
mysql 窗口函数(Window Functions)
MySQL 窗口函数(Window Functions)是一种高级的 SQL 查询技巧,它允许在结果集的一组相关行上执行计算。窗口函数可以用于处理分组、排序、累计等复杂的聚合任务,使得查询更加简洁和高效。在 MySQL 8.0 及更高版本中,支持窗口函数。
以下是一些常用的窗口函数:
- ROW_NUMBER():为结果集中的每一行分配一个唯一的整数序号。
- RANK():为结果集中的每一行分配一个唯一的整数序号,但在具有相同值的行中使用相同的序号。在下一个序号时,会跳过重复的序号。
- DENSE_RANK():与 RANK() 类似,但不会跳过重复的序号。
- NTILE(N):将结果集分成 N 个组,并为每一行分配一个组号。
- CUME_DIST():计算当前行在结果集中的累计分布。
- PERCENT_RANK():计算当前行在结果集中的百分比排名。
- LEAD():获取当前行后面的第 N 行的值。
- LAG():获取当前行前面的第 N 行的值。
- FIRST_VALUE():获取窗口中的第一行的值。
- LAST_VALUE():获取窗口中的最后一行的值。
- NTH_VALUE():获取窗口中的第 N 行的值。
使用窗口函数时,需要定义一个窗口(OVER 子句),它描述了如何为每一行定义相关的行集。窗口定义通常包括以下部分:
- PARTITION BY:按给定的列或表达式对结果集进行分区。每个分区将被视为一个独立的窗口,窗口函数会在每个分区上分别计算。
- ORDER BY:定义窗口内行的排序顺序。
- ROWS/RANGE:定义窗口的大小和形状。ROWS 基于行数,RANGE 基于值范围。
PARTITION BY
PARTITION BY 在窗口函数中的作用类似于分组。它用于将结果集划分为多个分区,以便在每个分区内单独进行窗口函数的计算。通过使用 PARTITION BY 子句,您可以在每个分区内独立地应用窗口函数,而不是在整个结果集中应用。
在很多情况下,PARTITION BY 子句非常有用。例如,当您需要对每个部门的员工进行排名时,可以使用 PARTITION BY 根据部门对员工进行分组,然后在每个部门内应用窗口函数(如 RANK() 或 ROW_NUMBER())。
下面是一个使用 PARTITION BY 的示例:
准备数据

-- 创建 employees 表 CREATE TABLE employees ( employee_id INT PRIMARY KEY AUTO_INCREMENT, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, salary DECIMAL(10, 2) NOT NULL, department_id INT NOT NULL ); -- 插入示例数据 INSERT INTO employees (first_name, last_name, salary, department_id) VALUES ('John', 'Doe', 5000.00, 1), ('Jane', 'Smith', 5500.00, 1), ('Mike', 'Brown', 6000.00, 2), ('Emily', 'Johnson', 6500.00, 2), ('Tom', 'Davis', 7000.00, 3), ('Nina', 'Taylor', 5500.00, 3), ('Sophia', 'Lee', 6000.00, 4), ('Daniel', 'Miller', 5800.00, 4); -- 查询刚刚插入的数据 SELECT * FROM employees;
示例
SELECT department_id, first_name, last_name, salary, RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS rank_within_department FROM employees;
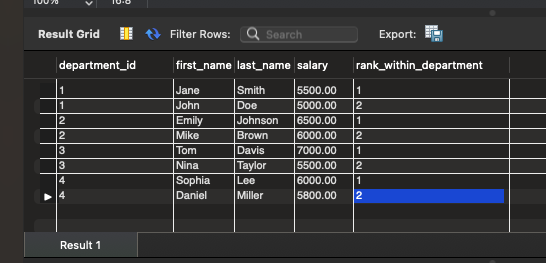
在这个示例中,我们使用 RANK()函数为每个部门的员工分配工资排名。通过在窗口定义中包含 PARTITION BY department_id子句,我们确保了在每个部门内部进行排名计算。
窗口范围
窗口范围(Window Frame)是窗口函数中的一个概念,用于定义在计算窗口函数时所使用的行集合。窗口范围可以限制窗口函数的作用范围,从而影响计算结果。通常,窗口范围是通过 ROWS BETWEEN 或 RANGE BETWEEN 子句定义的。
以下是一些常见的窗口范围类型:
- ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
这个窗口范围包括从分区的第一行到当前行的所有行。在计算窗口函数时,将使用这些行。
- ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
这个窗口范围包括从当前行到分区的最后一行的所有行。在计算窗口函数时,将使用这些行。
- ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
这个窗口范围包括分区中的所有行。在计算窗口函数时,将使用这些行。
- ROWS BETWEEN N PRECEDING AND M FOLLOWING
这个窗口范围包括从当前行向前 N 行(不包括当前行)到当前行向后 M 行(不包括当前行)的所有行。在计算窗口函数时,将使用这些行。
注意:在使用 RANGE BETWEEN 子句时,窗口范围是基于与当前行具有相同排序值的所有行来确定的。这可能导致不同的行数被包括在窗口范围内,具体取决于排序值的重复情况。
下面是一个使用窗口范围的示例:
-- 计算员工的累积工资(包括当前员工和之前的员工) SELECT employee_id, first_name, last_name, salary, SUM(salary) OVER (ORDER BY employee_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_salary FROM employees;
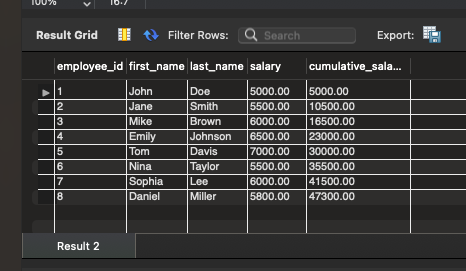
在此示例中,我们使用 SUM()窗口函数计算每个部门员工的累积工资。通过定义窗口范围为 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,我们确保了在计算累积工资时只考虑从分区开始到当前行的所有行。
讲下,rank(),row_number(),dense_rank(),三者之间的区别
准备数据
-- 创建 employees 表 CREATE TABLE employees ( employee_id INT PRIMARY KEY AUTO_INCREMENT, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, salary DECIMAL(10, 2) NOT NULL, department_id INT ); -- 插入示例数据 INSERT INTO employees (first_name, last_name, salary, department_id) VALUES ('John', 'Doe', 5000.00, 1), ('Jane', 'Smith', 5500.00, 1), ('Mike', 'Brown', 6000.00, 2), ('Emily', 'Johnson', 6500.00, 2), ('Tom', 'Davis', 7000.00, 3), ('Nina', 'Taylor', 5500.00, 3), ('Sophia', 'Lee', 6000.00, 4), ('Daniel', 'Miller', 5800.00, 4); -- 查询刚刚插入的数据 SELECT * FROM employees;
以下是每个窗口函数的示例,均使用 employees 表作为示例数据表。employees 表包含以下字段:employee_id(员工 ID)、first_name(名)、last_name(姓)、salary(工资)、department_id(部门 ID)。
-- ROW_NUMBER() -- 为每个员工分配一个唯一的序号,按工资降序排列 SELECT employee_id, first_name, last_name, salary, ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_number FROM employees; -- RANK() -- 为每个员工分配一个序号,具有相同工资的员工将获得相同的序号,按工资降序排列 SELECT employee_id, first_name, last_name, salary, RANK() OVER (ORDER BY salary DESC) AS rank FROM employees; -- DENSE_RANK() -- 与 RANK() 类似,但不会跳过重复的序号 SELECT employee_id, first_name, last_name, salary, DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank FROM employees;
ROW_NUMBER()
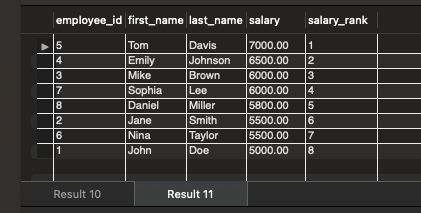
RANK()
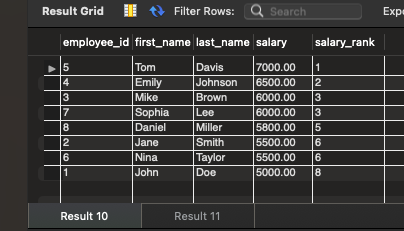
DENSE_RANK()
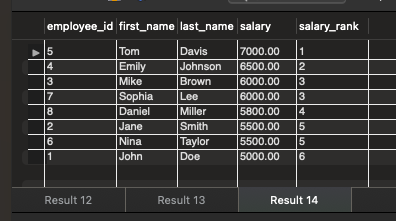
-- 知识点:row_number(),rank(),dense_rank()的区别
-- (1) row_number():依次排序,不会出现相同排名
-- (2) rank():出现相同排名时,跳跃排序
-- (3) dense_rank(): 出现相同排名时,连续排序


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律