交叉验证集相关
交叉验证相关
过拟合、欠拟合问题
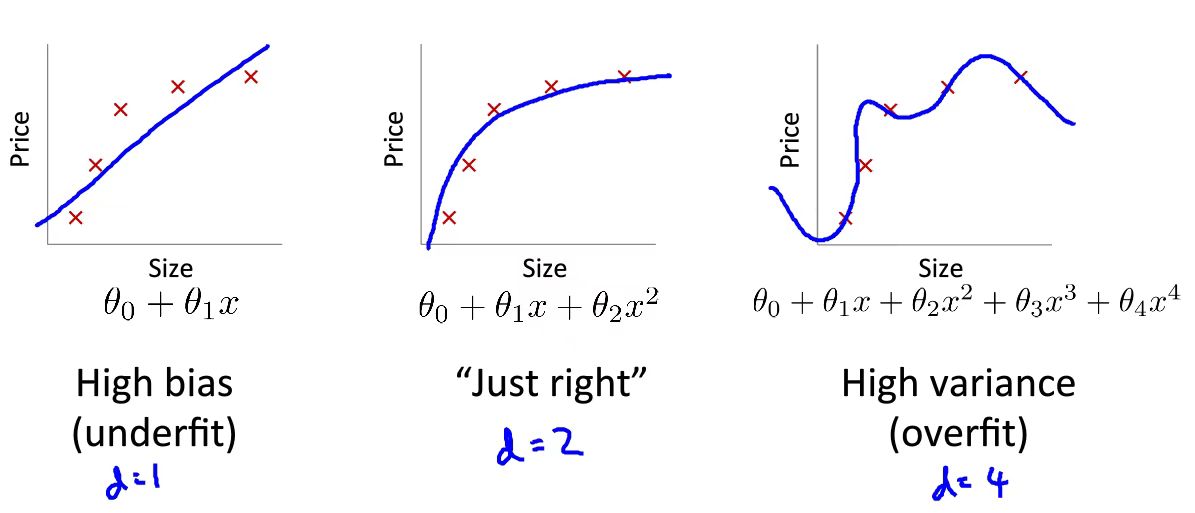
如图所示,在进行多项式次数选择时会发生相关问题。如果用一个较低次的多项式来拟合,那么就会造成损失函数\(J\)过大,会产生高偏差(high bias)问题。如果用一个高的多项式来拟合,那么就会造成损失函数\(J\)过小的问题,会产生高方差(high variance)问题。这意味着你虽然当前数据拟合的非常成功,但如果将模型去用于预测别的数据,那么会导致有较大出入。
我们利用正则化来解决过拟合问题(正则化见后面文章):改写代价函数\(J\)
我们将数据集分为训练集和测试集现在已经不足以很好的解决这个问题了

如上图所示,这并不是一种好办法。我们去通过增加\(d\)即多项式次数来得到相应参数,利用该参数去计算\(J_{test}\)(测试集代价函数),当然你一定有一个次数,它会使你的\(J_{test}\)最小,但是这样的话就会降低你模型的泛化能力。那么这样,引入测试集的意义就不存在了。举一个例子,好像是你学习为了取得好的成绩,但是你偷看了考试答案,这当然会使得你的本场考试成绩提升,但是并不代表你模型本身取得较好的学习能力。
这就引入了交叉验证集(cross validation set)。我们通过交叉验证集中的代价函数来验证模型是否拟合程度
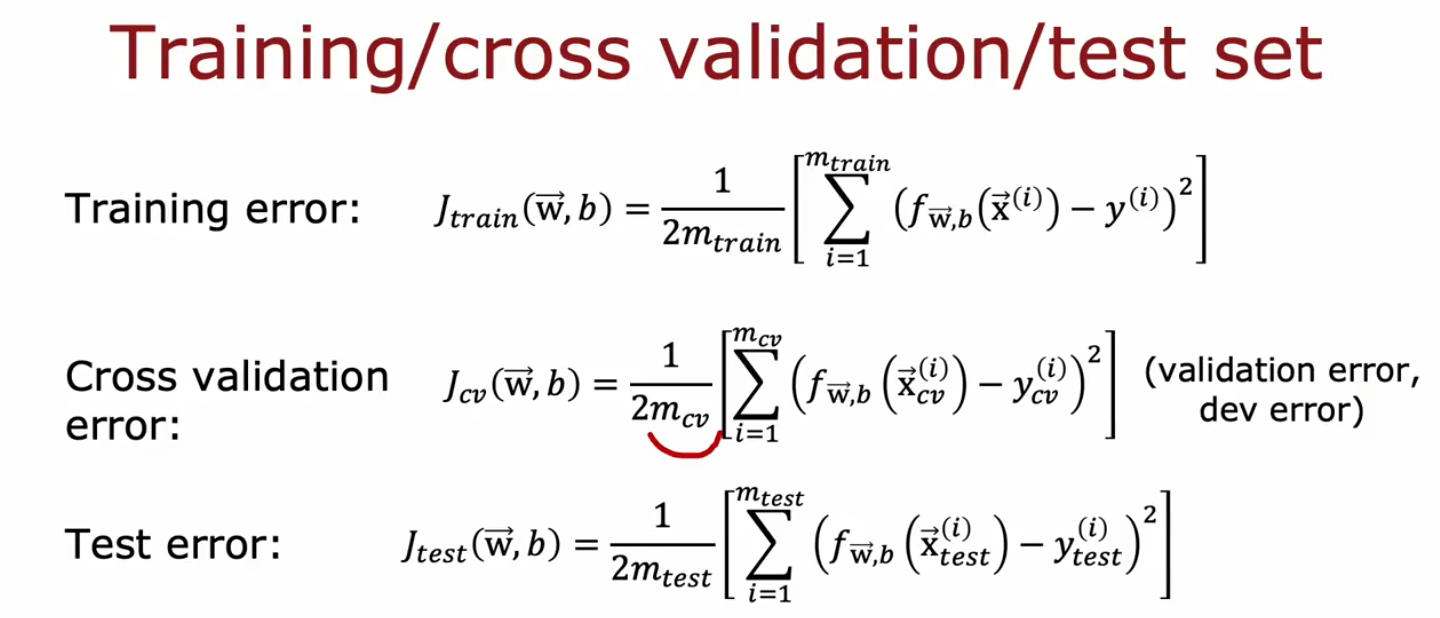
注意这里的代价函数均不含正则化项的。之前那个图中找到最小的\(J_{test}\)就变成了找到最小的\(J_{cv}\)来选择一个比较符合的多项式次数。

而测试集的代价函数则被用来展示泛化误差估计这个模型在新数据上的表现。
最后还有几个问题
关于交叉验证集和验证集:交叉验证集是因为训练集太小,无法直接分出训练集和验证集,采用交叉验证的方式如下图所示:

首先将数据集随机分为测试集和训练集,并且将训练集分为五份[S折交叉验证( S-Folder Cross Validation)]。每次都用其中4份来训练模型,粉红色的那份用来验证4份训练出来的模型的准确率,记下准确率。然后在这5份中取另外4份做训练集,1份做验证集,再次得到一个模型的准确率。直到所有5份都做过1次验证集,也即验证集名额循环了一圈,交叉验证的过程就结束。算得这5次准确率的均值。留下准确率最高的模型,即该模型的超参数是什么样的最终模型的超参数就是这个样的。
训练集主要是为了确定参数,而验证集是为了确定超参数。所谓参数就是模型可以根据数据可以自动学习出的变量,应该就是参数。比如,深度学习的权重,偏差等(非人为给定)超参数:就是用来确定模型的一些参数,超参数不同,模型是不同的(比如说:假设都是CNN模型,如果层数不同,模型不一样,虽然都是CNN模型。),超参数一般就是根据经验确定的变量。在深度学习中,超参数有:学习速率,迭代次数,层数,每层神经元的个数等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号