
tensorflow RNN和简单例子
一、用LSTM单层的网络来做分类的问题
用lstm对mnist的数据集进行分类


1 #!/usr/bin/python 2 # -*- coding: UTF-8 -*- 3 import tensorflow as tf 4 from tensorflow.examples.tutorials.mnist import input_data 5 import tensorflow.contrib as contrib 6 tf.set_random_seed(1) 7 8 ##导入数据 9 mnist = input_data.read_data_sets('../mnist_data',one_hot=True) 10 11 ##超参数 12 lr = 0.001 # learning rate 13 training_iters = 100000 # train step 上限 14 batch_size = 128 15 n_inputs = 28 # MNIST data input (img shape: 28*28) 16 n_steps = 28 # time steps 17 n_hidden_units = 128 # neurons in hidden layer 18 n_classes = 10 # MNIST classes (0-9 digits) 19 20 ## x,y placeholder 21 x = tf.placeholder(tf.float32,[None,n_steps,n_inputs]) 22 y = tf.placeholder(tf.float32,[None,n_classes]) 23 24 ## 对 weights biases 的初始值的定义 25 weights ={ 26 # shape (28, 128) 27 "in":tf.Variable(tf.truncated_normal([n_inputs,n_hidden_units])), 28 # shape (128, 10) 29 'out':tf.Variable(tf.truncated_normal([n_hidden_units,n_classes])) 30 } 31 biases ={ 32 # shape (128, ) 33 'in':tf.Variable(tf.constant(0.1,shape=[n_hidden_units,])), 34 # shape (10, ) 35 'out':tf.Variable(tf.constant(0.1,shape=[n_classes,])) 36 } 37 # 定义 RNN 的主体结构(input_layer, cell, output_layer) 38 def RNN(X,weights,biases): 39 # 原始的 X 是 3 维数据, 我们需要把它变成 2 维数据才能使用 weights 的矩阵乘法 40 # X ==> (128 batches * 28 steps, 28 inputs) 41 X = tf.reshape(X,[-1,n_inputs]) 42 # X_in = W*X + b 43 X_in = tf.matmul(X,weights['in'])+biases['in'] 44 # X_in ==> (128 batches, 28 steps, 128 hidden) 换回3维 45 X_in = tf.reshape(X_in,[-1,n_steps,n_hidden_units]) 46 47 # 使用 basic LSTM Cell. 48 lstm_cell = contrib.rnn.BasicLSTMCell(num_units=n_hidden_units,forget_bias=1.0,state_is_tuple=True) 49 init_state = lstm_cell.zero_state(batch_size, dtype=tf.float32) 50 ## 如果 inputs 为 (batches, steps, inputs) ==> time_major=False; 如果 inputs 为 (steps, batches, inputs) ==> time_major=True; 51 outputs, final_state = tf.nn.dynamic_rnn(cell=lstm_cell,inputs=X_in,initial_state=init_state,time_major=False) 52 53 ###最后是 output_layer 和 return 的值. 因为这个例子的特殊性, 有两种方法可以求得 results. 54 ### 方法一: 直接调用final_state 中的 h_state (final_state[1]) 来进行运算 55 results = tf.matmul(final_state[1],weights['out'])+biases['out'] 56 ## 调用最后一个 outputs (在这个例子中,和上面的final_state[1]是一样的) 57 # 把 outputs 变成 列表 [(batch, outputs)..] * steps 58 # outputs = tf.unstack(tf.transpose(outputs, [1, 0, 2])) 59 # results = tf.matmul(outputs[-1], weights['out']) + biases['out'] # 选取最后一个 output 60 return results 61 62 63 64 # 定义好了 RNN 主体结构后, 我们就可以来计算 cost 和 train_op 65 pred = RNN(x, weights, biases) 66 cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y)) 67 train_op = tf.train.AdamOptimizer(lr).minimize(cost) 68 # train_op = tf.train.AdadeltaOptimizer(lr).minimize(cost) ## 这出错了啦!!!!!! 69 70 correct_pred = tf.equal(tf.argmax(pred,1),tf.argmax(y,1)) 71 accuracy = tf.reduce_mean(tf.cast(correct_pred,tf.float32)) 72 73 init_op = tf.global_variables_initializer() 74 with tf.Session() as sess: 75 sess.run(init_op) 76 step = 0 77 while step * batch_size < training_iters: 78 batch_xs,batch_ys = mnist.train.next_batch(batch_size) 79 batch_xs = batch_xs.reshape([batch_size,n_steps,n_inputs]) 80 sess.run([train_op],feed_dict={x:batch_xs,y:batch_ys}) 81 82 if step % 20 ==0: 83 print(sess.run(accuracy,feed_dict={x:batch_xs,y:batch_ys})) 84 step += 1
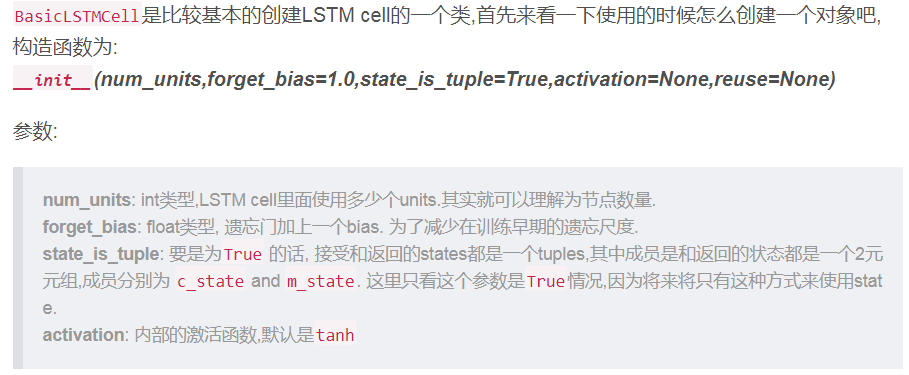
上例中,使用到关于LSTM的方法主要是
1) tensorflow.contrib.rnn.BasicLSTMCell





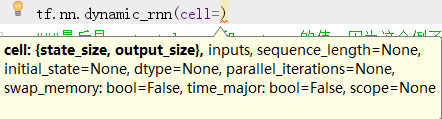
cell: RNNCell的对象. inputs: RNN的输入,当time_major == False (default) 的时候,必须是形状为 [batch_size, max_time, ...] 的tensor,
要是 time_major == True 的话, 必须是形状为 [max_time, batch_size, ...] 的tensor. 前面两个维度应该在所有的输入里面都应该匹配. sequence_length: 可选,一个int32/int64类型的vector,他的尺寸是[batch_size]. 对于最后结果的正确性,
这个还是非常有用的.因为给他具体每一个序列的长度,能够精确的得到结果,排除了之前为了把所有的序列弄成一样的长度padding造成的不准确. initial_state: 可选,RNN的初始状态. 要是cell.state_size 是一个整形,那么这个参数必须是一个形状为 [batch_size, cell.state_size] 的tensor.
要是cell.state_size 是一个tuple, 那么这个参数必须是一个tuple,其中元素为形状为[batch_size, s] 的tensor,s为cell.state_size 中的各个相应size. dtype: 可选,表示输入的数据类型和期望输出的数据类型.当初始状态没有被提供或者RNN的状态由多种形式构成的时候需要显示指定. parallel_iterations: 默认是32,表示的是并行运行的迭代数量(Default: 32).
有一些没有任何时间依赖的操作能够并行计算,实际上就是空间换时间和时间换空间的折中,当value远大于1的时候,
会使用的更多的内存但是能够减少时间,当这个value值很小的时候,会使用小一点的内存,但是会花更多的时间. swap_memory: Transparently swap the tensors produced in forward inference but needed for back prop from GPU to CPU.
This allows training RNNs which would typically not fit on a single GPU, with very minimal (or no) performance penalty. time_major: 规定了输入和输出tensor的数据组织格式,如果 true, tensor的形状需要是[max_time, batch_size, depth].
若是false, 那么tensor的形状为[batch_size, max_time, depth].
要是使用time_major = True 的话,会更加高效率一点,因为避免了在RNN计算的开始和结束的时候对于矩阵的转置 ,
然而,大多数的tensorflow数据格式都是采用的以batch为主的格式,所以这里也默认采用以batch为主的格式. scope: 子图的scope名称,默认是”rnn”

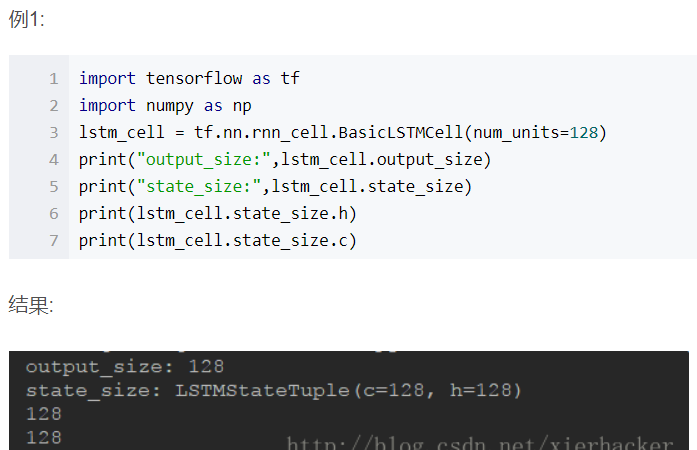
import tensorflow as tf import numpy as np inputs = tf.placeholder(np.float32, shape=(32,40,5)) # 32 是 batch_size lstm_cell_1 = tf.contrib.rnn.BasicLSTMCell(num_units=128) print("output_size:",lstm_cell_1.output_size) ## 128 print("state_size:",lstm_cell_1.state_size) ## LSTMStateTuple(c=128, h=128) output,state=tf.nn.dynamic_rnn( cell=lstm_cell_1, inputs=inputs, dtype=tf.float32 ) print("output.shape:",output.shape) ##(32,40,128) print("len of state tuple",len(state)) ## 2 print("state.h.shape:",state.h.shape) ## (32,128) print("state.c.shape:",state.c.shape) ##(32,128)
其实在运用时,很简单,如在 mnist的例子中,使用如下:
# X_in ==> (128 batches, 28 steps, 128 hidden) 换回3维 X_in = tf.reshape(X_in,[-1,n_steps,n_hidden_units]) # 使用 basic LSTM Cell. lstm_cell = contrib.rnn.BasicLSTMCell(num_units=n_hidden_units,forget_bias=1.0,state_is_tuple=True) init_state = lstm_cell.zero_state(batch_size, dtype=tf.float32) ## 如果 inputs 为 (batches, steps, inputs) ==> time_major=False; 如果 inputs 为 (steps, batches, inputs) ==> time_major=True; outputs, final_state = tf.nn.dynamic_rnn(cell=lstm_cell,inputs=X_in,initial_state=init_state,time_major=False)
------
参考:
TensorFlow学习(十三):构造LSTM超长简明教程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号