Tensorflow-gpu训练SSD时遇到的问题及解决方法
训练环境与步骤参考链接:
https://www.cnblogs.com/hayley111/p/12918678.html
问题一:使用GTX2080的显卡,在batch_size只有8的情况下,训练速度只有2-3秒每步。
另开窗口使用如下指令查看GPU占用情况,指令如下:
nvidia-smi -l
结果如下:(如果你和我一样GPU占用率很低,说明cuda没有正常运行)
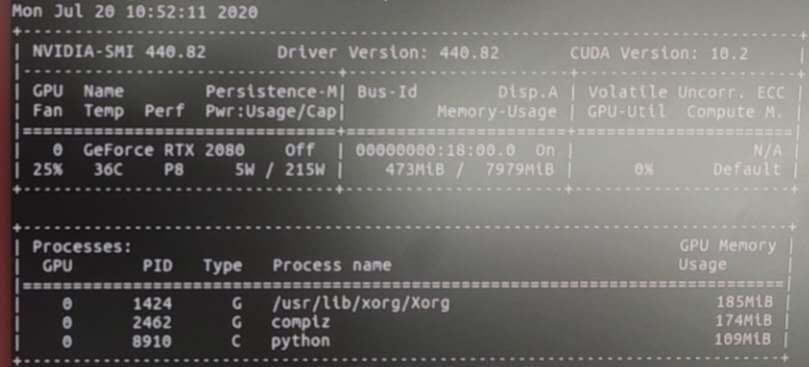
问题原因:cuda没有成功启动,只有cudnn在运行。
解决方法:
第一步:重新切换到cuda10.0
切换cuda版本 tensorflow1.12使用cuda9.0
yolo,tensorflow1.14等使用cuda10.0
cd /usr/local
删除之前的软链接
sudo rm -rf cuda
重新创建软连接到10.0
sudo ln -sf cuda-10.0 cuda
第二步:安装keras(我这里选的是2.2.4版本的)
pip install keras==2.2.4
第三步:修改train.py代码,增加几行代码如下:
import keras config = tf.ConfigProto() config.gpu_options.allow_growth = True keras.backend.tensorflow_backend.set_session(tf.Session(config=config))
添加位置如下:

重新执行你的训练指令就可以了。
正常使用GPU训练的情况下,GPU占用情况如下。
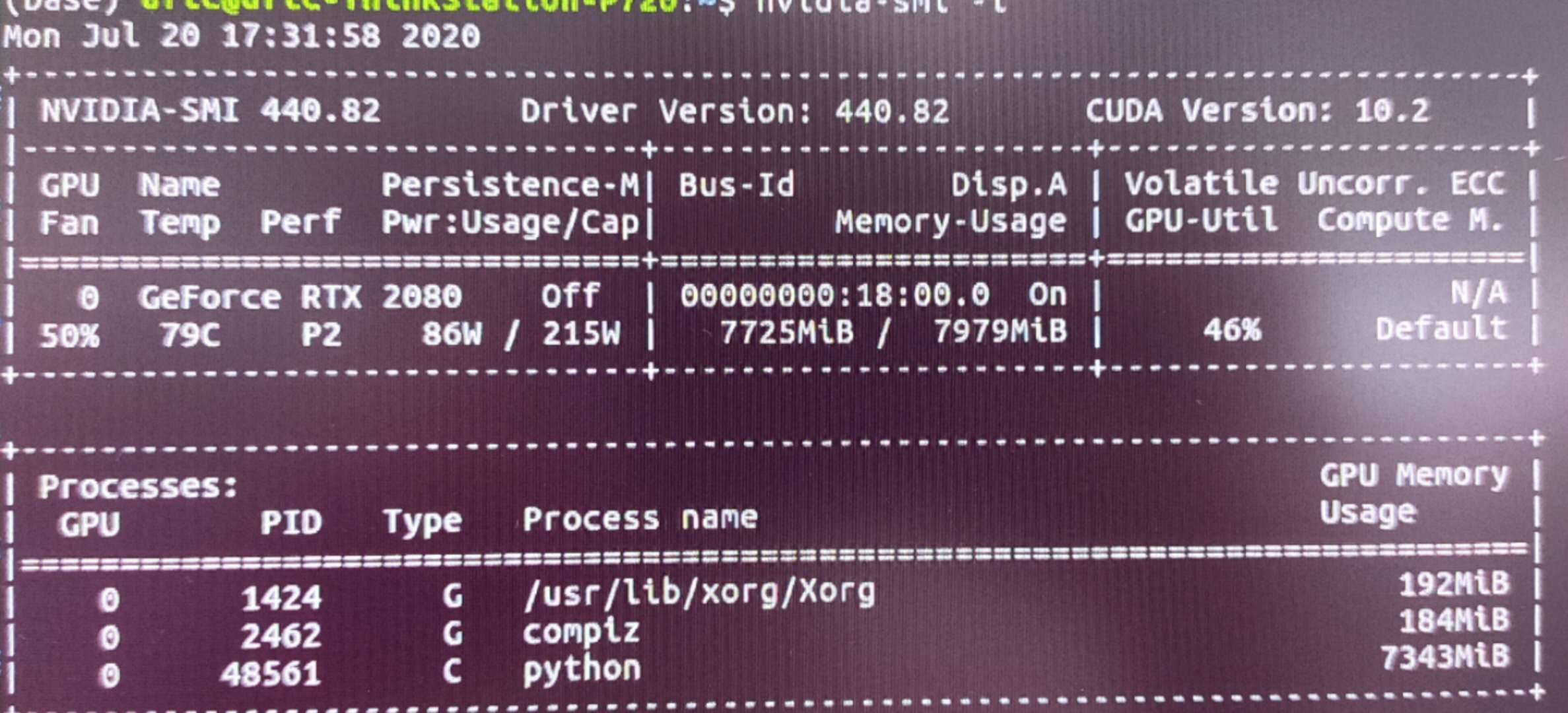
在我的训练中,成功启动cuda后,速度提升了10倍。
问题二:
Could not get lock /var/lib/apt/lists/lock - open (11: Resource temporarily unavailable)
解决方法:
参考链接:https://blog.csdn.net/u010098331/article/details/50782178
问题三:
Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
解决方法:
参考链接:
https://blog.csdn.net/weixin_43820996/article/details/102906434
https://blog.csdn.net/tsyccnh/article/details/102938368

 浙公网安备 33010602011771号
浙公网安备 33010602011771号