[读书笔记] Python 数据分析 (十二)高级NumPy
da
array: 一个快速而灵活的同构多维大数据集容器,可以利用这种数组对整块的数据进行一些数学运算
- 数据指针,系统内存的一部分
- 数据类型 data type/dtype
- 指示数据大小的元组
- stride: strides中保存的是当每个轴的下标增加1时,数据存储区中的指针所增加的字节数
- In [6]: np.ones((3,4,5),dtype=np.float64).strides
Out[6]: (160, 40, 8)
ndarray数据结构:

reshape()函数 -1参数,该维度的的内容由原内容自动填充
C vesu Fortran order:
- : row order
- Fortran order: column order
numpy 的 ndarray 是row order, reshape()和ravel()函数都接受一个参数进行C/F转换
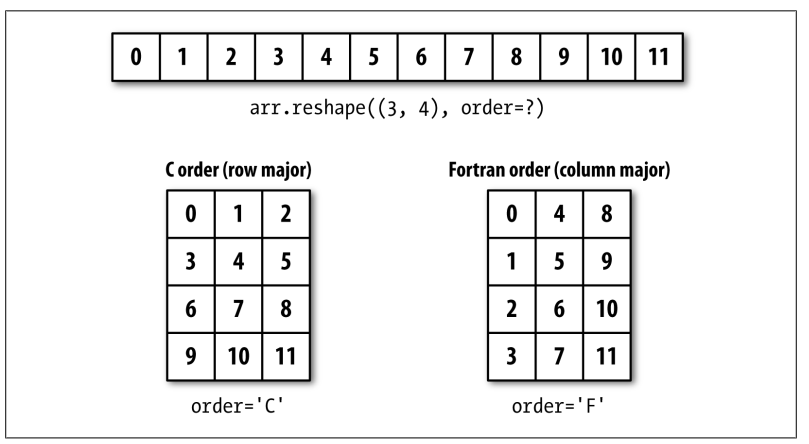
数组重构

更加简洁的数组重构方式:c_, r_c

数组重复/复制
repeat: 重复数组中的每一个元素特定次数,可以为每一个元素指定重复次数

tile:在指定轴上重复复原
Take and Put
取出数组中的特定元素
Broadcasting/广播
沿X轴传播和沿Y轴传播有细微的差别
np.newaxis()加入新轴
Advanced ufunc Usage
ufunc 是universal function的缩写,它是一种能对数组的每个元素进行操作的函数,Numpy内置的许多ufunc函数都是在C语言级别实现的,因此它们的计算速度非常快
- np.add.reduce: 加和操作
- np.add.accumulate: 和reduce类似,返回和输入数组形状相同,保存所有的中间计算结果
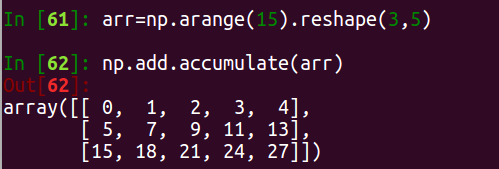
- np.multiply.outer: element-wise 点积

用户自定义函数
frompyfunc
Structured and Record Arrays
使用dtype创建结构化的表格型数据,类似C中的结构
numpy 排序
argsort:
lexsort: multiple sort

searchsorted
- 查找已排序数组中的元素,返回查找值在数组中应该插入的位置,该种插入方式可以使得数组仍是有序的
- 也可以用来查找元素在一定区间中的位置
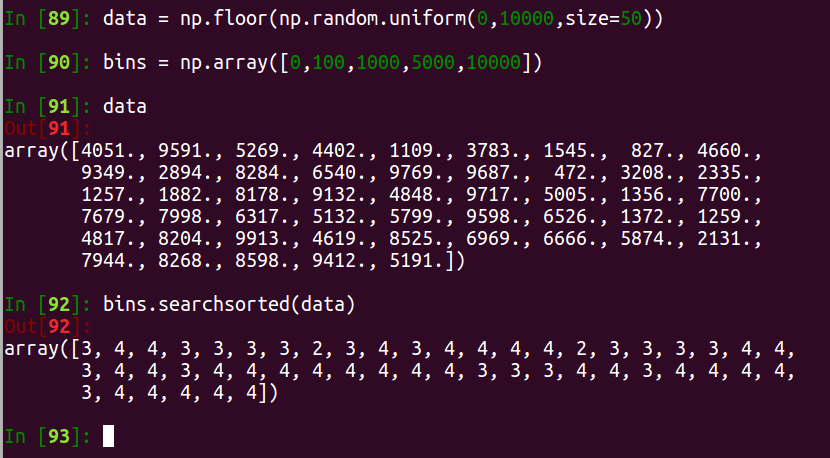
Speed Performance:
Cpython

 浙公网安备 33010602011771号
浙公网安备 33010602011771号