【深度学习入门向】使用简单的卷积神经网络对 CIFAR10 数据集进行分类
Shallow CNN
从最简单的卷积神经网络(CNN)开始。卷积神经网络是神经网络的一种(子集),其结构主要包括以卷积层、池化层为主的特征提取部分和全连接层为主的分类部分。
- 卷积层使用卷积核对输入进行卷积操作。卷积操作的目的是对图像进行扫描以找到最接近卷积核所代表的特征。其输出称为特征图。对于图像分类为二维卷积。
- 池化层降采样图像以降低计算量,以及获得一定的空间不变性。
你可以在这里找到本文的具体实现。
网络结构
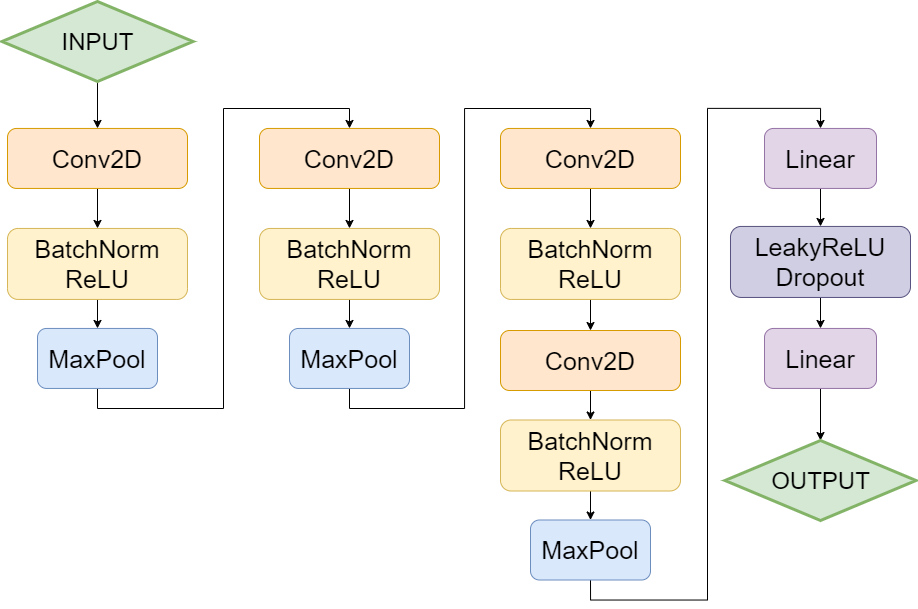
使用四层卷积层和两层全连接层。其中第一层卷积层使用 7x7x64 卷积核,后面的卷积层分别使用 3x3x128、3x3x256、3x3x256。全连接层将卷积层的提取的特征最终输出为 10 维向量,代表不同类别的置信度。
网络中没有使用 SoftMax 层是因为 PyTorch 的实现中,交叉熵损失函数会自带一个 SoftMax 函数。
激活函数
激活函数的加入是为了在计算中引入非线性成分。
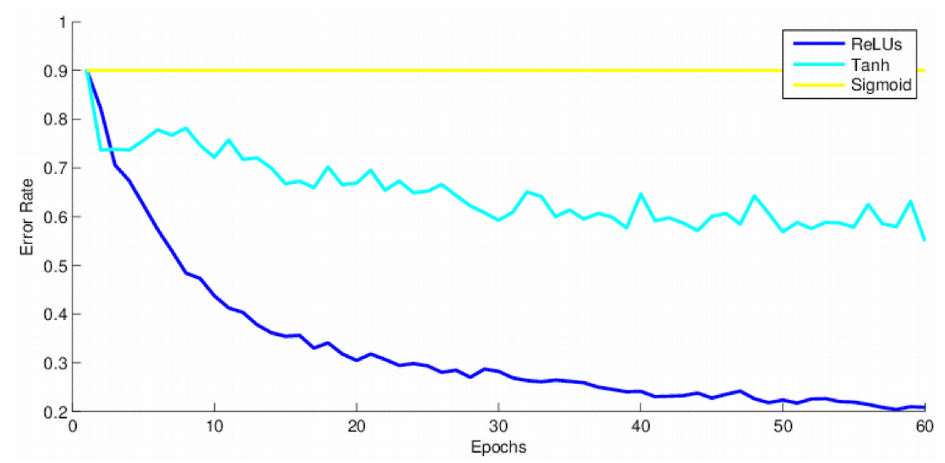
在卷积神经网络中,一般使用 ReLU 或其变体(Leaky ReLU、ELU、ReLU6 等)作为激活函数。大量的实验结果表明,随着神经网络层数的加深,ReLU 激活比其他类型的激活更有效。
模型复杂度
| 层 | 输入大小 | 输出大小 | 参数量 |
|---|---|---|---|
| 卷积层 | \(I\times I\times C\) | \(O\times O\times K\) | \((F\times F\times C+1)\times K\) |
| 池化层 | \(I\times I\times C\) | \(O\times O\times C\) | \(0\) |
| 全连接层 | \(N_{\rm in}\) | \(N_{\rm out}\) | \((N_{\rm in}+1)\times N_{\rm out}\) |
多出的 \(1\) 都是偏置(bias)。若 \(I\) 为输入尺寸(视为正方形),\(F\) 为卷积核尺寸,\(K\) 为卷积核数量,\(P\) 为填充(padding)大小,\(S\) 为步长(stride)大小,则输出尺寸为
池化层可以看作是一种特殊的卷积层,不过其卷积核是取最大值(最大池化)或平均值(平均池化),因此输出尺寸的计算也是相同的。
感受野指的是卷积核在原始输入图像上可以“看”到的大小 \(R_k\times R_k\),也就是说经过这个卷积核获得的输出 \(O\times O\) 中的每个点只和其原图上对应感受野内的部分有关。公式为
数据预处理
数据增强
简单数据增强(weak augmentation)、复杂数据增强(strong augmentation)和创造性增强(creative augmentation)
-
简单
RandomCrop()和RandomHorizontalFlip()随机裁剪和随机水平翻转,之所以称之为简单,是因为它们非常直观。
-
复杂的
AutoAugment(AutoAugmentPolicy.CIFAR10)运用强化学习的奖励驱动机制,使用 RNN 采用不同的增强子策略,在同一神经神经网络架构下训练 CIFAR10 后衡量不同策略的泛化能力。最终得到的一个复杂策略,包括不同的色彩调整和形状变换。具体变换种类可以看 PyTorch 的文档。
-
创造性
包括域随机化和使用 GAN 生成近似数据的原始分布的数据等。实际上已经不能算是数据增强了,在本文中不会使用。
经过测试发现复杂数据增强对于结果的提升比较轻微,但需要的更加复杂的调整,因此在实验中使用简单的数据增强。
预处理
考虑采用标准化(standardization)、全局对比度归一化(global contrast normalization)和 ZCA 白化的方式进行预处理。不过实际过程中只使用标准化就已经足够了。
-
标准化
\[\begin{align*} X'=(X-\text{mean})/\text{std} \end{align*} \]使数据均值为 0,方差为 1。实际上是归一化的一种。
-
归一化
\[\begin{align*} X'=s{X-\text{mean}\over\max\left(\epsilon,\sqrt{\lambda+\text{std}^2}\right)} \end{align*} \]其中 \(\epsilon,\lambda\) 为常数,防止标准差过小导致归一化波动太大。目的同样是消除数据量纲差异。
-
白化
学过主成分分析(PCA)后会很快理解,包括几个步骤:
- 主成分分析得到不相关的主成分;
- 对每个主成分标准化;
- 逆主成分分析,将标准化后的主成分组合为白化图像。
消除数据不同维的相关性,所以维方差为 1,即协方差矩阵为单位矩阵。
损失函数
使用带标签平滑(label-smoothing)的交叉熵损失(cross-entropy)。
首先将网络的 10 维输出向量 \(\mathbf z\) 用 SoftMax 进行归一化处理,得到模型预测图片属于第 \(i\) 类的似然 \(\hat p_i\)
计算目标概率 \(p_i\) 和预测似然 \(\hat p_i\) 之间的交叉熵
没有标签平滑时,如果图像 \(X\) 的类别为 \(y\) 则
从导数上看,分类正确的 \(z_i\) 不断增加,错误的 \(z_i\) 不断减小。
标签平滑会给每个类带来一定的缓冲空间(正则化)
其中 \(\varepsilon\) 为一个很小的值,\(K\) 是类别的数量,\(\alpha\) 为任意常量,对于 CIFAR10 来说为 10。从导数上看,分类正确的 \(z_i\) 不断增加,直到预测似然为 \(1-\varepsilon\),错误的 \(z_i\) 不断减小,直到预测似然为 \(\varepsilon/(K-1)\),也就是说 \(z_i\) 的值不会到达无穷,而是变为相应目标概率的对数加上一个偏置常数。
训练
使用 Tensor Board 查看训练过程中的准确率和损失变化。
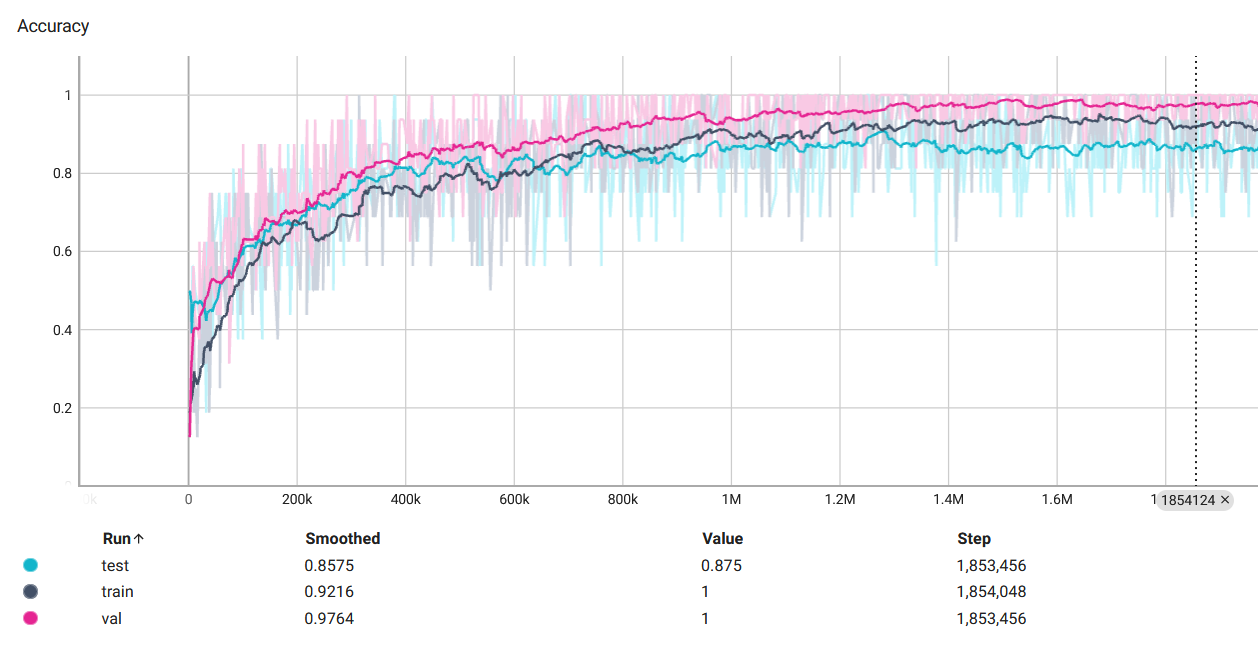
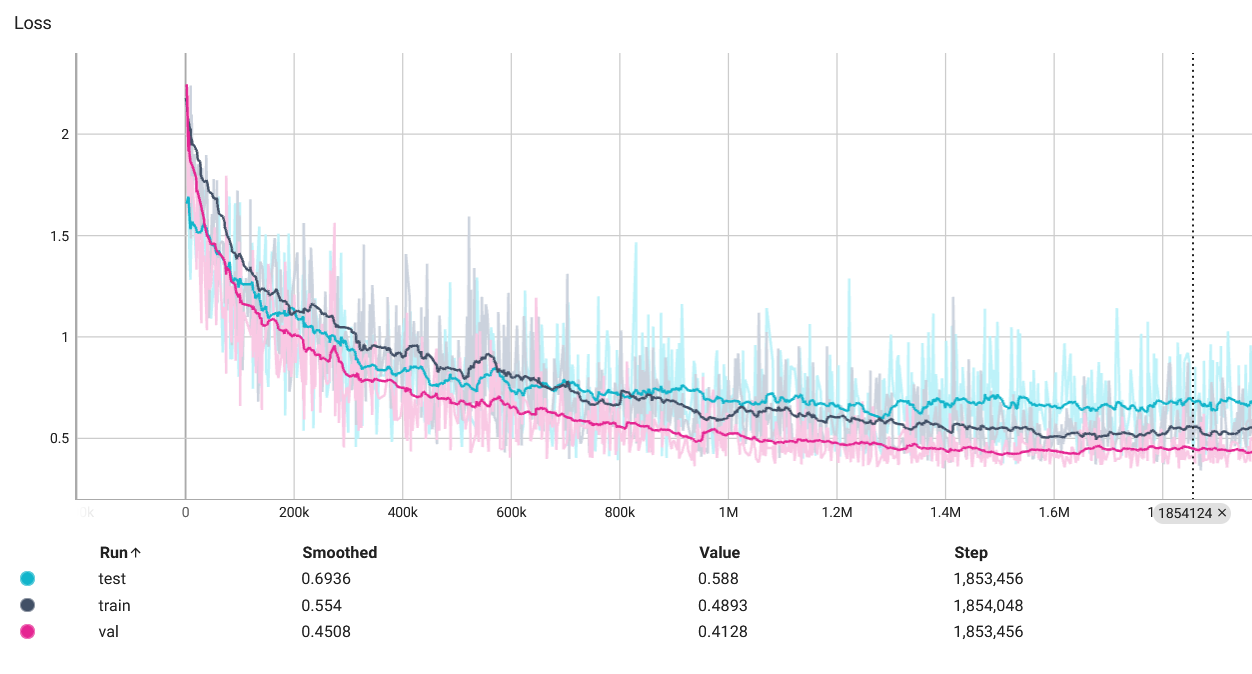
可视化
卷积层响应最大化
随机生成一张噪声图像,训练这张噪声图像的参数(也就是图像的值)经过网络后获得的响应最大。和训练相似而不同,训练网络时图像是数据,训练网络参数;而卷积响应最大化时网络参数固定,训练图像。
在训练时对结果做出限制(比如限制在 0,1 之间)只会导致结果被截断(比如低于 0 的和高于 1 的被截断在 0,1 内),导致不能获得纹理清晰的图像,甚至在部分区域形成一团。因此理论上图片的值可以任意变换(\(\in\mathbb R\)),所以很有可能遇到一个可以使响应到达无穷大的图像;在实际中则表现为损失溢出。所以在卷积层响应最大化的过程中,不能过度训练图像。
对 160 epoch 结果的最后一个卷积层的可视化如下。可以看出一些纹理,比如羽毛等,如果神经网络的层数加深,有可能可以看到更加清晰、具体地形状。

混淆矩阵
比较好理解,输出每个类别的预测正确及错误分类到其他类的数量。对 30 epoch 和 160 epoch 的结果获得的混淆矩阵如下。可以看到鸟猫鹿狗🐦🐈🦌🐕之间,尤其是猫和狗两个类混淆的情况比较严重,除此之外还有飞机和船✈🚢,手机和卡车📱🚚等。大体来说是对称的,这很符合直觉,因为混淆两个类就代表两者之间有某些相似之处。
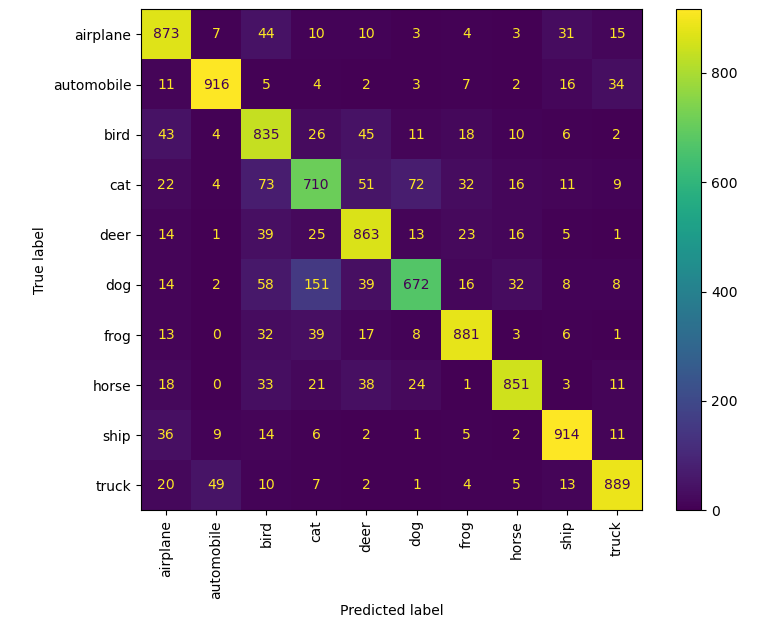
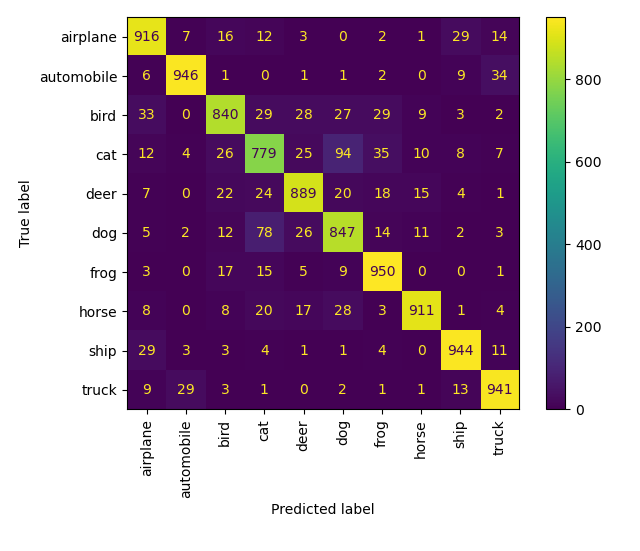
热度图
可以查看网络对原始图像的哪些部分最感兴趣(或者说,对结果影响最大)。本文不实现。
结果
最好的一次在测试集上达到了 89.63% 的准确率。
| model | 30 epoch loss | 30 epoch accuracy(%) | 160 epoch loss | 160 epoch accuracy(%) |
|---|---|---|---|---|
| Shallow-CNN | 0.6558 | 87.09 | 0.5982 | 89.63 |
在 Paper With Code 上查看 CIFAR10 的 benchmark,看看自己的记录。
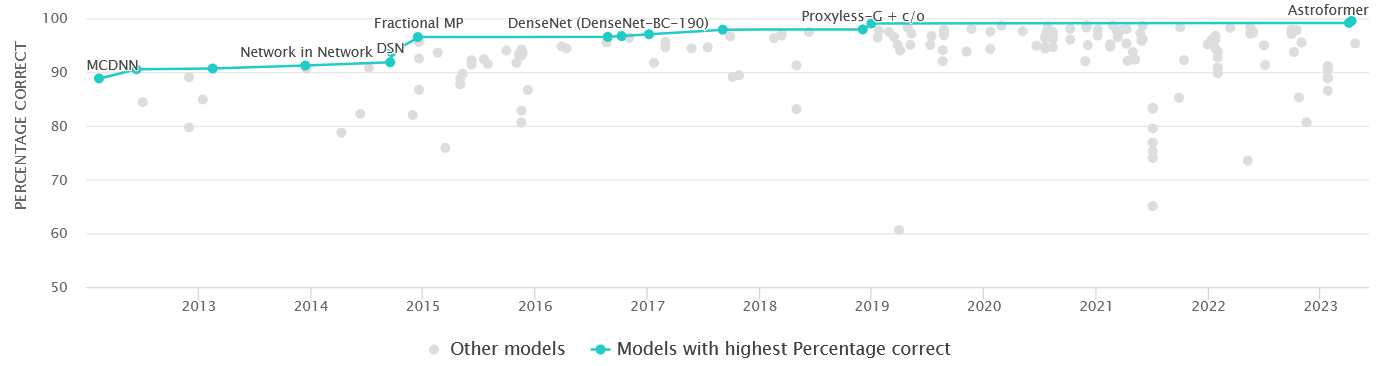
技巧和排错
原则
-
从简单的开始。
对于新手完全可以跳过数据预处理等部分,使用 CPU 而不是 GPU(因为使用 GPU 虽然会快很多,但也可能遇到一些问题),最好是从 PyTorch 的教程中复制黏贴几个代码来使用。不用考虑复杂的框架,比如 PyTorch-Lightning。
-
慢慢地调整训练。
一次只修改一种成分,一次只加入一种新东西。
-
耐心。
-
如果有必要,固定随机种子。
预处理
-
在数据传入网络之前进行一次可视化。
只是让你知道到底往网络中输入了什么。
网络
-
尝试过拟合一个小的数据集来验证模型的能力。
-
初始化。
好的初始化可以使网络更快地收敛,对最终结果可能也有一些影响。
训练过程
-
先使用大的 batch size 训练,再使用小的 batch size 慢慢抹平损失。
Batch Norm 层会从数据中学习均值和标准差(在论文中分别为 \(\beta,\gamma\)),使用大的 batch size 可以使输入的数据对整个数据更具有代表性。从大的 batch size 更换到小的 batch size 之后可以固定 Batch Norm 层的参数再训练。
-
正如其名,Adam 具有很多有有点,它适用于很多情况,收敛速度较快。而且对学习率(learning-rate)的设置更为宽容,这从 PyTorch 默认设置 Adam 的学习率为
1e-3就可以看出,使用默认的学习率往往就可以达到还过得去的效果。但是经过谨慎调整的 SGD 的效果会略微好于 Adam。你可以选择在训练的前几个 epoch 使用 Adam 而在后面的训练中手动调整 SGD。或者在测试新的模型、新的方法的时候使用 Adam 因为它可以使网络更快地收敛。
-
正则化
dropout、批标准化(batch normalization)、权重惩罚(weight regularization)、提前终止(early stopping)
其他
-
观察梯度
\[\begin{align*} {\mathrm df\over\mathrm dx}(x)=f'(x)\approx{f(x+h)-f(x-h)\over2h} \end{align*} \]约等于号左右两侧的梯度计算时应该很接近。
-
PyTorch 和 Numpy 的不同。
对于对 Numpy 已经有经验的人,要注意 PyTorch 和 Numpy 中各种函数的一些区别,比如
transpose()和permute()等等。以及两者之间的转换,对于使用 GPU 的人要更加注意detach().item().numpy()的使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号