卷积神经网络之VGG网络模型学习
VGG:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
牛津大学 visual geometry group(VGG)Karen Simonyan 和Andrew Zisserman 于14年发表的论文。论文地址:https://arxiv.org/pdf/1409.1556.pdf。与alex的文章虽然都采用层和每层之间用pooling层分开,最后三层FC层(Fully Connected全连接层)。但是AlexNet每层仅仅含有一个Convolution层,VGG每层含有多个(2~4)个Convolution层。AlexNet的filter的大小7x7(很大)而VGG的filter的大小是3x3(最小)。它通过降低filter的大小,增加层数实现更佳的效果。以下为论文解读。
ABSTRACT
研究了卷积网络深度对其大型图像识别的精准度的影响。主要贡献是使用非常小(3×3)卷积滤波器,将神经网络层次深度推到16-19层。2014年ImageNet分别在localisation和classification赛中获得了第一名和第二名。 同时模型对其他数据集很好地泛化。
1 INTRODUCTION
本文介绍了ConvNet架构的另一个重要方面设计 - 深度。很多人尝试改善2012年提出的AlexNet来实现更好的效果,ZFNet在第一卷积层使用更小的卷积(receptive window size)和更小的步长(stride)2,另一种策略是多尺度地在整张图像上密集训练和测试。
2 CONVNET CONFIGURATIONS
受到Ciresan et al.(2011); Krizhevsky et al. (2012).启发。为了公平测试深度带来的性能提升,VGGNet所有层的配置都遵循了同样的原则。
2.1 ARCHITECTURE
输入fixed-size 224 × 224 RGB image。数据预处理:每个像素上减去RGB的均值。在卷积层中小的Filter尺寸为3*3,有的地方使用1*1的卷积,这种1*1的卷积可以被看做是对输入通道的线性变换。卷积步长(stride)设置为1个像素,3*3卷积层的填充(padding)设置为1个像素。池化层采用max-pooling,共有5层,池化是2*2,步长为2。通过Relu进行非线性处理,增加网络的非线性表达能力。不使用局部响应标准化(LRN),这种标准化并不能在ILSVRC数据集上提升性能,却导致更多的内存消耗和计算时间。
2.2 CONFIGURATIONS
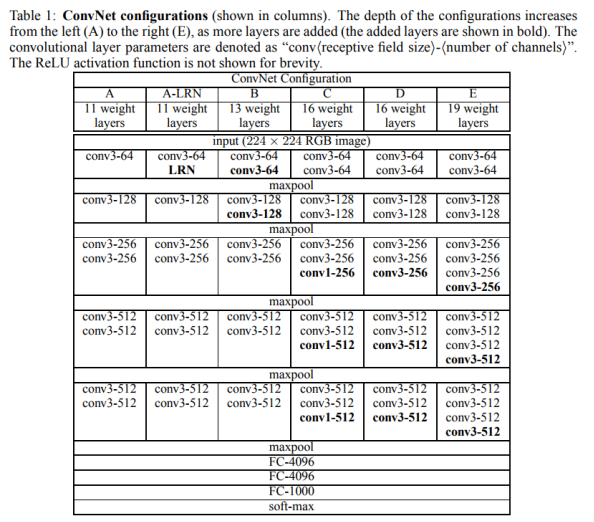

2.3 DISCUSSION
与AlexNet和ZFNet不同,VGGNet在网络中使用很小的卷积。用多个小filter代替大的filter更有好处。例如三个3*3卷积而不是一个7*7的卷积,因为每层后都有ReLU,我们结合了三个非线性整流层而不是单一层,这使得决策功能更具区分性。同类的网络例如Goodfellow et al的11层网络及GoogLeNet都采用的小的filter。
3 CLASSIFICATION FRAMEWORK
3.1 TRAINING
the input crops from multi-scale training images把原始 image缩放到最小边S>224后在图像上提取224*224crops,进行训练。
mini-batch gradient descent,batch size为256,momentum =0.9,权重衰减0.0005。
Dropout 在前两个全连接层。Dropout ratio设置为0.5。
3.2 TESTING
重缩放到尺寸Q,在网络中测试。细节论文介绍的很详细。
3.3 IMPLEMENTATION DETAILS
介绍了使用的机器及系统配置及训练时间。
4 CLASSIFICATION EXPERIMENTS
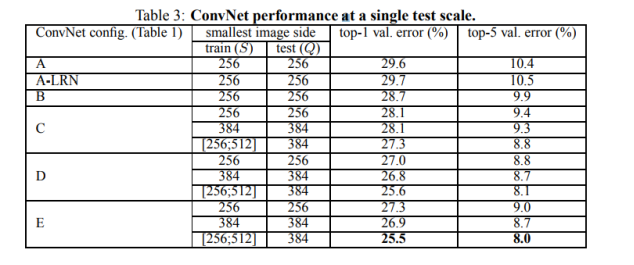
4.1 SINGLE SCALE EVALUATION
首先实验证明A-LRN network中用local response normalisation没有提升模型A的性能。所以在更深层次architectures (B–E)作者没有使用 normalisation。
训练数据集数据提升方法scale jittering显著的提高实验结果。
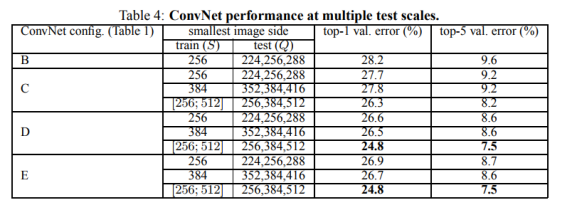
4.2 MULTI-SCALE EVALUATION
与表3对比,采用scale jittering在多尺度上评估可以提高分类的准确度。如表4所示。
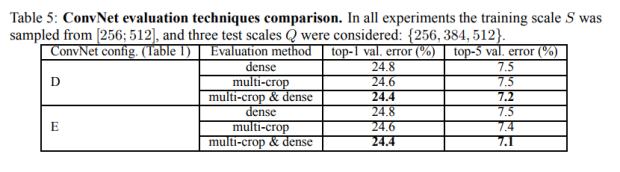
4.3 MULTI-CROP EVALUATION
表5展示的是多剪裁评估及密集评估,及两者结合的效果。单模型通过与 dense ConvNet evaluation对比,效果好一点,如果结合两个方法,多剪裁和密集型则效果还可以提升一点。
4.4 CONVNET FUSION
结合多个卷积网络的sofamax输出,将多个模型融合在一起输出结果。表6展示的是结果。

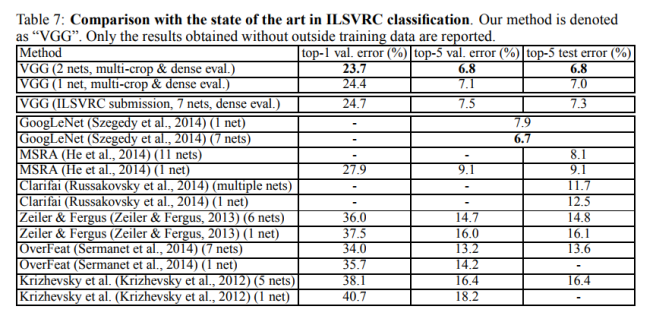
4.5 COMPARISON WITH THE STATE OF THE ART
与当前STATE OF THE ART的模型做比较。与之前12,13的网络对比VGG优势明显。与GoogLeNet比较单模型好一点,7个网络融合不如googleNet。
5 CONCLUSION
本文的19层深的卷积神经网络,在效果和泛化能力上有很好的成果。论证了深度对于cv问题的重要性。
本文参考
https://arxiv.org/pdf/1409.1556.pdf
http://m.blog.csdn.net/muyiyushan/article/details/62895202

 浙公网安备 33010602011771号
浙公网安备 33010602011771号