方法总比困难多,遇到问题,要找到问题的根源,不断地调试,不要放弃,一定会与解决的方法,程序是人写的,问题不可能没有办法解决,冷静的去分析,问题一定会解开的,加油!
# -*- coding: utf-8 -*-
import scrapy
import re
class AppannieSpider(scrapy.Spider):
name = 'appannie'
# allowed_domains = ['appannie.com']
start_urls = ['https://www.appannie.com/account/login/?_ref=header']
def parse(self, response):
BodyHtml = response.body.decode()
getToken = re.search(r"<input type='hidden' name='csrfmiddlewaretoken' value='(.*?)' />", BodyHtml)
Real_Token = getToken.group(1)
print(Real_Token)
yield scrapy.FormRequest(
url='https://www.appannie.com/account/login',
headers={
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
},
formdata={
'csrfmiddlewaretoken': Real_Token,
'next': '/dashboard/home/',
'username': '你的账号',
'password': '你的密码'
},
callback=self.after_login
)
def after_login(self, response):
url = 'https://www.appannie.com/ajax/top-chart/table/?market=google-play&country_code=US&category=1&date=2018-12-26&rank_sorting_type=rank&page_size=100&order_type=desc'
return scrapy.Request(url, headers={'X-Requested-With': 'XMLHttpRequest','User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',}, callback=self.get_content)
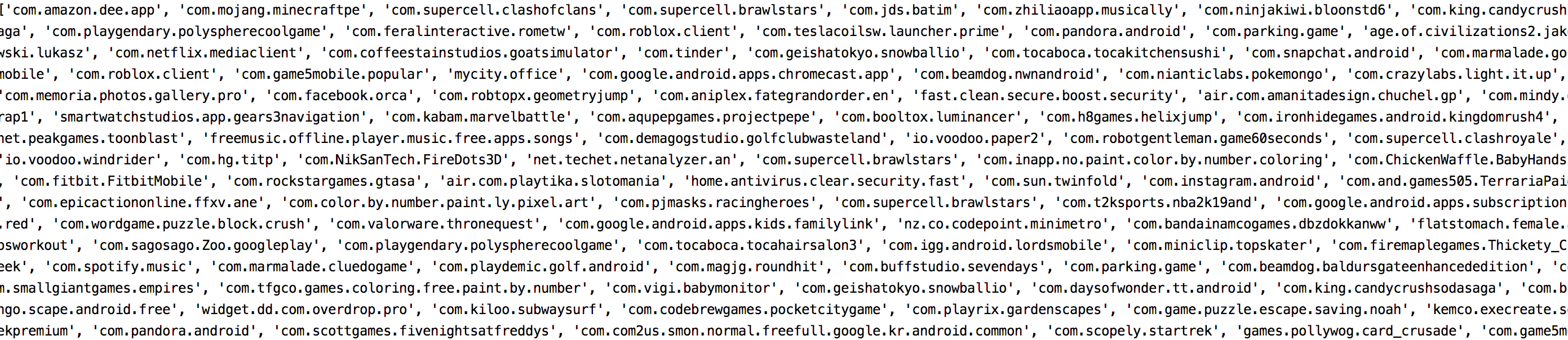
def get_content(self, response):
Result = response.body.decode()
getContent = re.findall(r'/apps/google-play/app/(.*?)/', Result)
print(getContent)
下面图片是我自己想要的数据
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号