
Elasticsearch 第一篇:在 Windows 上的环境搭建
本文介绍如何在 windows 10 ,64位操作系统上安装最新版本 Elasticsearch、以及相关插件。之前看了不少园友的文章,用到的版本都比较低,尤其是插件的版本要和ES的版本相对应等这些问题,介绍的不是很详细,干脆自己记录一下安装配置过程,也供他人参考。
Elasticsearch简介
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
配置 java 环境
由于ES是Java语言开发的,所以这里需要先安装Java环境,jdk 下载地址是:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下载时,需要先注册Oracle账号,注册后选择下载 Windows x 64 .exe 这个最新版本(目前是 2020年7月,版本是 jdk14 )
双击 jdk-14_windows-x64-bin ,然后一直点击 “下一步” 按钮,直到安装完毕,默认的安装路径是 C:\Program Files\Java\jdk-14\ 按照默认路径安装即可
接下来,需要配置Java环境变量,右击 “我的电脑” ——点击 “属性” ——点击 “高级系统设置”,如下图

在新窗口的 “高级” 选项卡中,点击 “环境变量” ,再点击系统变量(S)里的 “新建” 按钮,弹出新窗口如下图所示
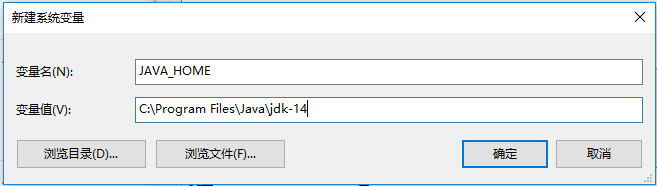
变量名填入: JAVA_HOME 变量值填入安装的路径: C:\Program Files\Java\jdk-14
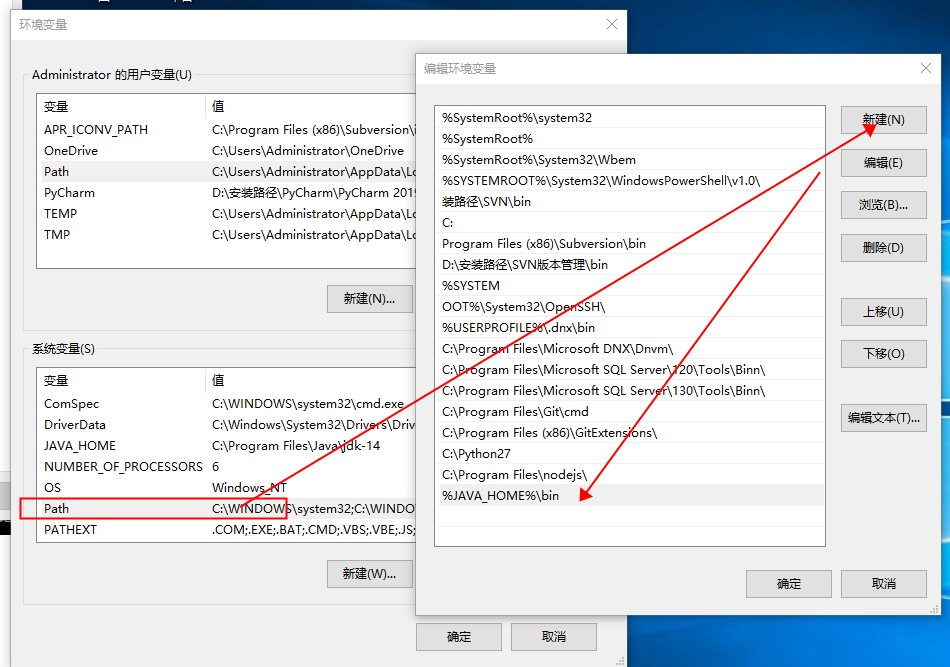
然后在系统变量(S)中,选中Path 这个变量,点击 “编辑” 按钮,打开编辑窗口,再点击 “新建” 按钮,输入 %JAVA_HOME%\bin 如下图所示
最后验证一下配置是否成功,打开 cmd 窗口(以管理员形式打开),输入命令 java -version 或者命令 javac 可以看安装是否成功,如下图
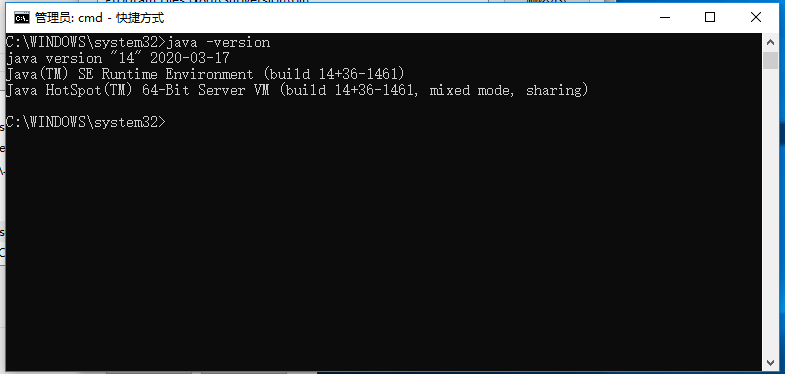
以上说明安装成功,java 版本是14
下载并安装 Elasticsearch
ES工具包下载地址是:http://www.elasticsearch.org/download/
我们选择版本 7.8.0 window 这个版本,先在D盘建一个 ES 目录(方便管理),将下载的包解压到 ES 目录中,如下图所示
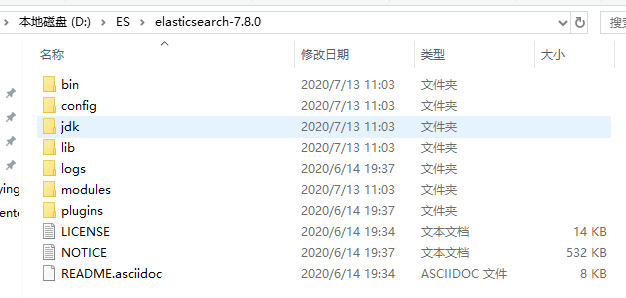
以管理员身份运行,打开cmd窗口,进入ES的bin目录: cd /d D:\ES\elasticsearch-7.8.0\bin
然后运行命令 elasticsearch.bat

稍等片刻,然后在浏览器中访问 http://localhost:9200/
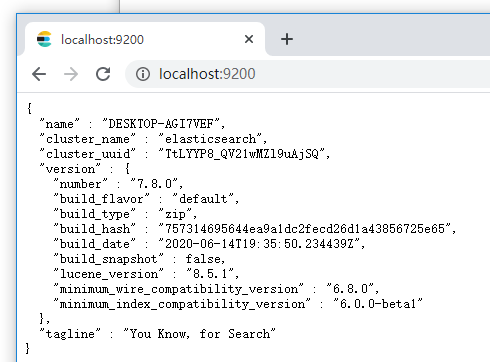
以上说明 ES 相关包已经成功安装
安装Head插件
安装 Head 插件的前提,是需要将 node、grunt 安装和配置完善。
1、首先下载 node.js
下载地址是 https://nodejs.org/en/download/
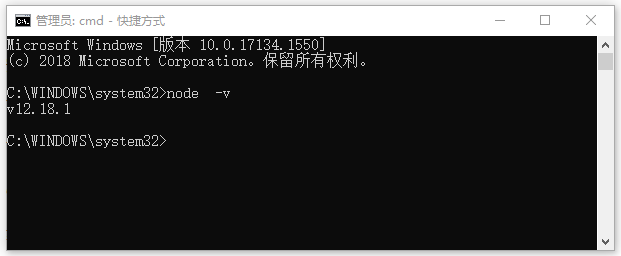
选择window 64位的版本 v12.18.1,一直点击 “下一步” 按钮,直到安装完毕,下载完成可以通过命令 node -v 查看安装版本以及是否成功,如下图
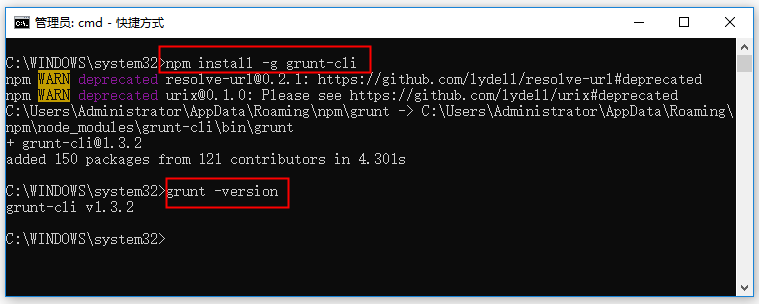
2、安装grunt
以管理员身份打开cmd命令窗口,执行 npm install -g grunt-cli 然后通过 grunt -version 看安装的版本
3、下载 Head
Head 相关文档 http://mobz.github.io/elasticsearch-head/
或者直接到 https://github.com/mobz/elasticsearch-head 下载 zip 包到本地。请注意,上面ES安装的版本是 v.7.8.0 ,这里 Head 插件也要选择 master 这个版本下载。
下载完,我们将其解压到上面提到的D盘ES目录,跟ES放在同一级目录,方便管理,如下图所示

cmd 进入head 目录: cd /d D:\ES\elasticsearch-head-master
然后执行命令:npm install 如下图所示

上图执行过程卡住了,主要是缺少 phantomjs-2.1.1-windows ,按照上边的提示,先下载这个文件,
然后放在目录 C:\Users\ADMINI~1\AppData\Local\Temp\phantomjs\phantomjs-2.1.1-windows.zip
顺便解压一下,再重新试一下执行 npm install ,这次执行成功了,见下图
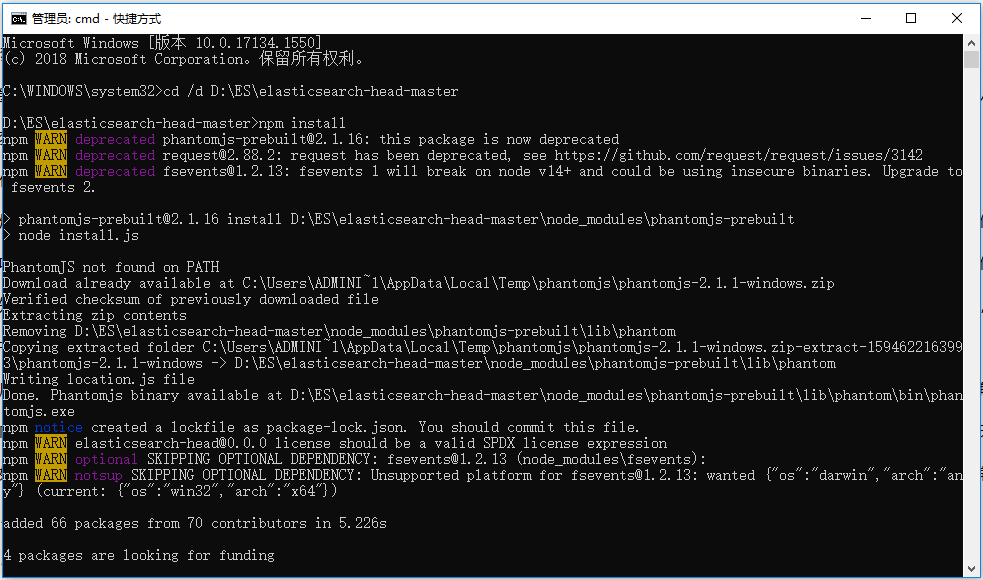
然后执行 npm start ,启动 Head 插件,如下图所示
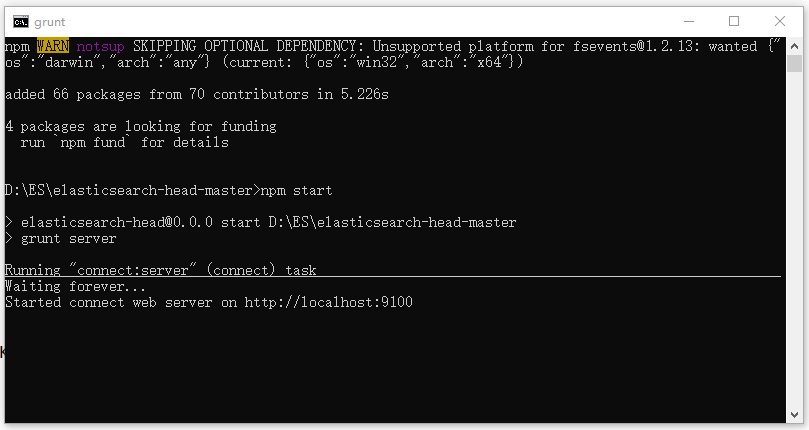
再访问 http://localhost:9100 可以看到下图效果
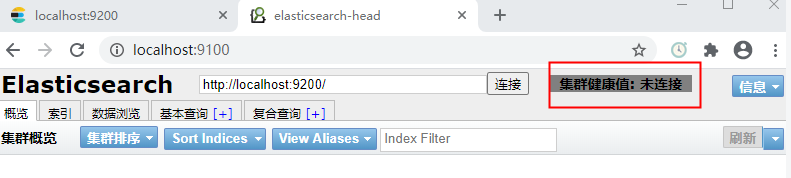
虽然Head已经是安装成功,但是目前是未连接状态,上网查一下资料,需要做以下配置:
找到文件 D:\ES\elasticsearch-7.8.0\config\elasticsearch.yml 在该文件最后添加以下语句:
http.cors.enabled: true
http.cors.allow-origin: "*"
然后再重启ES,重启Head:
重启ES cd /d D:\ES\elasticsearch-7.8.0\bin\elasticsearch.bat
重启Head cd /d D:\ES\elasticsearch-head-master\npm start
再访问 http://localhost:9200/ 以及 http://localhost:9100/
这时可以看到,现在连接上了,灰色变成绿色,Head 安装成功。
为什么要这样配置,可以参考文章 https://www.cnblogs.com/sanduzxcvbnm/p/11969634.html
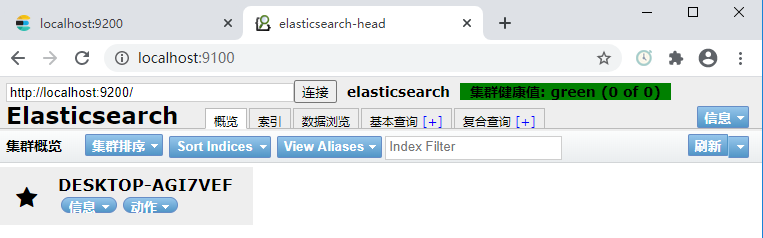
总结一下,Head 插件安装比较麻烦,但是通过看报错信息以及网上资料文档,多多尝试,是可以解决的。
安装 Kibana
Kibana 插件是一个可视化的插件,非必须,如果需要安装也可以参考以下的流程
下载地址是 https://www.elastic.co/cn/downloads/kibana
注意,我们 用的ES版本是 v7.8.0 , Kibana 安装的版本也是要和ES的同步,这里选择 Kibana版本为 7.8.0
同样,下载完毕后,我们将其解压到 D:\ES\kibana-7.8.0
同样以管理员身份打开cmd 窗口执行命令
cd /d D:\ES\kibana-7.8.0\bin
kibana.bat
执行完,能正常打开 http://localhost:5601 即成功,Kibana 要怎么用,以后再来详细说明。
安装分词器 IK
ES默认的分词器,对中文的分解不是很好,所以需要用到其它分词器,这里以IK分词器为例,介绍怎么安装。
首先往ES添加索引,用 postman 提交数据:
put http://localhost:9200/db_news/new/1
注意:这次提交,会自动创建索引库 db_news 并创建文档 type=new id=1,其实在ES7版本中,已经弃用 type 的概念,实际上应该是 put http://localhost:9200/db_news/_doc/1
如果要查看ES创建的索引库 db_news 的结构,可以这样查询 get http://localhost:9200/db_news/_mapping 后面的博客将会继续讲解 mapping,这里不再详细解说
{
"title":"今日头条新闻",
"author":"新华时报记者",
"content":"今日券商股继续涨停"
}
提交后可以看到返回结果
{
"_index": "db_news",
"_type": "new",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
如果我们用ES原生的分词器,例如
get http://localhost:9200/db_news/_analyze
{
"analyzer":"standard",
"text":"我是中国人,我爱自己的祖国"
}
分词结果是
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "中",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "国",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "人",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
},
{
"token": "我",
"start_offset": 6,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 5
},
{
"token": "爱",
"start_offset": 7,
"end_offset": 8,
"type": "<IDEOGRAPHIC>",
"position": 6
},
{
"token": "自",
"start_offset": 8,
"end_offset": 9,
"type": "<IDEOGRAPHIC>",
"position": 7
},
{
"token": "己",
"start_offset": 9,
"end_offset": 10,
"type": "<IDEOGRAPHIC>",
"position": 8
},
{
"token": "的",
"start_offset": 10,
"end_offset": 11,
"type": "<IDEOGRAPHIC>",
"position": 9
},
{
"token": "祖",
"start_offset": 11,
"end_offset": 12,
"type": "<IDEOGRAPHIC>",
"position": 10
},
{
"token": "国",
"start_offset": 12,
"end_offset": 13,
"type": "<IDEOGRAPHIC>",
"position": 11
}
]
}
显然,这样的分词毫无意义,这也是我们要安装IK分词器的原因。
IK分词器下载地址 https://github.com/medcl/elasticsearch-analysis-ik 同样用 7.8.0 版本
在 D:\ES\elasticsearch-7.8.0\plugins 新建 ik 文件夹,将以上下载的包解压到这里,如下图所示
然后重启 ES,再进行IK分词测试
Get http://localhost:9200/db_news/_analyze
{
"analyzer":"ik_smart",
"text":"我是中国人,我爱自己的祖国"
}
返回分词结果是
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "我",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 3
},
{
"token": "爱",
"start_offset": 7,
"end_offset": 8,
"type": "CN_CHAR",
"position": 4
},
{
"token": "自己",
"start_offset": 8,
"end_offset": 10,
"type": "CN_WORD",
"position": 5
},
{
"token": "的",
"start_offset": 10,
"end_offset": 11,
"type": "CN_CHAR",
"position": 6
},
{
"token": "祖国",
"start_offset": 11,
"end_offset": 13,
"type": "CN_WORD",
"position": 7
}
]
}
可以看到,分词后不再是一个汉字分成一组,而是一个名词分成一组,这样方便我们进行关键词匹配和检索,具体用法可以看后续博文,至此,IK分词也安装成功。
本文关于环境搭建的过程,已经写得很详细了,关于ES的应用,可以看后续的更新。
总结
启动 ES cd /d D:\ES\elasticsearch-7.8.0\bin 再执行 elasticsearch.bat 访问 http://localhost:9200/
启动Head cd /d D:\ES\elasticsearch-head-master 再执行 npm start 访问 http://localhost:9100/
启动Kibana cd /d D:\ES\kibana-7.8.0\bin 再执行 kibana.bat 访问 http://localhost:5601
存在问题:以上我安装IK分词器后,直接重启ES,分词器马上生效,如果我换其它分词器,是不是也是直接重启ES就可以了呢?
还有,如果我原来就建立了索引库,更新分词器后,应该怎么处理原来的索引?知道的朋友可以评论一下。

