(env->env_pgdir, (void *)va_i, 0);
if (pte_p == NULL || (*pte_p & perm) != perm) {
user_mem_check_addr = MAX(va_i, (uintptr_t)va);
return -E_FAULT;
}
}
return 0;
}
在 kern/syscall.c 的 sys_cputs() 中加入内存访问检查
user_mem_assert(curenv, s, len, PTE_U);
在 kern/trap.c 的 page_fault_handler() 中加入内核模式页面异常直接令操作系统重置的代码
if ((tf->tf_cs & 0b11) == 0) {
panic("page fault at %08x in kernel mode", fault_va);
}
MIT 6.828 Lab4
多处理器
初始化 LAPIC
引导处理器(BSP)引导操作系统后激活应用处理器(AP)。每个 CPU 有一个本地高级可编程中断控制器(local APIC)用于在多处理器系统中传递中断,使 CPU 之间能进行一定程度的沟通。
LAPIC 被硬编址到很高的物理地址,虚拟地址空间的 MMIOBASE~MMIOLIM 这 PTSIZE 大小的空间用于映射 IO,完善 kern/pmap.c 中的函数 mmio_map_region() 来将 LAPIC 的地址映射到这段区域。
LAPIC 初始化过程为
kern/mpconfig.c/mp_init()获得多处理器配置(包括 LAPIC 地址);kern/lapic.c/lapic_init()初始化 LAPIC;kern/pmap.c/mmio_map_region()映射 LAPIC。
void *
mmio_map_region(physaddr_t pa, size_t size)
{
static uintptr_t base = MMIOBASE;
uintptr_t result = base;
size = ROUNDUP(size, PGSIZE);
if (base + size >= MMIOLIM) {
panic("mmio_map_region: overflow MMIOLIM");
}
boot_map_region(kern_pgdir, base, size, pa, PTE_PCD | PTE_PWT | PTE_W);
base += size;
return (void *)result;
}
size 补齐为一页。至于要不要考虑 pa 页对齐,LAPIC 的物理地址是 0xfe000000 已经是页对齐了(其他硬编址也会是页对齐的)。
激活处理器
其他由所有 CPU 共享的全局变量已经由 BSP 处理好了,现在要对每个 AP 分别初始化。即 BSP 执行 boot_aps(),激活所有 AP。
每个 CPU 都有属于自己的状态,记录于 struct CpuInfo cpus[NCPU] 和 uchar percpu_kstacks[NCPU][KSTKSIZE] 中,包括寄存器、TSS、堆栈和当前正在执行的环境等。激活 AP 就代表着要初始化执行状态:
-
LAPIC
lapic_init() -
内核栈
mem_init_mp() -
TSS 和 TSS 描述符
trap_init_percpu() -
当前正在执行的环境
sched_yield() -
寄存器
-
控制寄存器
mpentry.S -
GDTR 和段描述符
env_init_percpu()每个 CPU 都有一个 GDTR 以寻址 GDT,但是 GDT 只需要有一个就行了,所以所有 CPU 的 GDTR 的值是相同的。
-
入口程序 mpentry.S
BSP 将 AP 的入口程序 kern/mpentry.S 置于 MPENTRY_PADDR,然后通过 LAPIC 向其他 AP 传递激活指令 AP 并令其在 MPENTRY_PADDR 处开始执行,设置好控制寄存器后跳转到 mp_main() 进行其他状态的初始化。
修改 page_init() 以避开 MPENTRY_PADDR 处开始的入口程序。
void
page_init(void)
{
size_t i;
extern unsigned char mpentry_start[], mpentry_end[];
size_t lo1 = IOPHYSMEM / PGSIZE;
size_t hi1 = PADDR(boot_alloc(0)) / PGSIZE;
size_t lo2 = MPENTRY_PADDR / PGSIZE;
size_t hi2 = ROUNDUP(mpentry_end - mpentry_start, PGSIZE) / PGSIZE + lo2;
for (i = 0; i < npages; i++) {
if (i == 0 || (lo1 <= i && i < hi1) || (lo2 <= i && i < hi2)) {
pages[i].pp_ref = 1;
pages[i].pp_link = NULL;
} else {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}
}
mpentry_end mpentry_start 在 boot_aps() 中也用到了,这两个值是入口程序的起始和结尾,两者差值为程序长度。
mem_init_mp()
映射每个 CPU 的堆栈到对应位置,在 memlayout.h 中有描述
* KERNBASE, ----> +------------------------------+ 0xf0000000 --+
* KSTACKTOP | CPU0's Kernel Stack | RW/-- KSTKSIZE |
* | - - - - - - - - - - - - - - -| |
* | Invalid Memory (*) | --/-- KSTKGAP |
* +------------------------------+ |
* | CPU1's Kernel Stack | RW/-- KSTKSIZE |
* | - - - - - - - - - - - - - - -| PTSIZE
* | Invalid Memory (*) | --/-- KSTKGAP |
* +------------------------------+ |
* : . : |
* : . : |
* MMIOLIM ------> +------------------------------+ 0xefc00000 --+
mem_init() 函数中曾经映射 bootstack 到 CPU0 的堆栈过,这里情况也是相同的,不过每个堆栈的顶部是不一样的,每个堆栈之间还有一个大小为 KSTKGAP 的不可读不可写的间隔来对每个 CPU 的堆栈进行保护。
static void
mem_init_mp(void)
{
for (size_t i = 0; i < NCPU; i++) {
uintptr_t kstactop_i = KSTACKTOP - i * (KSTKSIZE + KSTKGAP);
boot_map_region(kern_pgdir, kstactop_i - KSTKSIZE, KSTKSIZE,
PADDR(percpu_kstacks[i]), PTE_W | PTE_P);
}
}
trap_init_percpu()
内核处理陷入和异常时需要用到 TSS 和 IDT,每个 CPU 的 TSS 都是独立的。
设置每个 TSS 并将其地址放入 GDT 中,GDT 索引 (GD_TSS0 >> 3) + i 就是相应的 TSS 段。并将段选择子放入任务寄存器 tr 中,令其表示现在正在执行的任务的 TSS。
IDT 和 GDT 有点类似,内存中只保存一个中断向量表,但令每个 CPU 的 idtr 寄存器都指向它以寻址。
void
trap_init_percpu(void)
{
int i = cpunum();
struct Taskstate *cpu_ts_p = &thiscpu->cpu_ts;
// Setup a TSS so that we get the right stack
// when we trap to the kernel.
cpu_ts_p->ts_esp0 = KSTACKTOP - i * (KSTKSIZE + KSTKGAP);
cpu_ts_p->ts_ss0 = GD_KD;
cpu_ts_p->ts_iomb = sizeof(struct Taskstate);
// Initialize the TSS slot of the gdt.
gdt[(GD_TSS0 >> 3) + i] = SEG16(STS_T32A, (uint32_t)cpu_ts_p,
sizeof(struct Taskstate) - 1, 0);
gdt[(GD_TSS0 >> 3) + i].sd_s = 0;
// Load the TSS selector (like other segment selectors, the
// bottom three bits are special; we leave them 0)
ltr(GD_TSS0 + (i << 3));
// Load the IDT
lidt(&idt_pd);
}
内核锁
原子操作 lock xchg
JOS 使用内核锁确保同一时间内只有一个 CPU 能够进入内核模式。设置一个共享变量 lk,使用原子操作 xchg 来检查和设置这个变量以实现互斥锁。
static inline uint32_t
xchg(volatile uint32_t *addr, uint32_t newval)
{
// uint32_t result;
// result = *addr;
// *addr = newval;
// return result;
uint32_t result;
// The + in "+m" denotes a read-modify-write operand.
asm volatile("lock; xchgl %0, %1"
: "+m" (*addr), "=a" (result)
: "1" (newval)
: "cc");
return result;
}
注释中是这段指令的非原子操作版本。这段内联汇编分别使用了 volatile 和 lock 分别指示 GCC 编译器和 CPU 执行时不做出任何优化,防止改变指令的“读-确认-写”的过程。
- 输出:
+m指示内存*addr将会被读和写;=a指示寄存器%rax将会被写; - 输入:
1指示输入newval使用和输出%1相同的寄存器,即%rax; - 其他:
cc指示结果将影响标志寄存器。
因此这段内联汇编为分为三步:
newval载入%raxlock xchg交换*addr%rax%rax存入result
内联汇编可以从这里获得更多信息。
进入内核和离开内核
互斥锁的获取和释放已经被包装在了函数 spin_lock() 和 spin_unlock() 中,且是以忙等待的方式获取锁,也就是说等待获取锁的过程中不能执行其他操作。
根据要求在程序进出内核的时候,获取和释放锁。
// kern/init.c/i386_init()
pic_init();
lock_kernel();
boot_aps();
// kern/init.c/mp_main()
lock_kernel();
sched_yield();
// kern/trap.c/trap()
if ((tf->tf_cs & 3) == 3) {
lock_kernel();
...
}
// kern/env.c/env_run()
unlock_kernel();
env_pop_tf(&e->env_tf);
需要获取锁的地方有三处,而释放锁的地方只有一处,可以看出程序是通过那些函数进出内核的。
进程创建
调度
在 sched_yield() 实现一个简单的循环调度。
void
sched_yield(void)
{
// Implement simple round-robin scheduling.
size_t curenv_idx = curenv == NULL ? NENV - 1 : curenv - envs;
size_t count = NENV;
for (size_t i = (curenv_idx + 1) % NENV; count--; i = (i + 1) % NENV) {
if (envs[i].env_status != ENV_RUNNABLE) continue;
env_run(envs + i);
}
if (curenv != NULL && curenv->env_status == ENV_RUNNING) {
env_run(curenv);
}
// sched_halt never returns
sched_halt();
}
还要在 kern/syscall.c/syscall() 中加入对系统调用的转发
case SYS_yield:
sys_yield();
return 0;
此时用户程序可以通过 sys_yield() 来主动放弃 CPU,令调度程序启动。
系统调用
当一个进程使用系统调用 sys_exofork() 复制自己时,这个进程的寄存器被保存并进入内核。
- 父进程从系统调用返回时,返回值为子进程的
env_id,保存在%rax中。 - 子进程被创建,并设置状态为
ENV_NOT_RUNNABLE,之后会通过父进程调用sys_env_set_status令其进入就绪状态。 因为复制了父进程的寄存器(包括程序计数器),所以修改%rax = 0令其返回系统调用的值为 0(但实际上子进程没有真的系统调用)。
static envid_t
sys_exofork(void)
{
struct Env *env;
int r;
if (r = env_alloc(&env, curenv->env_id), r < 0) return r;
env->env_status = ENV_NOT_RUNNABLE;
env->env_tf = curenv->env_tf;
env->env_tf.tf_regs.reg_eax = 0;
return env->env_id;
}
static int
sys_env_set_status(envid_t envid, int status)
{
if (status != ENV_RUNNABLE && status != ENV_NOT_RUNNABLE) return -E_INVAL;
struct Env *env;
int r;
if (r = envid2env(envid, &env, 1), r < 0) return r;
env->env_status = status;
return 0;
}
sys_page_*()
处理用户页错误的系统调用,根据指示书写即可,判断比较多,但逻辑整体上是简单的。
sys_page_alloc()在va分配物理页面;sys_page_map()共享物理页面;sys_page_unmap()取消物理页面和虚拟页面的映射。
static int
sys_page_alloc(envid_t envid, void *va, int perm)
{
if (va >= (void *)UTOP || va != ROUNDDOWN(va, PGSIZE)) return -E_INVAL;
if ((perm | PTE_SYSCALL) != PTE_SYSCALL ||
(perm & (PTE_U | PTE_P)) != (PTE_U | PTE_P)) return -E_INVAL;
struct Env *env;
int r;
struct PageInfo *pp;
cprintf("[env %d] alloc\n", envid);
if (r = envid2env(envid, &env, 1), r < 0) return r;
if (pp = page_alloc(1), pp == NULL) return -E_NO_MEM;
if (r = page_insert(env->env_pgdir, pp, va, perm), r < 0) {
page_free(pp);
return r;
}
return 0;
}
static int
sys_page_map(envid_t srcenvid, void *srcva,
envid_t dstenvid, void *dstva, int perm)
{
if (srcva >= (void *)UTOP || srcva != ROUNDDOWN(srcva, PGSIZE) ||
dstva >= (void *)UTOP || dstva != ROUNDDOWN(dstva, PGSIZE)) {
return -E_INVAL;
}
if ((perm | PTE_SYSCALL) != PTE_SYSCALL ||
(perm & (PTE_U | PTE_P)) != (PTE_U | PTE_P)) return -E_INVAL;
struct Env *src, *dst;
int r;
struct PageInfo *pp;
pte_t *pte_p;
if (r = envid2env(srcenvid, &src, 1), r < 0) return r;
if (r = envid2env(dstenvid, &dst, 1), r < 0) return r;
if (pp = page_lookup(src->env_pgdir, srcva, &pte_p), pp == NULL) {
return -E_INVAL;
}
if (perm & PTE_W && !(*pte_p & PTE_W)) return E_INVAL;
if (r = page_insert(dst->env_pgdir, pp, dstva, perm), r < 0) return r;
return 0;
}
static int
sys_page_unmap(envid_t envid, void *va)
{
if (va >= (void *)UTOP && va != ROUNDDOWN(va, PGSIZE)) return -E_INVAL;
struct Env *env;
int r;
struct PageInfo *pp;
if (r = envid2env(envid, &env, 1), r < 0) return r;
page_remove(env->env_pgdir, va);
return 0;
}
并为所有新的系统调用在 syscall() 中提供转发。
页面错误处理
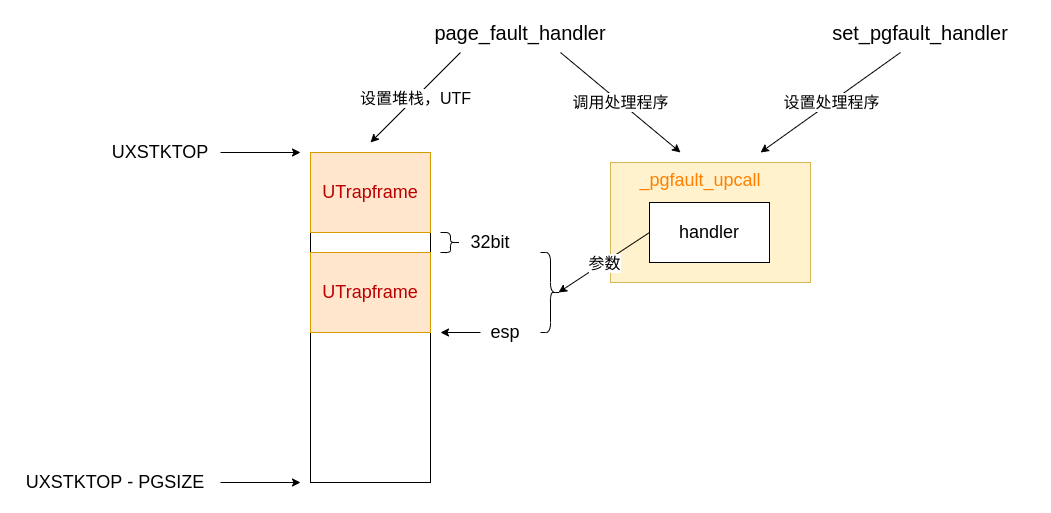
当页面错误发生时,内核将切换用户正常堆栈为用户异常堆栈,并运行用户级页面错误处理程序。
实现 sys_env_set_pgfault_upcall(),将用户级页面错误处理程序设置为用户程序想要的函数 func。
static int
sys_env_set_pgfault_upcall(envid_t envid, void *func)
{
struct Env *env;
int r;
if (r = envid2env(envid, &env, 1), r < 0) return r;
env->env_pgfault_upcall = func;
return 0;
}
page_fault_handler()
- 错误处理:错误处理程序、栈溢出、访问权限
- 将
struct UTrapframe压入堆栈,供错误处理程序使用。
void
page_fault_handler(struct Trapframe *tf)
{
uint32_t fault_va;
// Read processor's CR2 register to find the faulting address
fault_va = rcr2();
// Handle kernel-mode page faults.
if ((tf->tf_cs & 0b11) == 0) {
panic("page fault at %08x in kernel mode", fault_va);
}
// We've already handled kernel-mode exceptions, so if we get here,
// the page fault happened in user mode.
do {
if (curenv->env_pgfault_upcall == NULL) {
cprintf("curenv->env_pgfault_upcall == NULL\n");
break;
}
uintptr_t esp;
if (UXSTACKTOP - PGSIZE <= tf->tf_esp && tf->tf_esp < UXSTACKTOP) {
esp = tf->tf_esp - sizeof(struct UTrapframe) - sizeof(uint32_t);
} else {
esp = UXSTACKTOP - sizeof(struct UTrapframe);
}
cprintf("[env %d] memory check at %08x\n", curenv->env_id, fault_va);
user_mem_assert(curenv, (const void *)esp,
UXSTACKTOP - esp, PTE_W | PTE_U);
cprintf("[env %d] handle page fault at %08x\n", curenv->env_id, fault_va);
struct UTrapframe *utf = (struct UTrapframe *)esp;
utf->utf_fault_va = fault_va;
utf->utf_err = tf->tf_err;
utf->utf_regs = tf->tf_regs;
utf->utf_eip = tf->tf_eip;
utf->utf_eflags = tf->tf_eflags;
utf->utf_esp = tf->tf_esp;
tf->tf_eip = (uintptr_t)curenv->env_pgfault_upcall;
tf->tf_esp = esp;
env_run(curenv);
} while (0);
// Destroy the environment that caused the fault.
cprintf("[%08x] user fault va %08x ip %08x\n",
curenv->env_id, fault_va, tf->tf_eip);
print_trapframe(tf);
env_destroy(curenv);
return;
}
注意调用 env_run() 进入错误处理程序的时候就已经退出了内核,进入用户自定义的页错误处理程序,现在要完善 _pgfault_upcall() 来使其在用户模式正确返回。
_pgfault_upcall()
处理程序的转发程序 _pgfault_upcall(),将栈上的 utf 传递给处理程序,并在处理结束后返回令用户程序继续执行。处理结束后用户异常栈上是 struct UTrapframe,以及可能的 32 位空缺。
struct UTrapframe 中的成员被按照声明的逆顺序被压入堆栈中,现在我们要复原其中的寄存器,好让程序回到页面错误发生的位置。
按照如下顺序恢复,并且恢复之后就在恢复其他寄存器时继续使用了
- 通用寄存器
- 标志寄存器
%eflags - 栈指针
%esp - 指令指针
%eip
struct UTrapframe {
/* information about the fault */
uint32_t utf_fault_va; /* va for T_PGFLT, 0 otherwise */
uint32_t utf_err;
/* trap-time return state */
struct PushRegs utf_regs;
uintptr_t utf_eip;
uint32_t utf_eflags;
/* the trap-time stack to return to */
uintptr_t utf_esp;
} __attribute__((packed));
// trap-time esp
// trap-time eflags
// trap-time eip
// utf_regs.reg_eax
// ...
// utf_regs.reg_esi
// utf_regs.reg_edi
// utf_err (error code)
// utf_fault_va <-- %esp
通用寄存器和标志寄存器比较简单,都处于用户异常栈上。而 %esp 和 %eip 比较难,复原前者会改变当前栈(非嵌套异常则返回正常栈;嵌套异常则仍然处于异常栈中),复原后者会改变执行指令地址。并且由于通用寄存器和标志寄存器都被恢复了,所以不能使用通用寄存器和算术运算了。
因此采用:将原本的 %eip 压入原本的 %esp 中,等到 %esp 恢复后再使用 ret 指令恢复 %eip。为此原本的 %esp 下必须要有 32 位空间用来存放 %eip,因此在嵌套异常处理时 page_fault_handler() 才会空出 32 位空间。
_pgfault_upcall:
// Call the C page fault handler.
pushl %esp // function argument: pointer to UTF
movl _pgfault_handler, %eax
call *%eax
addl $4, %esp // pop function argument
movl 48(%esp), %eax // trap-time %esp
movl 40(%esp), %ecx // trap-time %eip
// push trap-time %eip onto the trap-time stack
subl $4, %eax
movl %ecx, (%eax)
movl %eax, 48(%esp)
addl $8, %esp // skip fault_va and err
popal // restore the trap-time registers
addl $4, %esp // skip %eip
popfl // restore %eflags from the stack
// Switch back to the adjusted trap-time stack.
popl %esp // restore %esp
// Return to re-execute the instruction that faulted.
ret // restore %eip
set_pgfault_handler()
void
set_pgfault_handler(void (*handler)(struct UTrapframe *utf))
{
int r;
if (_pgfault_handler == 0) {
// First time through!
// LAB 4: Your code here.
if (r = sys_page_alloc(0, (void *)(UXSTACKTOP - PGSIZE), PTE_W | PTE_U | PTE_P),
r < 0) {
panic("set_pgfault_handler: sys_page_alloc %e\n", r);
}
if (r = sys_env_set_pgfault_upcall(0, _pgfault_upcall), r < 0) {
panic("set_pgfault_handler: sys_env_set_pgfault_upcall %e\n", r);
}
}
// Save handler pointer for assembly to call.
_pgfault_handler = handler;
}
总结
总结下来:
- 用户程序调用
set_pgfault_handler()设置自己的处理程序,在设置时处理程序还会套上一层_pgfault_upcall()作为真正的处理程序; - 当真正遇到要处理错误的时候进入异常,内核交由
page_fault_handler()处理; page_fault_handler()切换用户堆栈,保存UTrapframe以供处理程序使用;page_fault_handler()跳转到_pgfault_upcall()执行并返回。
现在系统越发复杂,在实现某个功能时应该按需添加 cprintf() 为之后的调试提供方便,make grade 的评分是通过检查输出是否包含特定的行实现的,不要忘记 cprintf() 要换行。
写时复制
写时复制是一种按需分配页面的技术,父进程通过 fork() 分离出子进程后,只读地共享虚拟地址空间,直到其中一个进程尝试写入非只读的共享地址空间。为此内核需要知道写保护页面上发生的页面错误。
fork()分离子环境,复制地址空间,设置页面错误处理函数为pgfault(),其中用到duppage()duppage()将父进程的页表项复制给子进程,并将其中不是只读共享的页面标记写时复制位PTE_COW。pgfault()父子进程分离后,其中一方尝试写标记为PTE_COW的页面时进行写时复制。
其中 duppage() 是 fork() 的一部分,pgfault() 和其他两者相对独立,在 fork 分离父子进程后,pgfault() 才有可能被调用。
需要用到前面实现的系统调用和页面错误处理机制。
UVPT 和 UVPD
使用 pte_t uvpt[] 简单地寻找到指定页面。
然我们回到初始化 UVPT 的时刻。
pgdir[PDX(UVPT)] = PADDR(pgdir) | PTE_U | PTE_P;
现在如果想访问虚拟地址 (void *)UVPT + n(其中 n 在 0~PTSIZE 内),则过程为
- 寻找
pgdir[PDX(UVPT + n)]因为n在0~PTSIZE内,等于pgdir[PDX(UVPT)],即pgdir本身,为页目录,但被作为页表返回; - 此时
pgdir被视为页表,寻址pgdir[PTX(n)]仍然为一个页表(的物理地址和访问权限),但被作为页表项返回; - 在页表项
pgdir[PTX(n)]中寻址页内偏移PTE_ADDR(pgdir[PTX(n)])[PGOFF(n)]为页表项,但被作为物理地址返回。
因此 n 正好可以寻址整个页目录中所有页表的所有页目录项,如果想得到虚拟地址 va 对应的页表项可以令 n = PGNUM(va) << 2。
由于 uvpt 的类型为 pte_t[] 所以 (void *)UVPT + (PGNUM(va) << 2) == uvpt + PGNUM(va)。PGOFF 和 PGNUM 两位之差正好因为对 void* 和 pte_t* 作索引而被消除。
uvpd 用于方便地获取页表项,原理是近似的,而且也更加简单。
fork() duppage()
- 设置页面错误处理函数
pgfault(); - 分离复制进程;
- 复制地址空间,设置写时复制;
- 父进程为子进程分配异常栈、错误处理函数,最后令子进程就绪。
envid_t
fork(void)
{
extern void _pgfault_upcall(void);
int r = 0;
envid_t parent_id = sys_getenvid();
set_pgfault_handler(pgfault);
if (r = sys_exofork(), r < 0) {
panic("[parent env %d] "
"fork: sys_exofork (%e)\n", parent_id, r);
}
envid_t child_id = r;
if (child_id == 0) {
thisenv = envs + ENVX(sys_getenvid());
return 0;
}
// copy address space
for (size_t ptn = 0; ptn < UTOP / PTSIZE; ptn++) {
if (!(uvpd[ptn] & PTE_P)) continue;
size_t lim = MIN((ptn + 1) * NPTENTRIES, USTACKTOP / PGSIZE);
for (size_t pn = ptn * NPTENTRIES; pn < lim; pn++) {
if (!(uvpt[pn] & PTE_P && uvpt[pn] & PTE_U)) continue;
duppage(child_id, pn);
}
}
// alloc exception stack and set page fault upcall
if (r = sys_page_alloc(child_id, (void *)(UXSTACKTOP - PGSIZE), PTE_W | PTE_U | PTE_P),
r < 0) {
panic("[parent env %d] "
"fork: sys_page_alloc (%e)\n", parent_id, r);
}
if (r = sys_env_set_pgfault_upcall(child_id, (void *)_pgfault_upcall), r < 0) {
panic("[parent_id env %d] fork: sys_env_set_pgfault_upcall "
"for child (%e)\n", parent_id, r);
}
if (r = sys_env_set_status(child_id, ENV_RUNNABLE), r < 0) {
panic("[parent env %d] "
"fork: sys_env_set_status (%e)\n", parent_id, r);
}
return child_id;
}
for 循环将父进程和子进程正常堆栈以下的的地址空间进行共享,在这之上的异常堆栈不能共享,因为处理页面异常时需要用到异常堆栈。如果共享了异常堆栈,那么处理异常时就会因尝试写入共享空间再次触发异常,直到栈溢出。
值得注意的是,子进程的异常栈和页异常处理函数必须由父进程设置。比如不能这样
// 在子进程中自己设置页处理程序,看上去很方便,但不可行
if (child_id == 0) {
thisenv = envs + ENVX(sys_getenvid());
set_pgfault_handler(pgfault);
return 0;
}
当调用 sys_exofork() 后,父进程和子进程分离,两者几乎一样,但
- 父进程和子进程共享可写的页面都已经被设置为写时复制;
- 父进程已经设置好了异常处理程序,子进程没有;
- 父进程继续运行,子进程直到父进程用
sys_env_set_status()发出指示再到 CPU 调度前都不能运行。
不巧的是,sys_exofork() 的返回值 child_id 就在写时复制的页面中,如果没有安装好页面异常处理程序,子进程想要获取 child_id 时就会遇到异常且无法解决。所以必须通过父进程将处理程序 _pgfault_upcall() 和异常栈给子进程分配好。
duppage 将
- 只读空间简单地进行复制;
- 可写空间复制后设置为写时复制(父进程和子进程都是);
static int
duppage(envid_t envid, unsigned pn)
{
int r = 0;
void *va = (void *)(pn * PGSIZE);
int perm = PTE_U | PTE_P;
if (uvpt[pn] & (PTE_W | PTE_COW)) {
perm |= PTE_COW;
if (r = sys_page_map(0, va, envid, va, perm), r < 0) {
panic("duppage: sys_page_map failed (new mapping %e)\n", r);
}
if (r = sys_page_map(0, va, 0, va, perm), r < 0) {
panic("duppage: sys_page_map failed (our mapping %e)\n", r);
}
} else {
if (r = sys_page_map(0, va, envid, va, perm), r < 0) {
panic("duppage: sys_page_map failed (new mapping %e)\n", r);
}
}
return 0;
}
pgfault()
当进程想要写入写时复制页面时应该如何处理:
- 判断是写入写时复制页面的页面异常类型;
- 分配新的物理空间给原来的写时复制页面,这样就不会影响其他进程了。
static void
pgfault(struct UTrapframe *utf)
{
void *addr = (void *) utf->utf_fault_va;
uint32_t err = utf->utf_err;
int r;
// Check that the faulting access was (1) a write, and (2) to a
// copy-on-write page. If not, panic.
int perm = PTE_COW | PTE_U | PTE_P;
if (!(err & FEC_WR && uvpd[PDX(addr)] & PTE_P &&
(uvpt[PGNUM(addr)] & perm) == perm)) {
panic("pgfault: perm mismatch (err: %x, addr: %08x)\n", err, addr);
}
// Allocate a new page, map it at a temporary location (PFTEMP),
// copy the data from the old page to the new page, then move the new
// page to the old page's address.
addr = ROUNDDOWN(addr, PGSIZE);
if (r = sys_page_alloc(0, PFTEMP, PTE_U | PTE_W | PTE_P), r < 0) {
panic("pgfault: sys_page_alloc failed (%e)\n", r);
}
memcpy(PFTEMP, addr, PGSIZE);
if (r = sys_page_map(0, PFTEMP, 0, addr, PTE_U | PTE_W | PTE_P), r < 0) {
panic("pgfault: sys_page_map failed (%e)\n", r);
}
if (r = sys_page_unmap(0, PFTEMP), r < 0) {
panic("pgfault: sys_page_unmap failed (%e)\n", r);
}
}
遇到的一次 bug
遇到非常奇怪的错误,在执行 page_fault_handler() 中的 env_run() 之后无法成功跳转到 _pgfault_upcall(),而是反复在一些奇怪的位置产生页面错误。错误发生的位置很难追溯,怀疑是前面更底层的代码有误,最终锁定到 env.c 中。
原来是 env_setup_vm() 中 memcpy() 的大小设置错误,本意是想将内核的 UTOP 以上复制到用户空间,当大小设置为了 PGSIZE - PDX(UTOP) 实际上应该是 PGSIZE - PGD(UTOP) * sizeof(pde_t)。每当用户创建新环境时,新环境写入的大小溢出边界,修改了其他环境的目录和寄存器等值。导致用户无法正常执行内核代码,导致无法恢复的页面错误。
static int
env_setup_vm(struct Env *e)
{
int i;
struct PageInfo *p = NULL;
// Allocate a page for the page directory
if (!(p = page_alloc(ALLOC_ZERO)))
return -E_NO_MEM;
p->pp_ref++;
e->env_pgdir = (pde_t *)page2kva(p);
// wrong:
// memcpy(e->env_pgdir + PDX(UTOP), kern_pgdir + PDX(UTOP),
// PGSIZE - PDX(UTOP));
memcpy(e->env_pgdir + PDX(UTOP), kern_pgdir + PDX(UTOP),
PGSIZE - PDX(UTOP) * sizeof(pde_t));
// UVPT maps the env's own page table read-only.
// Permissions: kernel R, user R
e->env_pgdir[PDX(UVPT)] = PADDR(e->env_pgdir) | PTE_P | PTE_U;
cprintf("env_set_vm()\n");
return 0;
}
进程交互
外部中断
使能
在进入用户模式时启用外部中断,在进入内核模式时禁用外部中断。在 env_alloc() 中加入
e->env_tf.tf_eflags |= FL_IF;
这样每次进入用户环境时,%eflags 被加载,就使能了外部中断。
入口
#define FILL_LONG(begin, end) \
.data; \
.fill ((end) - (begin) - 1), 4, 0
.data
FILL_LONG(16, 32)
T_NOEC(32)
T_NOEC(33)
FILL_LONG(33, 36)
T_NOEC(36)
FILL_LONG(36, 39)
T_NOEC(39)
FILL_LONG(39, 46)
T_NOEC(46)
FILL_LONG(46, 51)
T_NOEC(51)
加载中断向量的 trap_init() 函数也做相应改变。
时钟
在 trap_dispatch() 中添加对时钟中断的转发
if (tf->tf_trapno == IRQ_OFFSET + IRQ_TIMER) {
lapic_eoi();
sched_yield();
return;
}
进程间通信
系统调用 sys_ipc_*()
static int
sys_ipc_try_send(envid_t envid, uint32_t value, void *srcva, unsigned perm)
{
struct Env *env;
int r;
struct PageInfo *pp;
pte_t *pte_p;
if (r = envid2env(envid, &env, 0), r < 0) return r;
if (!env->env_ipc_recving) return -E_IPC_NOT_RECV;
if (srcva < (void*)UTOP) {
if (srcva != ROUNDDOWN(srcva, PGSIZE) ||
(perm | PTE_SYSCALL) != PTE_SYSCALL ||
(perm & (PTE_U | PTE_P)) != (PTE_U | PTE_P)) return -E_INVAL;
pp = page_lookup(curenv->env_pgdir, srcva, &pte_p);
if (pp == NULL || (perm & PTE_W && !(*pte_p & PTE_W))) return -E_INVAL;
if (env->env_ipc_dstva < (void*)UTOP) {
page_insert(env->env_pgdir, pp, env->env_ipc_dstva, perm);
env->env_ipc_perm = perm;
}
} else {
env->env_ipc_perm = 0;
}
env->env_ipc_recving = 0;
env->env_ipc_from = curenv->env_id;
env->env_ipc_value = value;
env->env_tf.tf_regs.reg_eax = 0;
env->env_status = ENV_RUNNABLE;
return 0;
}
static int
sys_ipc_recv(void *dstva)
{
if (dstva < (void *)UTOP && dstva != ROUNDDOWN(dstva, PGSIZE)) {
return -E_INVAL;
}
curenv->env_ipc_recving = 1;
curenv->env_status = ENV_NOT_RUNNABLE;
curenv->env_ipc_dstva = dstva;
sys_yield();
return 0;
}
实现这两个函数的时候不能调用 sys_page_*() 等系统调用,因为这些系统调用获取环境的时候使用了 checkperm 对环境之间的关系进行了检查。而环境间(进程间)通信是任意两个环境都可以进行的。
调用了 sys_ipc_recv() 之后通过 sys_yield() 将 CPU 让出,同时因为已经将环境的状态设置为了无法运行(ENV_NOT_RUNNABLE),所以直到有另一个环境使用 sys_ipc_try_send() 对它发送消息为止都无法继续进行。因此调用 sys_ipc_recv() 之后并不会真正从 return 返回,而是在接收到消息之后由发送消息的环境对它的返回值 reg_eax 和状态进行设置,等到 CPU 调度时再将 reg_eax 作为返回值。
库函数
按要求书写即可。
int32_t
ipc_recv(envid_t *from_env_store, void *pg, int *perm_store)
{
envid_t env;
int perm;
int32_t value;
if (pg == NULL) pg = (void *)UTOP;
if ((value = sys_ipc_recv(pg))) {
env = perm = 0;
} else {
env = thisenv->env_ipc_from;
perm = thisenv->env_ipc_perm;
value = thisenv->env_ipc_value;
}
if (from_env_store != NULL) *from_env_store = env;
if (perm_store != NULL) *perm_store = perm;
return value;
}
void
ipc_send(envid_t to_env, uint32_t val, void *pg, int perm)
{
int r;
if (pg == NULL) pg = (void *)UTOP;
while ((r = sys_ipc_try_send(to_env, val, pg, perm))) {
if (r != -E_IPC_NOT_RECV) panic("ipc_send: %e", r);
sys_yield();
}
}
primes.c
这是一个利用进程间通信打印素数的程序。
unsigned
primeproc(void)
{
int i, id, p;
envid_t envid;
// fetch a prime from our left neighbor
do {
p = ipc_recv(&envid, 0, 0);
cprintf("CPU %d: %d ", thisenv->env_cpunum, p);
// fork a right neighbor to continue the chain
if ((id = fork()) < 0) panic("fork: %e", id);
} while (id == 0);
// filter out multiples of our prime
while (1) {
i = ipc_recv(&envid, 0, 0);
if (i % p) ipc_send(id, i, 0, 0);
}
}
void
umain(int argc, char **argv)
{
int i = 2, id = fork();
// fork the first prime process in the chain
if (id < 0) panic("fork: %e", id);
if (id == 0) primeproc();
// feed all the integers through
while (1) ipc_send(id, i++, 0, 0);
}
所以进程形成一个进程链,每个进程都持有一个素数 p,第一个进程将自然数依次传递给第二个进程,随后数字在进程链中用 i % p 对非素数进行“过滤”。当新的素数传递到进程链末尾时,再次创建新的进程。重复此过程直到用尽进程。
MIT 6.828 Lab5
文件系统
JOS 是单用户系统,没有文件权限的概念。UNIX 文件系统在目录中保存文件名和一个指向文件元数据的指针,而 JOS 将把文件名和元数据直接存储在目录中。
实现一个特殊环境,用于(协助其他环境)创建、读取、写入和删除按分层目录结构组织的文件,这个环境被称为文件系统环境(FS)。
IO 特权级
磁盘 IO 处于没有被映射到虚拟内存的 IO 空间中(不像 LAPIC),需要设置 %eflags 的 IOPL 位:如果当前代码的特权级 CPL 高于 IO 特权级 IOPL 时(数值越小,特权级越高),允许进行 IO。
在 env_create() 中加入
if (type == ENV_TYPE_FS) {
e->env_tf.tf_eflags = (e->env_tf.tf_eflags & ~FL_IOPL_MASK) | FL_IOPL_3;
}
将 IO 特权级设置为最低级 FL_IOPL_3,这样这个环境中的代码都能执行 IO 操作。ENV_TYPE_FS 则是操作系统指定的用于文件读写的程序 fs 则允许进行磁盘 IO。
块缓存
文件系统环境(FS)将整块磁盘映射于它的虚拟空间中,但不一定分配实际的物理内存。现在实现按需读取磁盘并分配物理空间(就如同处理其他环境的页面错误一样)。
完善 fs/bc.c 中处理磁盘块缓存缺失的函数 bc_pgfault()。以及将修改后的块缓存写入磁盘的函数 flush_block(),这样在块缓存退出物理空间后可以保证磁盘数据的正确。
static void
bc_pgfault(struct UTrapframe *utf)
{
void *addr = (void *) utf->utf_fault_va;
uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE;
int r;
// Check that the fault was within the block cache region
if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE))
panic("page fault in FS: eip %08x, va %08x, err %04x",
utf->utf_eip, addr, utf->utf_err);
// Sanity check the block number.
if (super && blockno >= super->s_nblocks)
panic("reading non-existent block %08x\n", blockno);
// Allocate a page in the disk map region, read the contents
// of the block from the disk into that page.
addr = ROUNDDOWN(addr, PGSIZE);
r = sys_page_alloc(0, addr, PTE_W | PTE_U | PTE_P);
if (r < 0) panic("bc_pgfault: sys_page_alloc failed (%e)", r);
r = ide_read(blockno * BLKSECTS, addr, PGSIZE / SECTSIZE);
if (r < 0) panic("bc_pgfault: ide_read failed (%e)", r);
// Clear the dirty bit for the disk block page since we just read the
// block from disk
if ((r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL)) < 0)
panic("in bc_pgfault, sys_page_map: %e", r);
// Check that the block we read was allocated. (exercise for
// the reader: why do we do this *after* reading the block
// in?)
if (bitmap && block_is_free(blockno))
panic("reading free block %08x\n", blockno);
}
void
flush_block(void *addr)
{
uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE;
if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE))
panic("flush_block of bad va %08x", addr);
if (!va_is_mapped(addr) || !va_is_dirty(addr)) return;
int r;
addr = ROUNDDOWN(addr, PGSIZE);
r = ide_write(blockno * BLKSECTS, addr, PGSIZE / SECTSIZE);
if (r < 0) panic("flush_block: ide_write failed %e", r);
r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL);
if (r < 0) panic("flush_block: sys_page_map failed %e", r);
}
在经过前面的实验后,这些函数的实现应该是比较简单的,只需要注意虚拟内存页面、块、扇区之间的关系即可。
实现了这两个函数后,尝试读取磁盘就等同于读取文件系统环境的虚拟内存,块缓存异常处理函数 bc_pgfault() 会帮助恢复缺失的块缓存。
复制
JOS 采用位图记录空闲块。
int
alloc_block(void)
{
for (size_t i = 0; i < super->s_nblocks / 32 + 1; i++) {
uint32_t line = bitmap[i];
if (line == 0) continue;
size_t lim = MIN(32, super->s_nblocks - i * 32);
for (size_t j = 0; j < lim; j++) {
if (line & (1 << j)) {
bitmap[i] &= ~(1 << j);
flush_block(diskaddr(2));
return i * 32 + j;
}
}
}
return -E_NO_DISK;
}
文件系统的基础设施
在开始写代码前可以看一下其他函数是怎么写的,可以更了解一些工具函数的使用方法。
file_block_walk()
需要通过 ppdiskbno 返回文件的保存第 filebno 个盘块的地址的指针,也就是说根据这个指针可以修改所指向的盘块号。
从盘块号转换为虚拟地址需要使用 diskaddr(),因为前面实现了块缓存,所以虚拟地址和磁盘地址是相同的。f_direct 中的每一项都是盘块号;f_indirect 也是盘块号。f_direct 直接获取盘块号即可,而 f_indirect 需要再次访问虚拟空间以找到对应地址(就像在页表中得到对应页表项一样,不过这里只需要一次间址即可)。
static int
file_block_walk(struct File *f, uint32_t filebno, uint32_t **ppdiskbno, bool alloc)
{
// LAB 5: Your code here.
if (filebno >= NDIRECT + NINDIRECT) return -E_INVAL;
if (filebno < NDIRECT) {
*ppdiskbno = f->f_direct + filebno;
return 0;
}
uint32_t *addr;
if (f->f_indirect != NULL) {
addr = diskaddr(f->f_indirect);
} else if (alloc) {
int alloc_blockno = alloc_block();
if (alloc_blockno < 0) return -E_NO_DISK;
f->f_indirect = alloc_blockno;
addr = diskaddr(alloc_blockno);
memset(addr, 0, BLKSIZE);
flush_block(addr);
} else return -E_NOT_FOUND;
*ppdiskbno = addr + filebno - NDIRECT;
return 0;
}
file_get_block()
int
file_get_block(struct File *f, uint32_t filebno, char **blk)
{
// LAB 5: Your code here.
uint32_t *blockno_p;
int r;
if (r = file_block_walk(f, filebno, &blockno_p, 1), r < 0) return r;
if (*blockno_p == 0) {
if (r = alloc_block(), r < 0) return r;
*blockno_p = r;
}
*blk = diskaddr(*blockno_p);
return 0;
}
接口
- 文件信息
struct File保存在磁盘上,并映射到文件系统环境的虚拟空间中; - 文件系统环境保存已打开文件的具体信息
struct OpenFile; - 其他环境持有文件描述符
struct Fd通过文件系统给予的接口对文件进行操作;
其中 struct OpenFile 是 struct File 和 struct Fd 的桥梁。
以 IPC 为底层接口,文件系统环境将通过 IPC 传递的 32 位值作为服务的类型,共享的页面作为更具体的服务参数(类型为 union Fsipc):
- 打开文件
serve_open(),共享的页面中包含文件路径和打开模式; - 设置文件大小
serve_set_size(),共享的页面中包含打开文件 id 和打开模式; - 读取文件
serve_read(),共享的页面中包含打开文件 id 和读取长度,读取到的文件数据后也用其返回; - 写入文件
serve_write(),共享的页面中包含打开文件 id 和打开模式;
文件系统环境处理请求时,总是将页面映射到 (union Fsipc *)0x0ffff000;而其他环境进行请求时,总把页面映射到 union Fsipc fsipcbuf(一个全局变量)。
文件系统的实现是一次很好的从接口到实现的实践:对用户来说一步步抽象,提供简洁而安全的接口;对系统来说一步步具体,将接口转发为实际的操作。
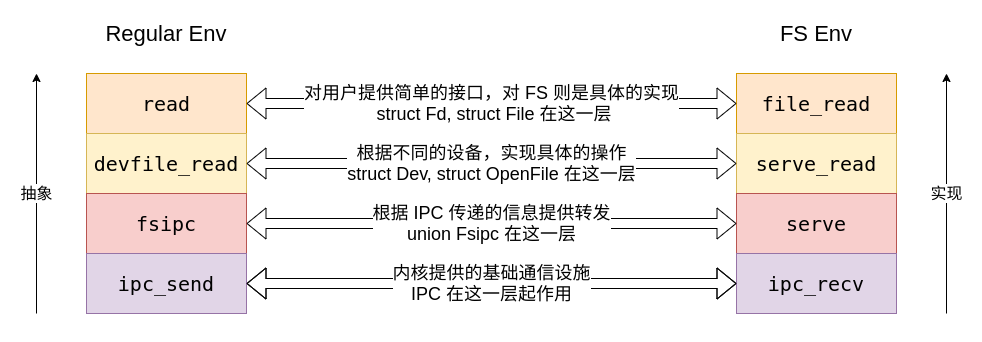
上图是对应文件系统的服务实现过程。文件系统实现了对一般的文件的操作,但还有其他特殊的文件,比如管道和控制台 IO。
不同的文件类型有不同的操作,然而对于用户来说,所有文件都使用 struct Fd 进行描述。为了实现这一点才出现了第三层 devfile_*(),这一层将文件的操作根据文件的类型分发给不同的设备 struct Dev。struct Dev 是每个文件类型的具体操作的集合,对于一般的文件类型,操作通过 struct Dev 经由底层的进程通信机制转发给 struct OpenFile;而对于其他文件类型,则不一定用到进程通信,比如管道是通过共享内存,控制台 IO 是通过系统调用来实现的。
服务端
完善文件系统的服务函数 serve_read() serve_write()。
int
serve_read(envid_t envid, union Fsipc *ipc)
{
struct Fsreq_read *req = &ipc->read;
struct Fsret_read *ret = &ipc->readRet;
if (debug)
cprintf("serve_read %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
int r;
struct OpenFile *o;
r = openfile_lookup(envid, req->req_fileid, &o);
if (r < 0) return r;
size_t n = MIN(req->req_n, sizeof(ret->ret_buf));
r = file_read(o->o_file, ret->ret_buf, n, o->o_fd->fd_offset);
if (r < 0) return r;
o->o_fd->fd_offset += r;
return r;
}
int
serve_write(envid_t envid, struct Fsreq_write *req)
{
if (debug)
cprintf("serve_write %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
int r;
struct OpenFile *o;
r = openfile_lookup(envid, req->req_fileid, &o);
if (r < 0) return r;
size_t n = MIN(req->req_n, sizeof(req->req_buf));
r = file_write(o->o_file, req->req_buf, n, o->o_fd->fd_offset);
if (r < 0) return r;
o->o_fd->fd_offset += r;
return r;
}
用户端
完善用户环境的接口程序 devfile_write()。
static ssize_t
devfile_write(struct Fd *fd, const void *buf, size_t n)
{
int r;
int count = 0;
fsipcbuf.write.req_fileid = fd->fd_file.id;
while (n) {
size_t c = MIN(n, sizeof(fsipcbuf.write.req_buf));
n -= c;
fsipcbuf.write.req_n = c;
memcpy(fsipcbuf.write.req_buf, buf, c);
buf += c;
if (r = fsipc(FSREQ_WRITE, NULL), r < 0) return r;
count += r;
}
return count;
}
运行文件
spawn()
文件系统已经基本实现,现在可以实现从文件系统中读取文件运行了,即 spawn()。这个函数读取文件并为其设置环境,后半部分在还没有实现文件系统时就已经做好了,而前半部分就是读取文件,也已经实现了。所以函数虽长,但其实不难。
- 读取文件;
- 设置环境,加载文件段;
- 设置用户堆栈,以传递主函数的参数;
- 加载设置好的
%esp%eip,启动环境。
其中父进程设置好子进程的寄存器(主要是 %esp %eip),再设置给子环境。为此需要完善系统调用 sys_env_set_trapframe(),其中设置权限的部分可以参考 env_alloc()。
static int
sys_env_set_trapframe(envid_t envid, struct Trapframe *tf)
{
struct Env *env;
int r;
if (r = envid2env(envid, &env, 1), r < 0) return r;
// to keep original tf unchanged
env->env_tf = *tf;
tf = &env->env_tf;
tf->tf_ds = GD_UD | 3;
tf->tf_es = GD_UD | 3;
tf->tf_ss = GD_UD | 3;
tf->tf_cs = GD_UT | 3;
tf->tf_eflags = (tf->tf_eflags & ~FL_IOPL_MASK) | FL_IOPL_0 | FL_IF;
return 0;
}
为了提供进程之间更好的交互,比如文件描述符的共享、借由管道控制数据流在多个进程的流动。需要实现除 IPC 以外的进程通信方法,添加 PTE_SHARE 允许进程之间进行页面共享,而且不再是只读共享。修改 duppage() 和 copy_shared_pages()。这两者都对页面在父子进程中进行了共享,只不过前者用于 fork() 需要复制父进程的数据,后者用于 spawn() 创建一个几乎全新的进程。
static int
duppage(envid_t envid, unsigned pn)
{
int r = 0;
void *va = (void *)(pn * PGSIZE);
int perm = PTE_U | PTE_P;
if (uvpt[pn] & PTE_SHARE) {
if (r = sys_page_map(0, va, envid, va, uvpt[pn] & PTE_SYSCALL), r < 0) {
panic("duppage: sys_page_map failed (share mapping %e)", r);
}
} else if (uvpt[pn] & (PTE_W | PTE_COW)) {
perm |= PTE_COW;
if (r = sys_page_map(0, va, envid, va, perm), r < 0) {
panic("duppage: sys_page_map failed (new mapping %e)\n", r);
}
if (r = sys_page_map(0, va, 0, va, perm), r < 0) {
panic("duppage: sys_page_map failed (our mapping %e)\n", r);
}
} else {
if (r = sys_page_map(0, va, envid, va, perm), r < 0) {
panic("duppage: sys_page_map failed (new mapping %e)\n", r);
}
}
return 0;
}
static int
copy_shared_pages(envid_t child)
{
int r;
int perm = PTE_P | PTE_U | PTE_SHARE;
for (size_t ptn = 0; ptn < UTOP / PTSIZE; ptn++) {
if (!(uvpd[ptn] & PTE_P)) continue;
size_t lim = MIN((ptn + 1) * NPTENTRIES, USTACKTOP / PGSIZE);
for (size_t pn = ptn * NPTENTRIES; pn < lim; pn++) {
if ((uvpt[pn] & perm) != perm) continue;
void *va = (void *)(pn * PGSIZE);
if (r = sys_page_map(0, va, child, va, uvpt[pn] & PTE_SYSCALL),
r < 0) {
return r;
}
}
}
return 0;
}
Shell
输入中断
JOS 的 Shell 被作为一个用户程序,之前的终端输入都是在内核的 monitor() 函数中通过轮询输入缓存实现的。现在需要令输入能够通过中断的方式被检测。启用键盘中断和串口中断,转发到对应中断处理函数。
if (tf->tf_trapno == IRQ_OFFSET + IRQ_KBD) {
kbd_intr();
return;
}
if (tf->tf_trapno == IRQ_OFFSET + IRQ_SERIAL) {
serial_intr();
return;
}
功能
输入重定向
case '<': // Input redirection
// Grab the filename from the argument list
if (gettoken(0, &t) != 'w') {
cprintf("syntax error: < not followed by word\n");
exit();
}
if (fd = open(t, O_RDONLY), fd < 0) {
cprintf("open %s for reading: %e", t, fd);
exit();
}
if (fd != 0) {
dup(fd, 0);
close(fd);
}
break;
MIT 6.828 Lab6
网卡初始化
服务器
QEMU 连接到主机的端口,充当真实主机和虚拟网络中的
将使用 lwIP 协助开发。
网络驱动
时钟计数器
超时处理需要用到时钟。在 kern/trap.c 中处理时钟中断的情况中加入时钟计数器。当时钟中断到来时,每个 CPU 都会进行处理,为了防止多个 CPU 都增加时钟计数器,限定只有第一个 CPU 可以增加时钟。
if (tf->tf_trapno == IRQ_OFFSET + IRQ_TIMER) {
if (thiscpu->cpu_id == cpus[0].cpu_id) time_tick();
lapic_eoi();
sched_yield();
return;
}
每个 tick 代表 10ms,在 kern/syscall.c 中加入查询当前系统时间的系统调用。别忘了添加转发。
static int
sys_time_msec(void)
{
// return ticks * 10;
return time_msec();
}
E1000
使用 E1000 网卡,为 PCI 设备。启动 PCI 设备的基础函数已经为我们写好。从 pci_init() 开始,扫描 PIC 总线上的设备,并搜索 pci_attach_class pci_attach_vendor 尝试启动。
struct pci_driver pci_attach_vendor[] 保存了用于匹配 PCI 设备的 ID 和启动该设备的函数。E1000 的启动函数保存在这个列表。查询手册的 5.2 节可知 E1000 网卡的 vendor ID (厂商 ID,对于 Intel 来说是 0x8086)和 设备 ID(本实验的芯片型号为 82540EM,ID 为 0x100e)。
在头文件 kern/e1000.h 添加
#include <kern/pci.h>
#define E1000_VENDOR_ID 0x8086
#define E1000_DEV_ID 0x100E
void pci_func_enable(struct pci_func *f);
int e1000_attach(struct pci_func *pcif);
为方便,复制 QEMU 的头文件 qemu/hw/net/e1000_regs.h 到自己的头文件中,里面有许多方便的定义。
在文件 kern/e1000.c 添加启动网卡 E1000 的函数。开始时,只需要简单地通过已经写好的函数 pci_func_enable() 进行启动即可。接下来会逐渐增加这个函数的内容。
int
e1000_attach(struct pci_func *pcif) {
pci_func_enable(pcif);
return 0;
}
将 E1000 映射到内存中,就像多处理器实验中 LAPIC 的情况一样。
void
lapic_init(void)
{
if (!lapicaddr) return;
lapic = mmio_map_region(lapicaddr, 4096);
....
}
在调用 pci_func_enable() 启动 E1000 时,E1000 的物理地址和长度就已经写入 pcif 中了。你可以通过设置 pci_show_addrs = 0 在启动 JOS 时查看到输出,被硬编址的物理地址和 IO 端口。
mem region 0: 131072 bytes at 0xfebc0000
io region 1: 64 bytes at 0xc000
现在修改 e1000_attach() 为
#define E1000_REG(OFFSET) (e1000[(OFFSET) / 4])
volatile uint32_t *e1000;
int
e1000_attach(struct pci_func *pcif) {
pci_func_enable(pcif);
e1000 = mmio_map_region(pcif->reg_base[0], pcif->reg_size[0]);
// cprintf("e1000 status: %08x\n", E1000_REG(E1000_STATUS));
assert(E1000_REG(E1000_STATUS) == 0x80080783);
return 0;
}
发送
Allocate a region of memory for the transmit descriptor list. Software should insure this memory is aligned on a paragraph (16-byte) boundary.
Program the Transmit Descriptor Base Address (TDBAL/TDBAH) register(s) with the address of the region. TDBAL is used for 32-bit addresses and both TDBAL and TDBAH are used for 64-bit addresses.
Set the Transmit Descriptor Length (TDLEN) register to the size (in bytes) of the descriptor ring. This register must be 128-byte aligned.
The Transmit Descriptor Head and Tail (TDH/TDT) registers are initialized (by hardware) to 0b after a power-on or a software initiated Ethernet controller reset. Software should write 0b to both these registers to ensure this.
Initialize the Transmit Control Register (TCTL) for desired operation to include the following:
- Set the Enable (TCTL.EN) bit to 1b for normal operation.
- Set the Pad Short Packets (TCTL.PSP) bit to 1b.
- Configure the Collision Threshold (TCTL.CT) to the desired value. Ethernet standard is 10h. This setting only has meaning in half duplex mode.
- Configure the Collision Distance (TCTL.COLD) to its expected value. For full duplex
operation, this value should be set to 40h. For gigabit half duplex, this value should be set to 200h. For 10/100 half duplex, this value should be set to 40h.Program the Transmit IPG (TIPG) register with the following decimal values to get the minimum legal Inter Packet Gap:
.... section 13.4.34
根据手册进行发送初始化
#define E1000_TIPG_IPGT 0x000003FF
#define E1000_TIPG_IPGR1 0x000FFC00
#define E1000_TIPG_IPGR2 0x3FF00000
#define MASK_SHIFT(MASK, VALUE) ((VALUE) * ((MASK) & (~(MASK) + 1)))
#define MAX_TX_DESC 32
#define MAX_TX_BUFFER_SIZE 1518
struct e1000_tx_desc tx_descs[MAX_TX_DESC];
char tx_bufs[MAX_TX_DESC][MAX_TX_BUFFER_SIZE];
static void
e1000_transmit_init() {
for (size_t i = 0; i < MAX_TX_DESC; i++) {
tx_descs[i].buffer_addr = PADDR(tx_bufs[i]);
tx_descs[i].lower.flags.cmd = 0;
tx_descs[i].upper.fields.status |= E1000_TXD_STAT_DD;
}
E1000_REG(E1000_TDBAL) = PADDR((void *)tx_descs);
E1000_REG(E1000_TDBAH) = 0;
E1000_REG(E1000_TDLEN) = MAX_TX_DESC;
E1000_REG(E1000_TDH) = 0;
E1000_REG(E1000_TDT) = 0;
E1000_REG(E1000_TCTL) = E1000_TCTL_EN | E1000_TCTL_PSP |
MASK_SHIFT(E1000_TCTL_CT, 0x10) |
MASK_SHIFT(E1000_TCTL_COLD, 0x40);
E1000_REG(E1000_TIPG) = MASK_SHIFT(E1000_TIPG_IPGT, 10) |
MASK_SHIFT(E1000_TIPG_IPGR1, 4) |
MASK_SHIFT(E1000_TIPG_IPGR2, 6);
}
sizeof(struct e1000_tx_desc) = 16所以tx_descs已经自然地 16 字节对齐了;- 处理器只有 32 位,所以高 32 位地址 TDBAH 为 0;
- TDLEN 要求 128 位对齐,结构体为 16 位,所以
MAX_TX_DESC为 8 的倍数; MASK_SHIFT()首先获得MASK的最低为 1 的位,乘上VALUE则进行偏移到MASK笼罩的位置;
然后再添加到初始化函数中。
发送函数
int
e1000_transmit(void *buf, size_t len)
{
if (len > MAX_TX_BUFFER_SIZE) len = MAX_TX_BUFFER_SIZE;
uint32_t tdt = *tdt_p;
if (!(tx_descs[tdt].upper.fields.status & E1000_TXD_STAT_DD)) return -1;
memcpy(tx_bufs[tdt], buf, len);
tx_descs[tdt].lower.data = E1000_TXD_CMD_RS | E1000_TXD_CMD_EOP;
tx_descs[tdt].lower.flags.length = len;
tx_descs[tdt].upper.fields.status = 0;
*tdt_p = (tdt + 1) % MAX_TX_DESC;
return len;
}
写好发送函数之后,可以在内核中调用这个函数(比如在 e1000_attach() 里面初始化 E1000 后),然后令 QEMU 观察 E1000 并打印出一些结果,make E1000_DEBUG=TXERR,TX qemu。
在我这里打印出了
e1000: tx disabled
e1000: index 0: 0x2f2220 : 9000064 0
e1000: index 1: 0x2f280e : 9000064 0
e1000: index 2: 0x2f2dfc : 9000064 0
添加系统调用,再添加转发(kern/ 中的和 lib/ 中都要转发,头文件也要写好)。
static int
sys_ethernet_transmit(void *buf, size_t len) {
return e1000_transmit(buf, len);
}
完善 output(),union Nsipc nsipcbuf 背后的原理和文件系统是类似的,并且分配物理空间时通过aligned(PGSIZE) 进行了页对齐,不用怕物理空间不连续 。
void
output(envid_t ns_envid)
{
binaryname = "ns_output";
envid_t whom;
int32_t value;
int perm;
while (1) {
value = ipc_recv(&whom, &nsipcbuf, &perm);
if (value < 0) panic("output: ipc_recv (%e)", value);
if (value != NSREQ_OUTPUT || whom != ns_envid) continue;
size_t n = nsipcbuf.pkt.jp_len;
char *buf = nsipcbuf.pkt.jp_data;
while (n) {
size_t c = MIN(n, MAX_TX_BUFFER_SIZE);
while (sys_ethernet_transmit(buf, c) < 0) sys_yield();
n -= c;
buf += c;
}
}
}
接收
- Program the Receive Address Register(s) (RAL/RAH) with the desired Ethernet addresses.
RAL[0]/RAH[0] should always be used to store the Individual Ethernet MAC address of the
Ethernet controller. This can come from the EEPROM or from any other means (for example, on some machines, this comes from the system PROM not the EEPROM on the adapter port).- Initialize the MTA (Multicast Table Array) to 0b. Per software, entries can be added to this table as desired.
- Program the Interrupt Mask Set/Read (IMS) register to enable any interrupt the software driver wants to be notified of when the event occurs. Suggested bits include RXT, RXO, RXDMT, RXSEQ, and LSC. There is no immediate reason to enable the transmit interrupts. If software uses the Receive Descriptor Minimum Threshold Interrupt, the Receive Delay Timer (RDTR) register should be initialized with the desired delay time
- Allocate a region of memory for the receive descriptor list. Software should insure this memory is aligned on a paragraph (16-byte) boundary. Program the Receive Descriptor Base Address
- (RDBAL/RDBAH) register(s) with the address of the region. RDBAL is used for 32-bit addresses and both RDBAL and RDBAH are used for 64-bit addresses.
- Set the Receive Descriptor Length (RDLEN) register to the size (in bytes) of the descriptor ring. This register must be 128-byte aligned.
- The Receive Descriptor Head and Tail registers are initialized (by hardware) to 0b after a power-on or a software-initiated Ethernet controller reset. Receive buffers of appropriate size should be allocated and pointers to these buffers should be stored in the receive descriptor ring. Software initializes the Receive Descriptor Head (RDH) register and Receive Descriptor Tail (RDT) with the appropriate head and tail addresses. Head should point to the first valid receive descriptor in the descriptor ring and tail should point to one descriptor beyond the last valid descriptor in the descriptor ring.
- Program the Receive Control (RCTL) register with appropriate values for desired operation to
include the following:
- Set the receiver Enable (RCTL.EN) bit to 1b for normal operation. However, it is best to leave the Ethernet controller receive logic disabled (RCTL.EN = 0b) until after the receive
descriptor ring has been initialized and software is ready to process received packets.- Set the Long Packet Enable (RCTL.LPE) bit to 1b when processing packets greater than the standard Ethernet packet size. For example, this bit would be set to 1b when processing Jumbo Frames.
- Loopback Mode (RCTL.LBM) should be set to 00b for normal operation.
- Configure the Receive Descriptor Minimum Threshold Size (RCTL.RDMTS) bits to the
desired value.- Configure the Multicast Offset (RCTL.MO) bits to the desired value.
- Set the Broadcast Accept Mode (RCTL.BAM) bit to 1b allowing the hardware to accept
broadcast packets.- Configure the Receive Buffer Size (RCTL.BSIZE) bits to reflect the size of the receive buffers software provides to hardware. Also configure the Buffer Extension Size (RCTL.BSEX) bits if receive buffer needs to be larger than 2048 bytes.
- Set the Strip Ethernet CRC (RCTL.SECRC) bit if the desire is for hardware to strip the CRC prior to DMA-ing the receive packet to host memory.
- For the 82541xx and 82547GI/EI , program the Interrupt Mask Set/Read (IMS) register to
enable any interrupt the driver wants to be notified of when the even occurs. Suggested bits include RXT, RXO, RXDMT, RXSEQ, and LSC. There is no immediate reason to enable the transmit interrupts. Plan to optimize interrupts later, including programming the interrupt moderation registers TIDV, TADV, RADV and IDTR.- For the 82541xx and 82547GI/EI , if software uses the Receive Descriptor Minimum
Threshold Interrupt, the Receive Delay Timer (RDTR) register should be initialized with the
desired delay time.
和发送一节类似。
#define MAX_RX_DESC 128
#define MAX_RX_BUFFER_SIZE 1518
#define MAC_ADDR_LO 0x12005452
#define MAC_ADDR_HI 0x5634
static void
e1000_receive_init()
{
for (int i = 0; i < MAX_RX_DESC; i++) {
rx_descs[i].buffer_addr = PADDR(rx_bufs[i]);
rx_descs[i].status = 0;
rx_descs[i].length = MAX_RX_BUFFER_SIZE;
}
E1000_REG(E1000_RA) = MAC_ADDR_LO;
E1000_REG(E1000_RA + 4) = MAC_ADDR_HI | E1000_RAH_AV;
memset((void *)&E1000_REG(E1000_MTA), 0, E1000_RA - E1000_MTA);
E1000_REG(E1000_RDBAL) = PADDR((void *)rx_descs);
E1000_REG(E1000_RDBAH) = 0;
E1000_REG(E1000_RDLEN) = sizeof(rx_descs);
rdh_p = &E1000_REG(E1000_RDH);
rdt_p = &E1000_REG(E1000_RDT);
*rdh_p = 0;
*rdt_p = MAX_RX_DESC - 1;
E1000_REG(E1000_RCTL) = E1000_RCTL_EN | E1000_RCTL_LBM_NO |
E1000_RCTL_RDMTS_EIGTH | E1000_RCTL_MO_0 |
E1000_RCTL_BAM | E1000_RCTL_SZ_1024 |
E1000_RCTL_SECRC;
}
int
e1000_receive(void *buf, size_t len) {
uint32_t rdt = (*rdt_p + 1) % MAX_RX_DESC;
if (!(rx_descs[rdt].status & E1000_RXD_STAT_DD)) return -1;
len = MIN(len, rx_descs[rdt].length);
memcpy(buf, KADDR(rx_descs[rdt].buffer_addr), len);
rx_descs[rdt].status = 0;
rx_descs[rdt].length = MAX_RX_BUFFER_SIZE;
*rdt_p = rdt;
return len;
}
实现 input() 时,要注意给 nsipcbuf 分配空间。output() 中不需要是因为 output() 发送数据时,由请求发送的进程和网络进程建立共享空间时,共享的那片空间已经是分配的了。但在 input() 需要自己建立空间,并与请求接受的进程建立共享。
void
input(envid_t ns_envid)
{
binaryname = "ns_input";
int r;
while(1) {
r = sys_page_alloc(0, &nsipcbuf, PTE_W | PTE_U | PTE_P);
if (r < 0) panic("input: sys_page_alloc failed (%e)", r);
void *buf = nsipcbuf.pkt.jp_data;
size_t n = PGSIZE - sizeof(nsipcbuf.pkt.jp_len);
while (r = sys_ethernet_receive(buf, n), r < 0) sys_yield();
nsipcbuf.pkt.jp_len = r;
ipc_send(ns_envid, NSREQ_INPUT, &nsipcbuf, PTE_P | PTE_U);
r = sys_page_unmap(0, &nsipcbuf);
if (r < 0) panic("input: sys_page_unmap failed (%e)", r);
}
}
Web 服务器
网络连接也可以视为一种特殊的文件,实现了以太网的收发之后。用户程序可以通过文件描述符这一简单的接口收发网络数据。
参考其他 send_*(),完善 Web 服务器。服务器接受客户端请求,从 req->url 指定的文件中读取数据并返回给客户端。
static int
send_file(struct http_request *req)
{
int r;
off_t file_size = -1;
int fd;
// open the requested url for reading
if (fd = open(req->url, O_RDONLY), fd < 0) {
send_error(req, 404);
return fd;
}
struct Stat stat;
r = fstat(fd, &stat);
if (r < 0 || stat.st_isdir) {
send_error(req, 404);
goto end;
}
file_size = stat.st_size;
if ((r = send_header(req, 200)) < 0)
goto end;
if ((r = send_size(req, file_size)) < 0)
goto end;
if ((r = send_content_type(req)) < 0)
goto end;
if ((r = send_header_fin(req)) < 0)
goto end;
r = send_data(req, fd);
end:
close(fd);
return r;
}
send_data() 将 fd 描述的文件,发送给 req->sock 代表的用户。
static int
send_data(struct http_request *req, int fd)
{
// LAB 6: Your code here.
char buf[256];
ssize_t n;
ssize_t data_size;
while ((n = read(fd, buf, sizeof(buf)))) {
do {
ssize_t c = write(req->sock, buf, n);
if (c < 0) return c;
n -= c;
} while (n);
data_size += n;
}
return data_size;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号