
主成分分析 PCA
主成分分析
设原数据如下
主成分分析的目的是求出数据方差最大的方向,运用正交变换将由线性相关变量表示的观测数据转换为少数几个由线性无关变量表示的数据。
考虑一个线性变换 \(\pmb A=\begin{bmatrix}\pmb\alpha_1,\pmb\alpha_2,\dots,\pmb\alpha_m\end{bmatrix}^T\),它将 \(n\) 维原数据 \(\pmb x\) 映射到 \(m\) 维的 \(\pmb y\),如果其中 \(m<n\),则这是一个降维方法。
主成分分析要求这一变换 \(\pmb y=\pmb A\pmb x\) 具有如下性质:
- \(y^{(1)}\) 是 \(\pmb x\) 的线性变换中方差最大的,\(y^{(2)}\) 是 \(\pmb x\) 的与 \(y^{(1)}\) 线性无关的线性变换中方差最大的,以此类推。自然的,\(y^{(1)},y^{(2)},\dots,y^{(m)}\) 的方差依次下降,\(\operatorname{var}[y^{(1)}]\ge\operatorname{var}[y^{(2)}]\ge\dots\ge\operatorname{var}[y^{(m)}]\),说明每个维数的信息量逐渐下降。
- \(y^{(1)},y^{(2)},\dots,y^{(m)}\) 互不相关,即 \(i\ne j\implies\operatorname{cov}(y^{(i)},y^{(j)})=0\),\(\pmb A\pmb\Sigma\pmb A^T\) 为对角矩阵。这一点只需要保证 \(\pmb A\) 为正交矩阵即可,即 \(\pmb\alpha_i\) 为单位向量,且它们彼此正交,\(\pmb\alpha_i^T\pmb\alpha_j=\begin{cases}1&i=j\\0&i\ne j\end{cases},\pmb A\pmb A^T=\pmb I\),使这一变换是坐标轴变换,而不改变数据本身。
这三点与我们的目标一致,现在考虑需要怎样的 \(\pmb A\) 来获得最理想的 \(\pmb y\)。
计算方法
由主成分分析要求的性质,可以直接导出迭代的计算方法,也就是计算 \(\pmb\alpha_1,\ldots,\pmb\alpha_{n-1}\) 后计算 \(\pmb\alpha_n\):
-
去除 \(\pmb x\) 中与 \(\pmb\alpha_1,\ldots,\pmb\alpha_{i-1}\) 相关的分量
\[\begin{align*} \pmb x_i:=\pmb x-\sum_{j=1}^{i-1}{\pmb x^T\pmb\alpha_j\over\pmb\alpha_j^T\pmb\alpha_j}\pmb\alpha_j=\pmb x-\sum_{j=1}^{i-1}\pmb x^T\pmb\alpha_j\pmb\alpha_j \end{align*} \] -
求在约束 \(\pmb\alpha_i^T\pmb\alpha_i=1\) 下方差最大的 \(\pmb\alpha_i\pmb x_i\)
\[\begin{align*} &&\pmb\alpha_i&=\underset{\pmb\alpha_i}{\arg\max}\ \pmb\alpha_i^T\pmb\Sigma_i\pmb\alpha_i,\text{ where }\pmb\Sigma_i=\mathbb E\left[(\pmb x_i-\pmb\mu_i)(\pmb x_i-\pmb\mu_i)^T\right]\\ &&&\quad\ \,\text{s.t. }\pmb\alpha_i^T\pmb\alpha_i=1\\ \text{let}&&f&:=\pmb\alpha_i^T\pmb\Sigma_i\pmb\alpha_i-\lambda(\pmb\alpha_i^T\pmb\alpha_i-1)\\ &&f'&=\pmb\Sigma_i\pmb\alpha_i-\lambda\pmb\alpha_i=0\\ \end{align*} \]\(\lambda\) 为 \(\pmb\Sigma_i\) 的特征值,\(\pmb\alpha_i\) 为对应的特征向量,为了满足 \(\pmb\alpha_i=\underset{\pmb\alpha_i}{\arg\max}\ \pmb\alpha_i^T\pmb\Sigma_i\pmb\alpha_i\) 应当选择最大的特征值。
此时方差为 \(\pmb\alpha_i^T\pmb\Sigma_i\pmb\alpha_i=\lambda\),定为 \(\lambda_i\)。
事实上,\(\pmb\Sigma_i\) 的特征值是 \(\pmb\Sigma\) 的特征值,可以递归证明:已知 \(\pmb\alpha_1,\ldots,\pmb\alpha_{i-1}\) 为 \(\pmb\Sigma\) 的特征向量,求 \(\pmb\alpha_i\) 也是 \(\pmb\Sigma\) 的特征向量。
即 \(\pmb\alpha_i\) 也是 \(\pmb\Sigma\) 的特征向量,递归来看所有 \(\pmb\alpha_i\) 都为 \(\pmb\Sigma\) 的特征向量,\(\lambda_i\) 都为 \(\pmb\Sigma\) 的特征值,且降序排列。
求出 \(\pmb\Sigma\) 的特征值和特征向量,排序后得到主成分。保留前 \(m\) 个主成分则得到 \(\pmb A\),\(\pmb A\pmb\Sigma\pmb A^T=\pmb\Lambda_m=\operatorname{diag}(\lambda_1,\ldots,\lambda_m)\)。
性质
考虑一个正交基 \(\pmb D\),选择合适的点在新正交基中表示原数据,也就是使 \(\pmb y\) 尽量无损的还原回 \(\pmb x\),用 \(L2\) 范数来衡量这一差异
说明使用新正交基的转置对原数据进行转换可以最大限度地保留数据,这个损失也可以计算出来。
如果计算损失时不考虑均值、期望,则结果为剩余维的方差
样本主成分分析
样本为 \(\pmb X=[\pmb x_1,\pmb x_2,\ldots,\pmb x_p]\in\mathbb R^{n\times p}\),有 \(p\) 个样本,每个样本 \(n\) 维。均值矩阵为每个维度上的均值,协方差为数据不同维度之间的协方差,相关系数为数据不同维度之间的协方差
因为数据从变量变为了样本,因此 \(\bar{\pmb x}\) 是对 \(\pmb\mu\) 的估计,\(\pmb S\) 是对 \(\pmb\Sigma\) 的估计。
同样有一个变换矩阵 \(\pmb A=\begin{bmatrix}\pmb\alpha_1,\pmb\alpha_2,\dots,\pmb\alpha_m\end{bmatrix}^T\) 和变换后的数据 \(\pmb Y=\pmb A\pmb X,\pmb y_i=\pmb A\pmb x_i\)。主要关注每个维度方差和协方差。
和变量的主成分分析相同,要求 \(\pmb y^{(1)},\pmb y^{(2)},\dots,\pmb y^{(n)}\) 互不相关,依次取方差最大的变换。
从形式上看,样本主成分分析得到的矩阵并没有什么不同(因为从变量到样本只需要多次测量,从样本到变量则需要进行无偏估计),因此采用同样的方法计算即可。
经过变换后的数据的 \(\pmb Y\) 具有的特点是:每个数据的信息量(方差)沿着维度递减。如果选择前 \(m\) 个维度,那么就达成了数据的降维,实际上是在尝试使用低维点代表高位点。
同样计算损失,实际上结果只是多个样本的叠加,
使用奇异分解
如果数据的均值为 0,数据的协方差矩阵就等于 \(\pmb S=\frac1{n-1}\pmb X^T\pmb X\)。
主成分变换矩阵通过计算 \(\pmb X\) 的奇异分量矩阵 \(\pmb V\) 得到。方差为奇异值的平方根除以 \(n-1\) 得到。
应用
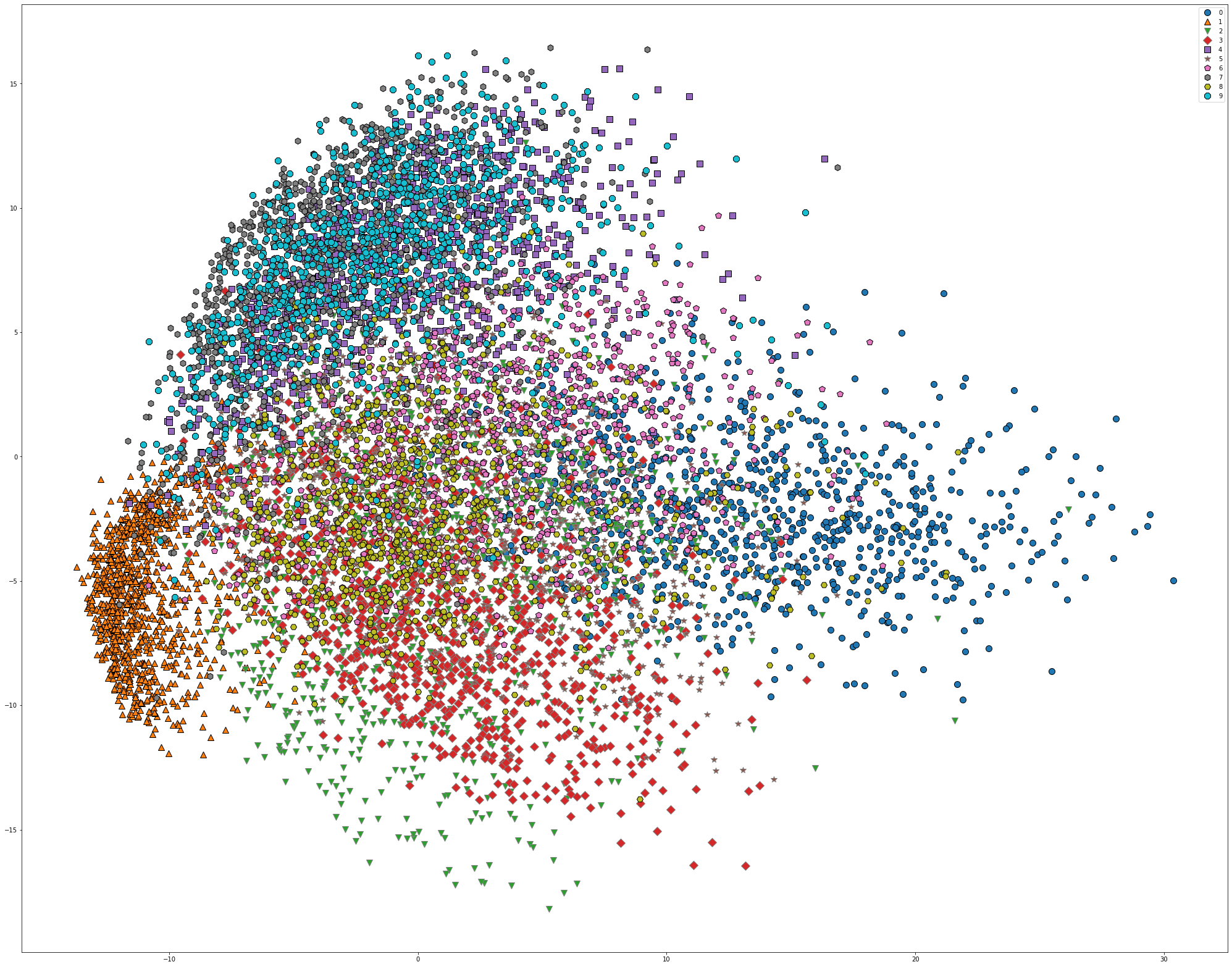
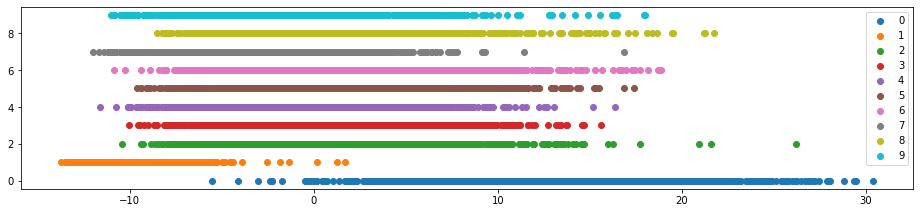
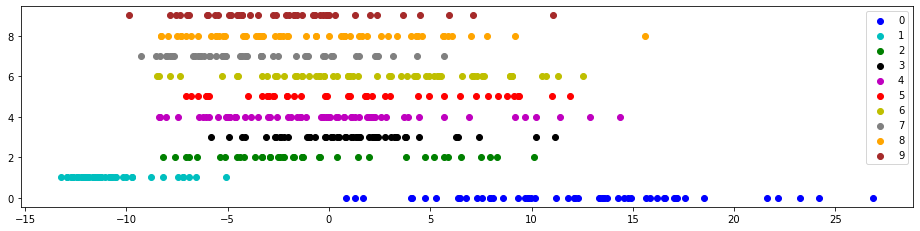
对 MNIST 数据集应用 PCA,分别降维到二维和一维。
使用 torch 导入 MNIST 数据集,用 sklearn 库的 PCA 函数,mglearn.discrete_scatter() 函数对于画离散数据比较方便。
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torchvision import models
import sklearn
from sklearn.decomposition import PCA
import mglearn
import numpy as np
import matplotlib.pyplot as plt
准备好数据集,进行标准化
training_data = datasets.MNIST(root='mnist', train=True, download=True, transform=None)
test_data = datasets.MNIST(root='mnist', train=False, download=True, transform=None)
data = training_data.data / 255
mean = torch.mean(data)
std = torch.std(data)
train_X = transforms.Normalize(mean=mean, std=std)(data).numpy().reshape(60000, -1)
train_y = training_data.targets.numpy()
test_X = transforms.Normalize(mean=mean, std=std)(data).numpy().reshape(10000, -1)
test_y = test_data.targets.numpy()
应用 PCA 并显示
pca = PCA(n_components=2)
pca.fit(train_X)
pca_data = pca.transform(test_X)
plt.figure(figsize=(22, 22))
mglearn.discrete_scatter(pca_data[:, 0], pca_data[:, 1], test_y)
plt.legend(list(map(str, range(10))), loc='best')
plt.gca().set_aspect('equal')
plt.xlabel('first component')
plt.ylabel('second component')
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号