【Tool】Linux下的Spark安装及使用
1. 确保自己的电脑安装了JAVA Development Kit JDK, 用来编译Java应用, 如 Apache Ant, Apache Maven, Eclipse. 这里是我们安装Spark的支持环境.
查看自己是否安装了JDK: java -version
这里我已经安装了所以显示的是JDK的版本信息, 如果没有安装则显示"The program java can be found in the following packages"

2. 安装好Java环境之后可以在Spark官网上下载自己要的Spark版本: http://spark.apache.org/downloads.html
下载之后解压缩: tar -xf spark-***-bin-hadoop**.tgz(对应着你下载的版本号)
3. 更新profile文件: sudo vi ~/etc/profile 在后面加入:
SPARK_HOME=/home/vincent/Downloads/spark #(解压后的包所在的路径, 这里我将解压后的Spark重新命名为spark了) PATH=$PATH:${SPARK_HOME}/bin
4. 进入spark安装位置, 然后进入spark中的 bin 文件夹
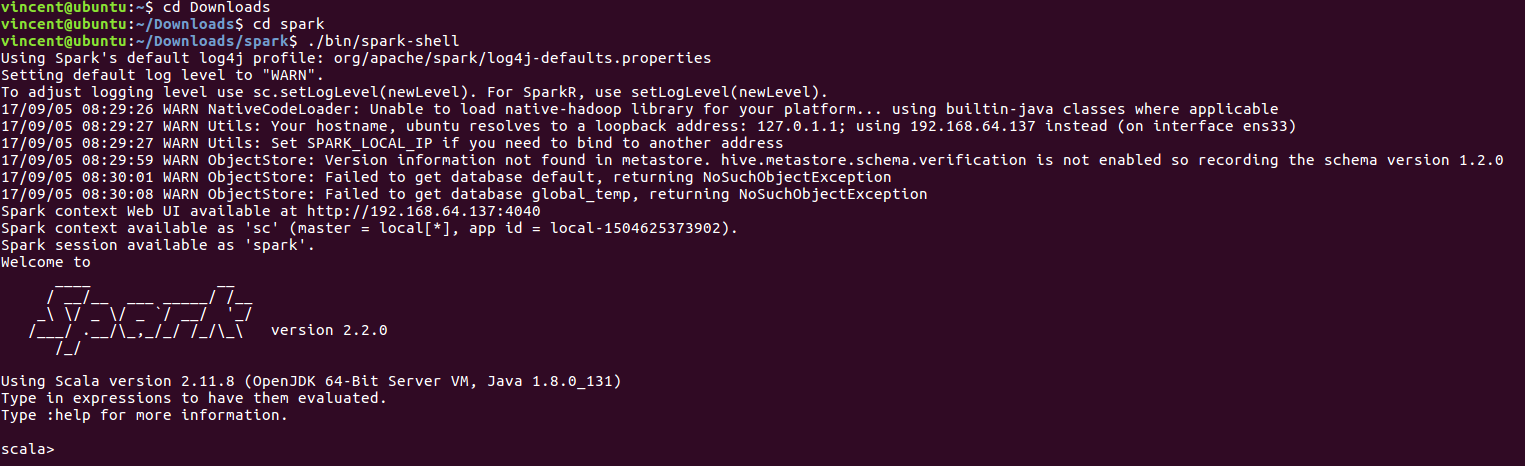
运行: ./bin/spark-shell 运行scala
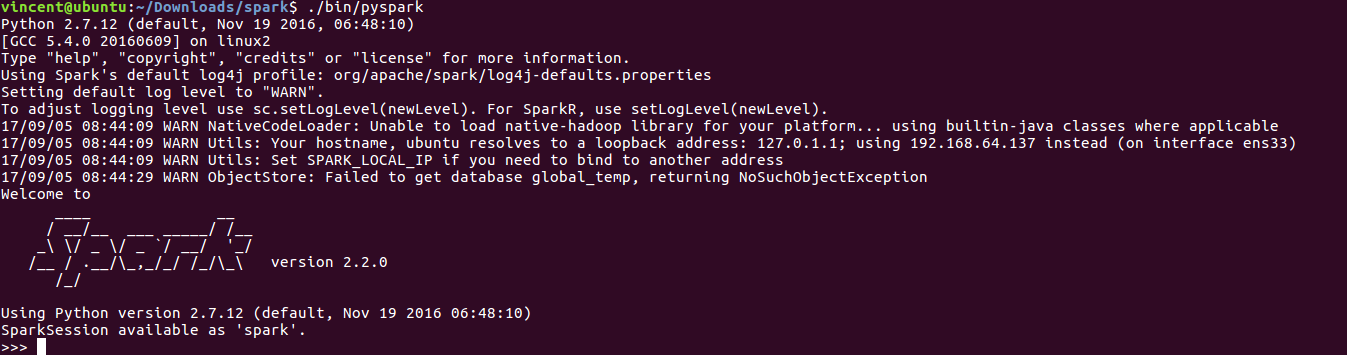
运行: ./bin/pyspark (python)
5. 调整日志级别控制输出的信息量:
在conf目录下将log4j.properties.template 复制为 log4j.properties, 然后找到 log4j.rootCategory = INFO, console

将INFO改为WARN (也可以设置为其他级别)

之后再打开shell输入信息量会减少.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号