
Linux 文件
Linux中一切皆为文件
文件
文件是具有名字的一组相关信息的有序集合,存放在外部存储器中。
文件系统
文件系统是操作系统的一个重要组成部分,它负责管理系统中的文件,为用户提供使用文件的操作接口。
文件系统由实施文件管理的软件和被管理的文件组成。文件系统软件属于系统内核代码,文件则按特定的格式存放在磁盘分区中。
文件系统的功能
- 提供文件访问接口,实现文件的“按名存取”。
- 实施对文件的操作,包括建立、读写、检索、修改、删除文等。
- 管理文件分区的存储空间,实施存储空间的分配、回收与重组。
- 实现对文件的共享、保密和保护措施。
文件的结构

文件的逻辑结构是文件系统的直接用户(也就是应用程序)所看到的文件结构。文件的逻辑结构取决于文件系统接口的设计,它决定了文件存取的方式。
现代流行的操作系统,如UNIX、Linux、Windows、OS/2等均采用流式文件作为文件的逻辑结构。
文件的物理结构又称为存储结构,是指文件在外存上的存储组织形式。
文件系统负责文件的逻辑结构与物理结构之间的映射。
文件的物理结构
文件的物理结构与存储设备的空间结构和寻址方式有关。
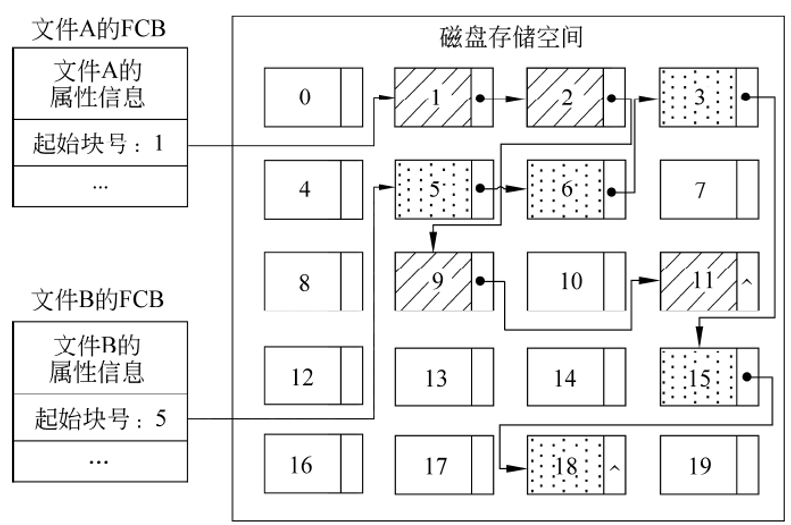
文件的物理结构主要有3种,即连续文件、链接文件和索引文件。
-
连续文件
将文件的内容按逻辑顺序存放在连续的存储块中。
优点是简单,存取速度快;
缺点是限制了文件的动态增长和磁盘碎片问题。

-
链接文件
文件内容可以存放在彼此不连续的存储块中,用指针拉链的方式表示文件内容的逻辑顺序。
优点是允许文件长度动态变化,外存空间利用率高;
缺点是存取效率(尤其是直接存取的效率)较连续文件低。
-
索引文件
允许将文件内容存放在不连续的存储块中,但它是用索引表来建立文件内容与存储块之间的联系的。
文件定位速度更快,顺序存取和随机存取效率都比较高;
缺点是占用的存储空间较多,因为索引表本身需占用一定的存储空间。

文件的共享与保护
文件共享是指允许一个文件被多个用户或进程共同使用。这样可以节省存储空间和传输时间,并可避免因存在多个文件副本而可能发生的内容不一致现象。
实现文件共享的方法是链接法。
文件保护的目的是防止文件被未授权的用户访问,造成泄密或意外的破坏。在开放的多用户系统环境下,文件保护尤为重要。
保护文件的主要手段是控制用户对文件的存取权限。
Linux文件系统的结构
Ext文件系统
Ext文件系统采用了改进的FCB结构来描述文件。
FCB主部包含除文件名之外的全部信息,称为索引节点(index node),简称为i节点。
次部只包含文件名和主部的标识号(即i节点号)。
文件目录由各文件的FCB次部组成,主要实现按名检索的目的。由于目录项(即FCB次部)很小,目录文件也就很小,按文件名检索文件的速度就会很快。
Ext目录项(dirent)主要包括文件名和索引节点号两部分。索引节点号用于指示索引节点的存放位置,文件名用于文件检索。Ext文件系统支持最长255个字符的长文件名。




文件的链接
-
符号链接(symbolic link)也称为软链接。
符号链接文件是一种特殊的文件,其存放的内容是另一个文件的路径名。
优点是灵活,能够实现跨越文件系统的链接以及目录链接。
缺点是空间开销较大,因为每个符号链接都要建立一个新的文件。此外,通过链接文件访问目标文件时需要执行两次文件访问,这无疑降低了文件存取操作的速度。
-
硬链接(hard link)
将两个或多个文件通过 i 节点物理地链接在一起。硬链接的文件具有不同的文件路径名和同一个 i 节点,通过其中任何一个路径名访问得到的都是同一内容,这就如同一个文件具有多个别名。
优点是节省空间且访问效率高。
缺点是受文件系统范围的限制,也不能对目录进行链接操作。
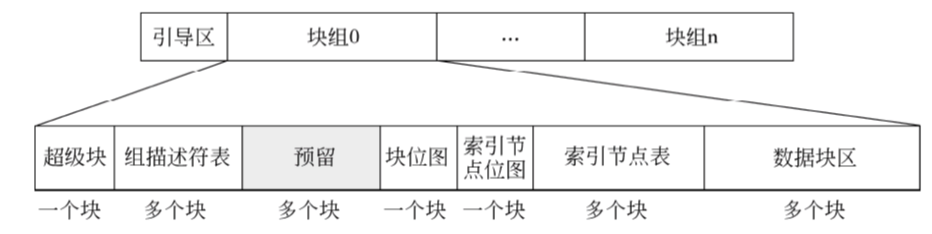
Ext3文件系统的布局
Ext3文件系统在格式化时把磁盘分区分为一个引导区和若干个块组。所有块组的大小相同(最后一组可能不足),顺序排列。
-
超级块(super block)
每个Ext3的磁盘分区
用于记录整个文件系统的全局配置参数和管理信息,如文件系统标识、数据块大小、块组大小、总的块数和 i 节点数、空闲的块数和 i 节点数等。这些都是文件系统挂装、检查、分配、检索等操作的基本参数,是文件系统中最基本、最重要的数据。若超级块损坏,则整个分区的文件系统不再可用
-
组描述符(group descriptor)
每个块组
用于记录该块组的使用信息,包括块组中的块位图、索引节点位图和索引节点表的位置、块组中空闲索引节点和空闲块的数目以及目录的个数等,长度为32位。
所有块组的组描述符集中在一起就形成了组描述符表(Group Descriptor Table,GDT),它是文件系统管理各块组的依据。
通常情况下,文件系统只使用块组 0 中的超级块和GDT,其他块组中的超级块和GDT则作为冗余备份,在系统崩溃时用来恢复文件系统。
-
位图
管理i节点和数据块的分配。用于记录数据块的分配情况的位图称为块位图(block bitmap);用于记录i节点的分配情况的位图称为“索引节点位图”(inode bitmap)。
-
索引节点表和数据块区
索引节点表和数据块区是真正用于存放文件的区域。块组中所有可用的i节点都集中存放在一起,形成索引节点表(inodetable)。索引节点表要占用多个连续的存储块。块组中的每个文件都在此表中占有一个i节点。
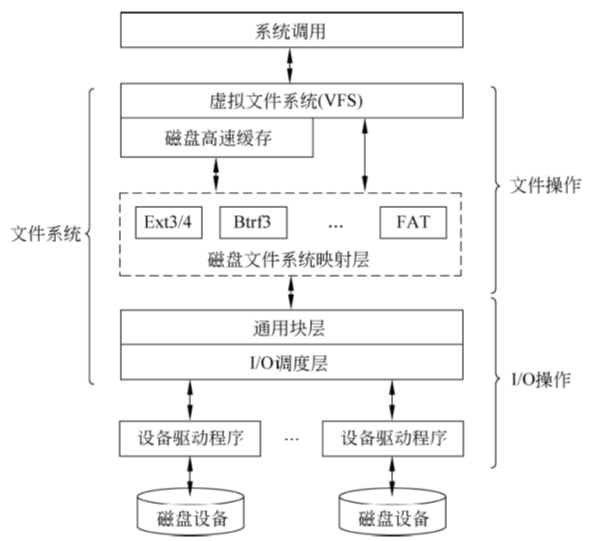
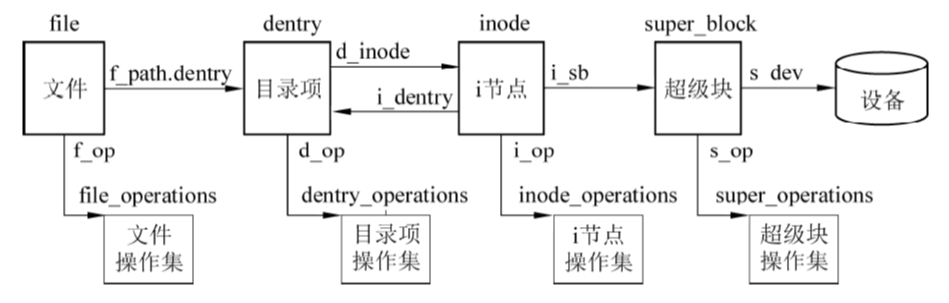
虚拟文件系统
虚拟文件系统(VFS)位于整个文件系统的最上层。它为用户进程及内核其他模块提供了使用文件系统的统一接口。
引入虚拟文件系统的目的是为了屏蔽各种实际文件系统的差异。它对实际文件系统进行抽象,采用统一的数据结构在内存中描述所有的文件,并向用户提供了一组标准函数来操作文件。
虚拟文件系统必须和某个或某些实际的文件系统一起才能实现完整的文件系统功能。
VFS的对象
-
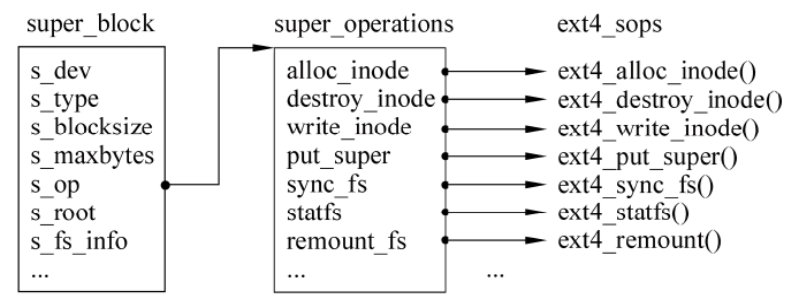
VFS超级块(super block),代表一个已挂装的文件系统。
与实际文件系统的超级块相对应,包含了操作该文件系统的所有信息。VFS超级块的描述符是super_block。
-
VFS目录项(dentry),代表文件路径中的一个分量。
当VFS首次解析一个路径名时,它依次读取路径中的每个目录或文件,逐一为它们建立相应的dentry结构,并将其与该文件或目录的inode关联起来。

- VFS索引节点(inode),代表一个实际的文件。
与实际文件系统中的 i 节点相对应,包含了操作文件所需的全部信息。VFS索引节点的描述符是inode。
系统中每个打开的文件都对应一个inode。在文件被打开时,VFS读入该文件的磁盘i节点的信息,为它在内存建立一个inode。文件关闭后它的inode也被撤销。与超级块相同,inode也存在同步更新的问题。所以,VFS也会周期性地将所有发生改变的inode写回磁盘。

-
VFS文件(file),代表进程打开的一个文件。
VFS用file对象来描述一个进程所关心的文件。每当进程打开一个文件时,VFS 都将为它建立一个file描述符。
file对象在最初打开该文件时建立,在最后关闭该文件时消失。

对于不同的文件系统(Ext、Btrs、FAT等)以及不同的文件类型(普通文件、目录文件、设备文件等),无论它们的数据格式和操作函数有什么差别,在VFS对象层面上的接口都是一致的,这正是VFS 实现标准接口功能的关键。
VFS文件与进程的接口

VFS文件与缓存的接口
为了提高文件的查找和读写效率,VFS使用了磁盘高速缓存(diskcache)机制。磁盘高速缓存将那些通常应放在磁盘上的数据保留在内存中,以便下次访问它们时能快速地获得,而不必再访问磁盘。
VFS使用的磁盘高速缓存主要是用于缓存文件内容的页面缓存,此外还有用于缓存dentry和 inode对象的目录项缓存。
文件操作
文件的打开与关闭
打开文件的系统调用是 open(),它带的参数有文件路径名和打开模式等。
打开文件的实质就是在内存中构建起该文件的VFS对象,建立它们之间的关系及与进程的连接,并用文件描述符来标识这个连接。根据文件的不同存在状态,打开文件的操作也有所不同。
-
打开一个已有文件的操作是:
- 获得一个可用的文件描述符,也就是在进程的
files_struct结构中找到一个空闲的文件描述符项fd_array[i]; - 创建一个
file对象; - 根据文件路径名查找到该文件的
dentry; - 查找或创建该文件的
inode; 将inode.i_fop赋给file.f_op, inode.i_mapping赋给file.f_mapping;调用file.f_op->open(),执行实际文件系统的打开操作;将file对象的指针填入fd_array[i],返回 i 作为文件描述符。
- 获得一个可用的文件描述符,也就是在进程的
-
打开一个不存在的文件且打开模式是“创建”(
O_CREAT)的话,则首先要找到文件所在目录的dentry,再得到它的inode,然后执行inode.i_op->create(),调用实际文件系统的创建函数,完成文件的创建操作(包括建立文件的磁盘i节点和目录项)。创建完成后再执行后续的文件打开操作。 -
关闭一个文件的系统调用是
close(),参数是文件描述符fd。关闭文件的主要工作是断开进程与该文件的VFS对象之间的连接。具体的动作是:将file.f_count减1;如果f_count为0就调用file.f_op->release(),实际地关闭文件,并释放file对象;最后释放文件的fd。
文件的读与写
读写文件的系统调用是 read() 和 write()。它们带有3个参数:文件描述符 fd、内存区地址 buf 以及要传送的字节数 count。文件在读写前必须是已经打开的,系统通过fdl参数的值在进程的 files_struct 结构中检索 fd_array[] 数组,得到文件的 file对象,根据 file.f_mode 检查文件的访问权限,然后执行 file.f_op->read() 或 file.f_op--write(),完成文件的读写。读写操作的起始位置是当前文件位置 file.f_pos。文件打开之初,f_pos 的值为0。读写操作结束后 f_pos 会相应地更新。读写操作前可以先用 lseek() 设置 f_pos 的值。
-
读文件的操作过程是:
首先通过
file.f_mapping找到文件的地址空间对象address_space,确定要读的页;然后调用页面搜索函数find_get_page()在页面缓存中查找。如果查找命中就直接从缓存读出数据,传送到用户进程的 buf 中,否则就调用地址空间操作集a_ops中的readpage()函数,触发一次真正的读盘操作。待数据读入页面缓存后,再从页面缓存复制到用户进程的 buf 中。 -
写文件的过程与读文件类似:
通过
address_ space确定要写的页,然后调用地址空间操作集a_ops中的write_ begin()函数, 将数据从用户的buf写到缓存页中,并在页面上设置“脏”标记,最后执行write_end()函 数返回。VFS会在适当的时候调用a_ops中的writepage(),触发一次真正的写盘操作, 将含有“脏”标记的页面写回磁盘。
需要说明的是,文件操作集f_op 中的 read() 和 write() 是同步读写函数,而 read_iter() 和 write_iter() 则是异步读写函数。
同步读写的特点是进程在等待读写操作完成时通常会被阻塞,因而效率低下。异步读写则默认不阻塞进程,进程会立即返回,执行下一个 read_iter()、write_iter() 系统调用或其他操作。当读写操作完成时内核会以信号或回调函数方式通知进程。这样就允许了重叠的文件IO操作,提高了文件读写效率。
现在的文件系统(如Ext3/Ext4 等)大都采用异步方式。因此,当调用 file.f_op->read() 或 file.f_op->write() 函数时,VFS 将默认地转去执行 file.f_op->read_iter() 或 file.f_op->write_iter(),以异步方式完成文件的读写操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号