[读书笔记] 机器学习(二):模型评估与选择
1. 经验误差与过拟合
- error rate/accuracy
- error: training error/empirical error, generalization error(机器学习的目的:得到泛化误差小的学习器)
- overfitting and underfitting:平衡训练样本和潜在样本
2. 评估方法
要评估模型需要对模型的泛化误差进行评估,但是我们无法直接获得泛化误差,训练误差不适合作为评价标准。
解决办法:使用一个测试集testing set测试学习期对新新样本的判别能力,使用testing error 对 generalization error 进行近似
如何在数据集$S$中产生训练集$S$和测试集$T$?
- 留出法(hold out):直接将数据集$D$划分为两个互斥的集合 $D = S \cap T, S \cap T = \varnothing$,多次试验求平均
- 交叉验证(cross validation):将数据集$D$ 分为K个大小相似的互斥子集,每个子集由分层抽样得到。每次使用K-1个子集的并集作为训练集,剩下一个集作为测试集。可以进行K次交叉验证,最终对K次试验准确率结果求均值. K常取10.
特例:留一法(leave one out):k-cross validation的特例,评估结果和使用D训练出来的模型很相似,但是计算复杂度太大,也未必比其他方法准确.
- 自助法:bootstrapping:以bootstrap sampling为基础,给定包含m样本的数据集$D$, 对它采样产生数据集${D}'$, 每次有放回从D中随机挑选放入${D}'$,$D$中样本不会再${D}'$出现的概率是:
$$ lim_{m \rightarrow \infty} (1- \frac{1}{m})^m \rightarrow \frac{1}{e} \approx 0.368 $$
可以使用${D}'$作为训练集,$D - {D}'$ 作为测试集, 解决了前两种方式减少训练集大小的问题,而且测试数据仍然没有在训练集中出现过.
优点:在数据集小,难以有效划分训练集,测试集时很有用,自助法能从初始数据中产生多个不同训练集,这对集成学习有很大的好处。
缺点:改变原始数据分布,会引入估计偏差,因此在数据量足够时还是留出法和交叉验证法更常用.
分层采样(stratified sampling):在数据划分的过程中要保持原始样本类别的比例,避免引入额外的误差
3. 调参与最终模型:测试数据和验证数据的区别,最终模型要使用所有的训练数据训练确定.
4. 性能度量
在面对不同的任务时,对比不同的模型能力,使用不同的性能度量会导致不同的结果(模型的好坏是相对的)
- 错误率,精度
$$E(f,D) = \frac{1}{m} \sum_{i=1}^m \mathbb{I}(f(x_i) \neq y_i)$$
$$acc(f,D) = \frac{1}{m} \sum_{i=1}^m \mathbb{I}(f(x_i) = y_i)$$
更一般对于数据分布$D$和概率密度函数$p(\cdot)$,错误率和精度可分别描述为:
$$E(f,D) = \int_{x \sim D} \mathbb{I}(f(x_i) \neq y_i)p(x)dx$$
$$acc(f,D) = \int_{x \sim D} \mathbb{I}(f(x_i) = y_i)p(x)dx$$
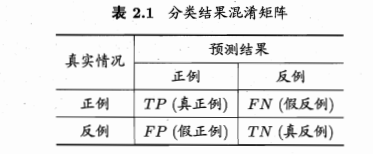
- 查全率(recall),查准率(precision),F1
二分类问题真实类别与预测类别的比例:真正(true positive, TP), 真反(true negative, TN), 假正(false positive, FP), 假反(false negative, FN).

$P = \frac{TP}{TP+FP}$ : 在你的所有预测中,预测正确的比例.
$R = \frac{TP}{TP+FN}$ :你预测为正类样本的数目,占所有应该预测为正类样本的数目.
二者是一对矛盾的量,查全率高,查准率会降低;查准率高,查全率对低.
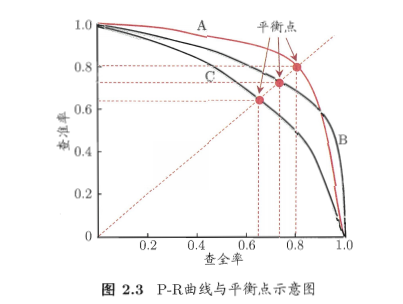
P-R图:根据学习器预测结果对样例进行排序,排在前面的是最可能是正列,最后面的是最不可能是正例. 以查准率为纵轴,查全率为横轴,按顺序逐个把样例为正例(即排在它前面的都是正例,后面的为反例)画出P-R曲线.
- ROC与AUC
在计算问题中,我们对样例预测结果进行了一个排序,从最可能是正例到最不可能是正例,然后我们选择一个截断点 cut point,前面是正例,后面是反例. 如果我们更重视查准率,选取更前面的阈值,更重视查全 率,选取更后面的阈值. 因此排序质量本身的好坏,体现了综合学习器任务下“期望泛化性能的好坏”,ROC是从这个角度出发研究机器学习泛化性能的有力工具.
ROC全称是受试者工作特征(Receiver operating characteristic), 源于二战中用于敌机检测的雷达信号分析技术. ROC曲线纵轴是真正率(True positive rate),横轴是假正率(false positive rate). 二者定义为:
$$ TPR = \frac{TP}{TP + FN},$$
$$ FPR = \frac{FP}{TN + FP}.$$
前者是你预测为正例中,准确(正)个数占所有正例个数比例
后者是你预测为正例中,错误(反)个数占所有反例个数比例
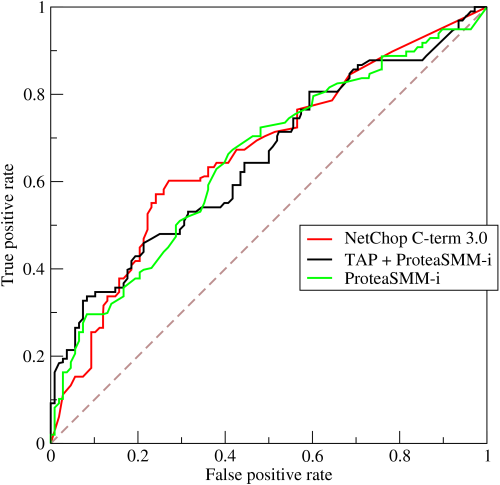
AUC(area under curve):可以通过比较曲线下面的面积来对比不同模型的好坏
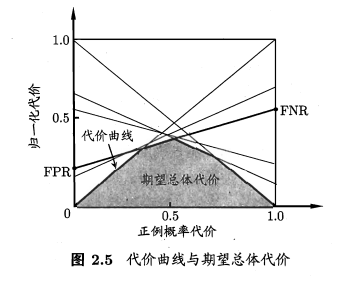
- 代价敏感错误率与代价曲线
在面对具体任务需求的时候,不同的错误类型造成的后果不一样. 患者健康诊断 vs. 门禁系统 为了权衡不同错误类型造成的不同损失,可为错误赋予非均等代价(unequal cost).
5. 比较检验
有了实验评估方法和性能度量,我们就可以着手对结果进行评估. 但是这里有几个问题:1. 我们希望比较的是泛化性能,而通过实验评估方法我们获得的是测试集上的性能,两者对比结果未必相同;2. 测试集的性能和测试集的本身选取有很大关系
涉及到测试集的大小,即使测试集大小相同,样例不同,结果也会不同;3. 很多机器学习算法本身具有随机性,相同参数在同一个测试集上多次运行,结果也会有不同.
因此我们要引入统计假设检验(hypothesis test) 对学习器性能进行评价, 即在测试集上观察到A比B好,那么A的泛化性能是否在统计意义上优于B?这个结论的把握多大?
这里很多概率论与数理统计知识已经遗忘,等复习了这一块回来总结!
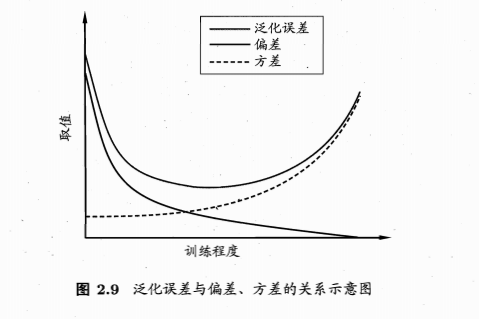
6. 偏差与方差
偏差方差分解(bias-variance decomposition)通过对学习算法期望的泛化错误率来了解学习算法为什么具有这样的性能.
对测试样本$x$, 令$y_D$为$x$在数据集中标记,$y$为x真实标记(有可能有噪声使得$y_D \neq y$), $f(x,D)$为$D$在学的模型$f$在$x$上的预测输出:
预测期望为:$\bar{f}(x) = E_D[f(x,D)],$
使用样本数相同不同训练集方差为:$var(x) = E_D[(f(x,D) - \bar{f}(x))^2],$
噪声为:$\epsilon^2 = E_D[(y_D - y)^2]$
期望输出与真实标记的差别称为bias:$bias^2(x) = (\bar{f}(x) - y)^2$, 为了便于讨论假设噪声期望为0,$E_D[y_D - y] = 0$
推导过程省略...
$$E(f;D) = bias^2(x) + var(x) + \epsilon^2$$
泛化误差分解为偏差,方差与噪声之和
- 偏差度量了学习算法的期望预测与真实结果偏离程度,刻画了学习算法本身的拟合能力(算法能力)
- 方差度量了同样样本大小的训练集的变动所导致的学习性能的变化,刻画了数据扰动造成的影响(数据充分性)
- 噪声表达了在当前任务上任何学习算法所能达到的期望误差泛化误差下届,刻画了学习问题本身的难度
对于给定的任务,我们希望使偏差较小,即充分拟合数据,方差也较小,即数据扰动影响小;但是这二者一般是矛盾的(bias-variance dilemma)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号