物体检测丨Faster R-CNN详解
这篇文章把Faster R-CNN的原理和实现阐述得非常清楚,于是我在读的时候顺便把他翻译成了中文,如果有错误的地方请大家指出。
原文:http://www.telesens.co/2018/03/11/object-detection-and-classification-using-r-cnns/
在这篇文章中,我将详细描述最近引入的基于深度学习的对象检测和分类方法,R-CNN(Regions with CNN features)是如何工作的。事实证明,R-CNN在检测和分类自然图像中的物体方面非常有效,其mAP远高于之前的方法。R-CNN方法在Ross Girshick等人的以下系列论文中描述。
- R-CNN( https://arxiv.org/abs/1311.2524 )
- Fast R-CNN( https://arxiv.org/abs/1504.08083 )
- Faster R-CNN( https://arxiv.org/abs/1506.01497 )
这篇文章描述了最后一篇论文中R-CNN方法的最终版本。我首先考虑介绍该方法从第一次引入到最终版本的演变,然而事实表明这是一项伟大的事业。我决定详细描述最终版本。
幸运的是,在TensorFlow,PyTorch和其他机器学习库中,网上有许多R-CNN算法的实现。我使用了以下实现:
https://github.com/ruotianluo/pytorch-faster-rcnn
本文中使用的大部分术语(例如,不同层的名称)遵循代码中使用的术语。
理解本文中提供的信息应该可以更容易地遵循PyTorch实现并进行自己的修改。
1. 文章组织
-
第1部分 - 图像预处理:在本节中,我们将描述应用于输入图像的预处理步骤。这些步骤包括减去平均像素值和缩放图像。训练和推理之间的预处理步骤必须相同。
-
第2节 - 网络组织:在本节中,我们将描述网络的三个主要组成部分 —
“head”network,region proposal network(RPN)和分类网络。
-
第3节 - 实现细节(训练):这是该文章最长的部分,详细描述了训练R-CNN网络所涉及的步骤。
-
第4节 - 实现细节(推理):在本节中,我们将描述在推理过程涉及的步骤,使用训练好的R-CNN网络来识别有希望的区域并对这些区域中的对象进行分类。
-
附录:这里我们将介绍R-CNN运行过程中一些常用算法的细节,如非极大值抑制和Resnet50架构的细节。
2. 图像预处理
在将图像送入网络之前,以下预处理步骤需要应用于图像。对于训练和测试,这些步骤必须相同。平均向量(\(3\times 1\),每个数值对应于每个颜色通道)不是当前图像中像素值的平均值,而是对所有训练和测试图像都相同的配置值。
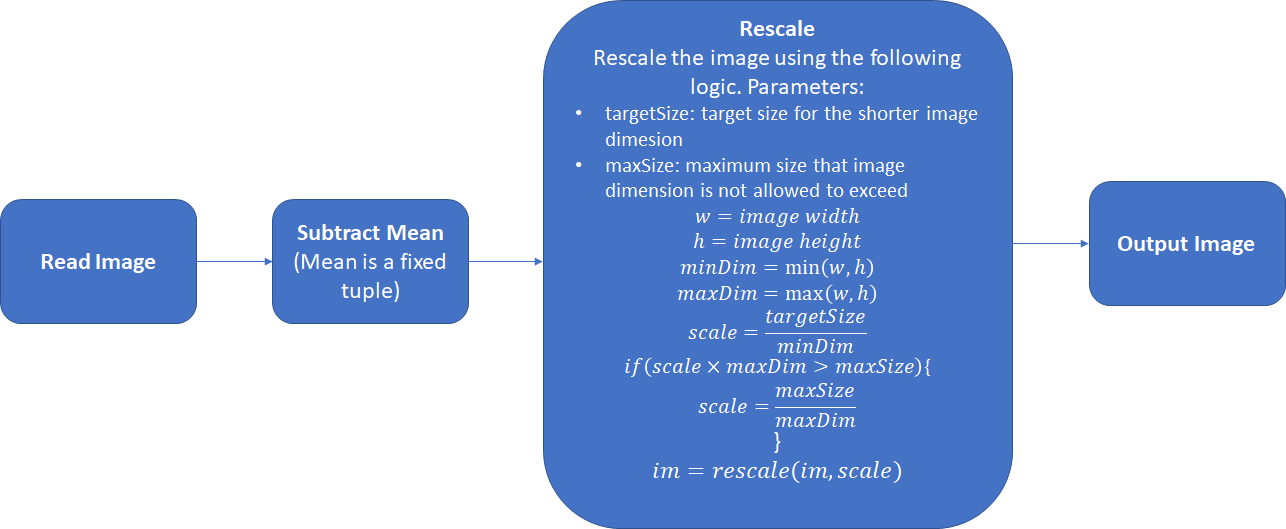
\(targetSize\)和\(maxSize\)的默认值分别是600和1000。
3. 网络组织
RCNN用神经网络来解决两个主要的问题:
- 在输入图像中识别可能包含前景对象的区域(Region of Interest—RoI)。
- 计算每个RoI的对象类概率分布—如计算RoI包含特定类对象的概率,然后用户可以选择概率最高的对象类作为分类结果。
RCNN包含三种主要网络:
- Head
- Region Proposal Network(RPN)
- Classification Network
R-CNN使用预训练网络如ResNet50的前几层来识别输入图像的特征。在一个数据集上使用针对不同问题的网络是可能的,因为神经网络显示可以“迁移学习”(https://arxiv.org/abs/1411.1792)。
网络的前几层学习检测一般特征,如边缘和颜色斑点,这些特征在许多不同的问题上都是很好的识别特征。后一层学习到的特征是更高层次、更具体的问题特征。这些层既可以被移除,也可以在反向传播期间微调这些层的权重。从预训练网络初始化的前几层构成“head”网络。然后,由head网络生成的feature map通过Region Proposal Network(RPN),该网络使用一系列卷积和全连接层来生成可能包含前景对象的ROI(上述问题1)。然后使用这些有可能的ROI从head网络产生的feature map中裁剪出相应的区域。这称为“Crop Pooling”。然后,通过crop Pooling产生的区域通过分类网络,该分类网络学习对每个ROI中包含的对象分类。
另外,你可能会注意到ResNet的权重以奇怪的方式初始化:
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
如果您有兴趣了解此方法的工作原理,请阅读我关于初始化卷积和完全连接层的权重的文章。
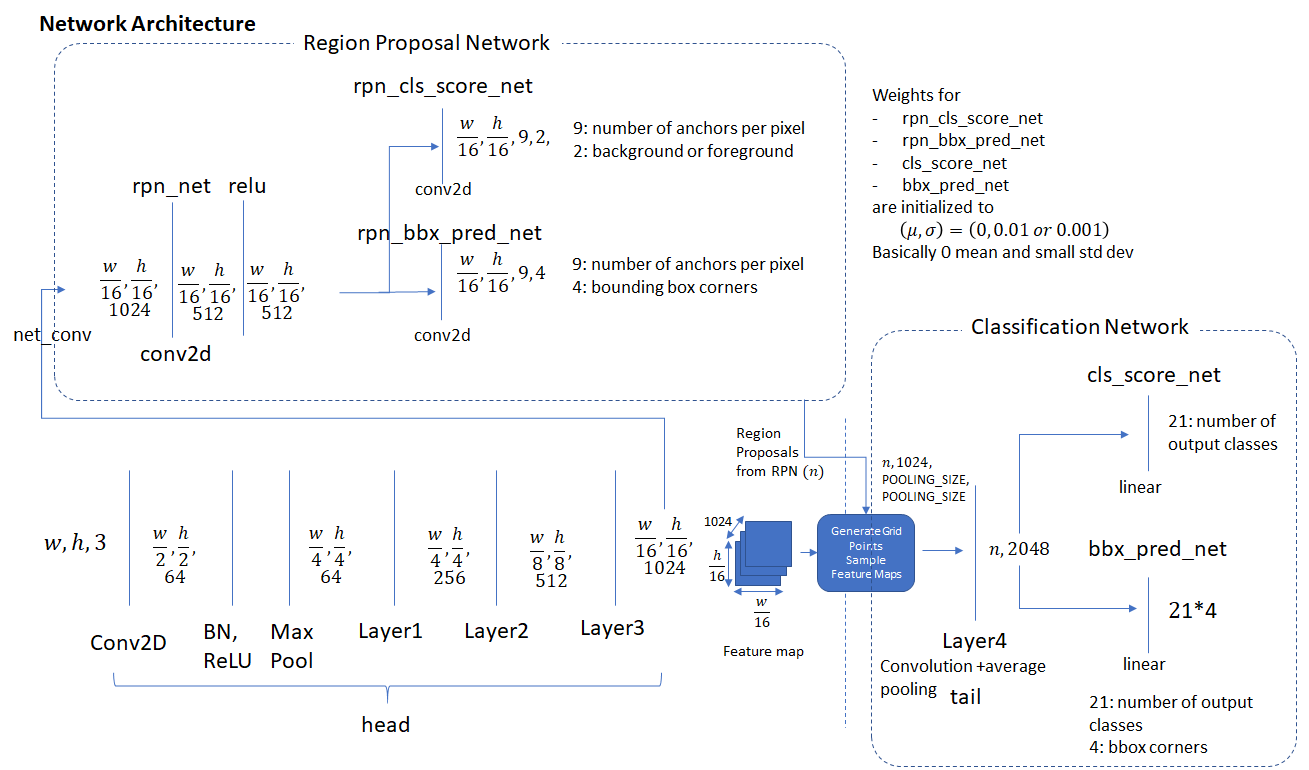
3.1. 网络架构
下图显示了上述三种网络类型的各个组件。我们展示了每个网络层的输入和输出的维度,这有助于理解网络的每个层如何转换数据。并表示输入图像的宽度和高度(在预处理之后)。
4. 实现细节:Training
在本节中,我们将详细描述训练R-CNN所涉及的步骤。一旦了解了训练的工作原理,理解推理就会轻松得多,因为它只是简单地使用了训练中涉及的一部分步骤。训练的目标是调整RPN和分类网络中的权重并微调head网络的权重(这些权重从预训练的网络如ResNet初始化)。回想一下,RPN网络的任务是产生有前景的ROI而分类网络的任务是为每个ROI分配对象类分数。因此,为了训练这些网络,我们需要相应的ground truth,图像中对象周围bounding boxes的坐标和这些对象的类。这些ground truth来自开源的图像数据库,每个图像附带一个注释文件。此注释文件包含bounding box的坐标和图像中每个对象的对象类标签(对象类来自预定义对象类的列表)。这些图像数据库已被用于支持各种对象分类和检测挑战。两个常用的数据库是:
- PASCAL VOC:VOC 2007数据库包含9963张训练/验证/测试图像,包含20个对象类别的24,640个注释。
- 人:人
- 动物:鸟,猫,牛,狗,马,羊
- 交通工具:飞机,自行车,船,巴士,汽车,摩托车,火车
- 室内:瓶,椅子,餐桌,盆栽,沙发,电视/显示器

- COCO(Common Objects in Context):COCO数据集要大得多。它包含> 200K标记图像,包含90个对象类别。
我使用较小的PASCAL VOC 2007数据集进行训练。R-CNN能够在同一步骤中训练region proposal网络和分类网络。
让我们花一点时间来回顾一下本文其余部分广泛使用的“bounding box 回归系数”和“bounding box 重叠”的概念。
-
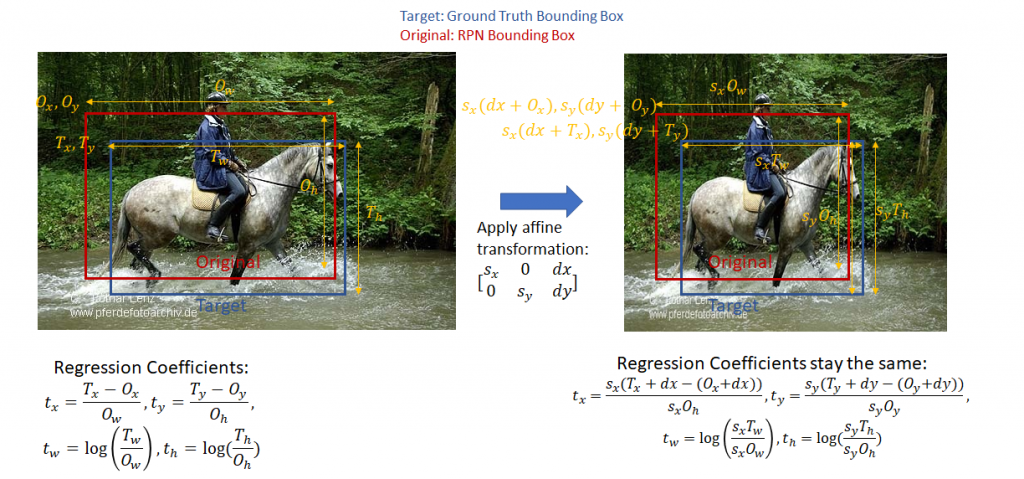
bounding box 回归系数(也称为“回归系数”和“回归目标”):R-CNN的目标之一是生产与对象边界紧密匹配的良好bounding boxes。R-CNN通过采用给定的bounding boxes(由左上角的坐标,宽度和高度定义)并通过应用一组“回归系数”来调整其左上角,宽度和高度来生成这些bounding boxes。这些系数计算如下(Appendix C of (https://arxiv.org/pdf/1311.2524.pdf))。让目标和原始bounding box的左上角的x,y坐标分别表示为\(T_x,T_y,O_x,O_y\)并且目标和原始bounding box宽度/高度表示为\(T_w,T_h,O_w,O_h\)然后,回归目标(将原始bounding box转换为target box的函数系数)给出如下:
-
\(t_x = \frac{T_x-O_x}{O_w},t_y=\frac{T_y-O_y}{O_h},t_w=log(\frac{T_w}{O_w}),t_h=log(\frac{T_h}{O_h})\)。
该函数很容易转换,即给定回归系数和左上角的坐标以及原始bounding box的宽度和高度,可以容易地计算目标框的左上角和宽度和高度。注意,回归系数对无剪切的仿射变换是不变的。这是一个重要的点,因为在计算分类损失时,目标回归系数是按原始纵横比计算的,而分类网络输出的回归系数则是在ROI pooling步骤之后的正方形的feature map上计算出来的。当我们在下面讨论分类损失时,这将变得更清楚。
-
-
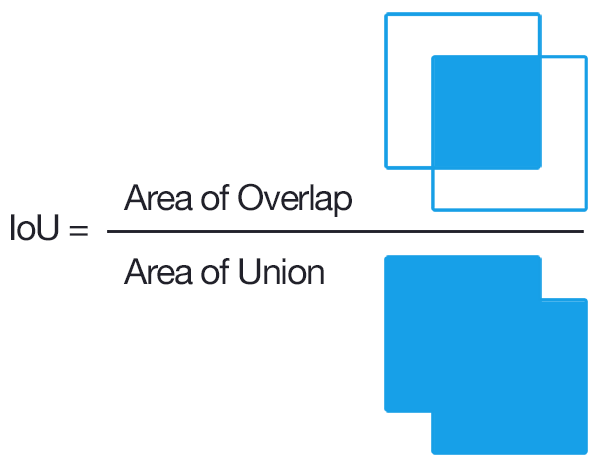
交互比(IoU)的重叠:我们需要测量给定bounding box与另一个bounding box的接近程度,该bounding boxes与所使用的单位(像素等)无关,以测量bounding boxes的尺寸。该度量应该是直观的(两个重合的bounding boxes overlap应该为1,并且两个不重叠的boxes overlap应该为0)并且快速且易于计算。常用的重叠度量是“交互比(IoU)重叠”,计算如下所示。
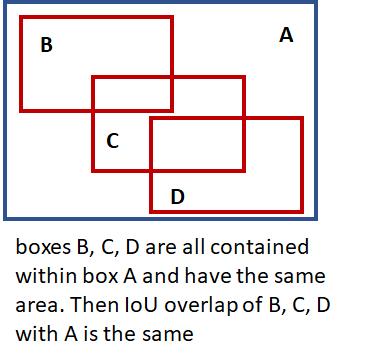
通过这些预备知识,现在让我们深入了解训练R-CNN的实现细节。在代码实现中,R-CNN执行分为几个层,如下所示。一个层封装了一系列逻辑步骤,这些步骤包括通过其中一个神经网络运行数据和其他步骤例如比较bounding boxes之间的重叠程度,执行非极大值抑制等。
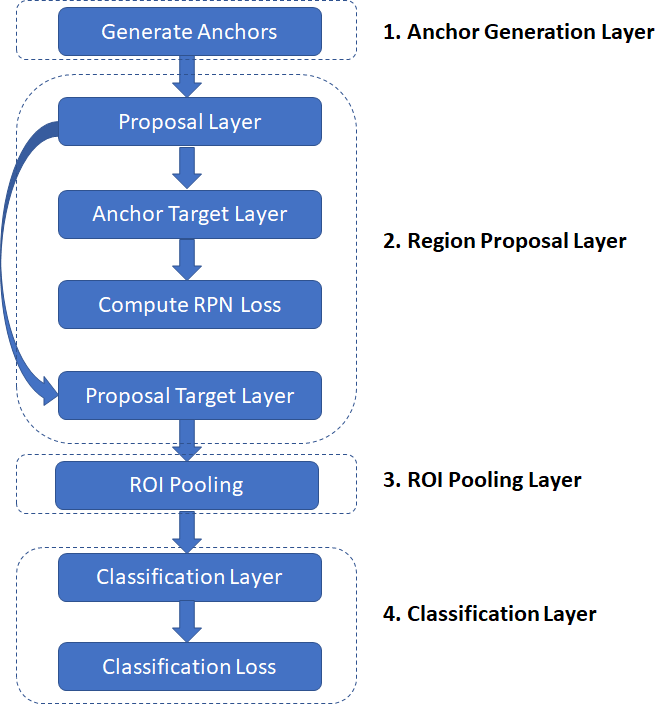
- Anchor Generation Layer:该层首先生成9种不同比例和纵横比的Anchor,然后通过跨越输入图像均匀间隔的网格点平移它们来复制这些Anchor,从而生成固定数量的“Anchor”(bouding boxes)。
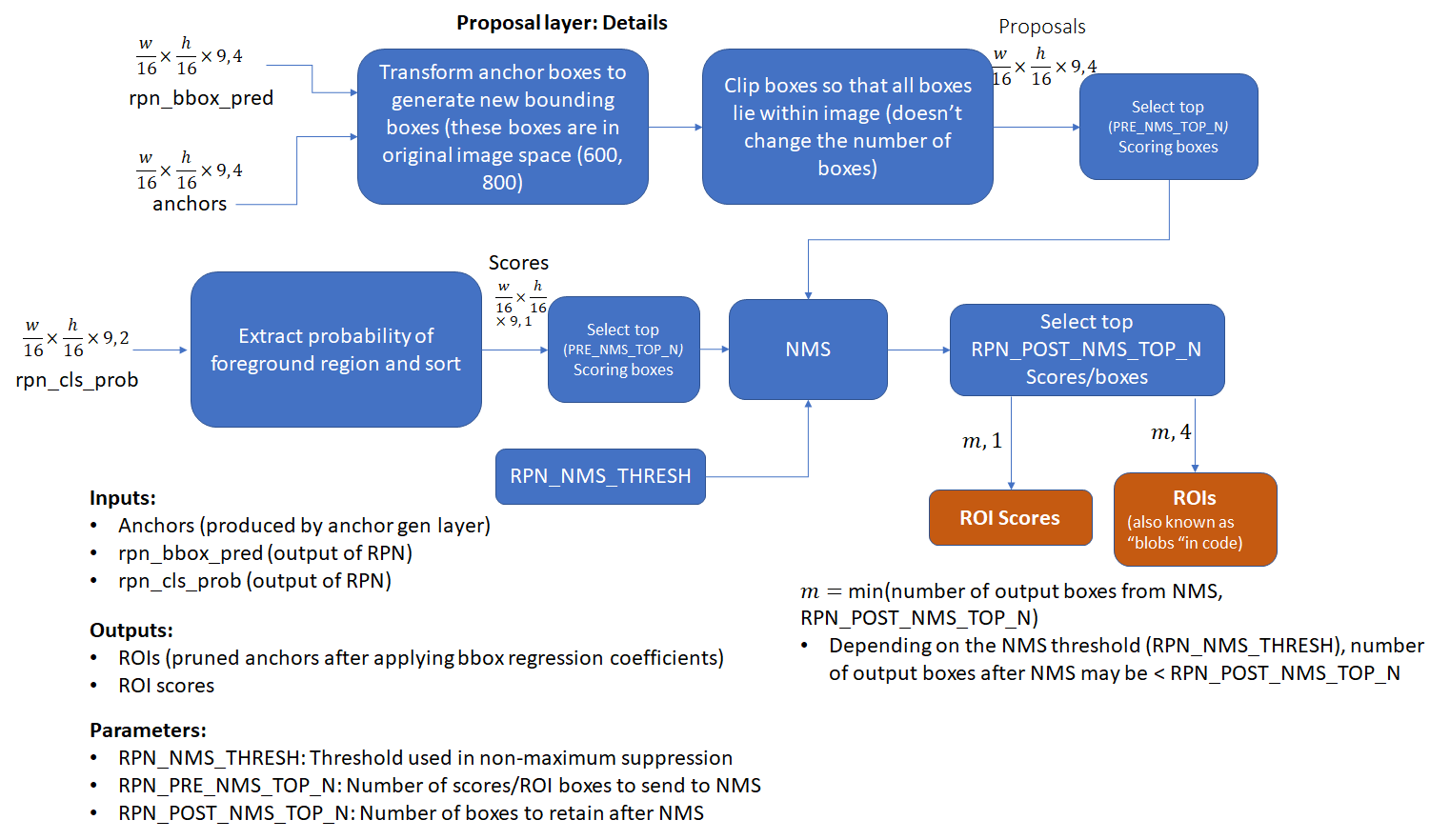
- Proposal Layer:根据bounding boxes回归系数转换anchor以生成转换后的anchors。然后利用anchor作为前景的概率应用非极大值抑制(参见附录)来修剪anchor的数量。
- Anchor Target Layer:anchor target layer的目标是生成一组“好”的anchors和相应的前景/背景标签和目标回归系数来训练Region Proposal Network。该层的输出仅用于训练RPN网络,并且不被分类层使用。给定一组anchors(由anchor generation layer生成,anchor target layer识别有希望的前景和背景anchors。有希望的前景anchors是值与某些ground truth box重叠程度超过阈值。背景框是与任何重叠的ground truth box低于阈值。anchor target layer还输出一组bounding boxes回归量,即每个anchor目标离最近的bounding box有多远的度量。这些回归量只对前景框有意义,因为背景框没有“最近的bounding box”的概念。
- RPN Loss:RPN损失函数是在优化过程中最小化以训练RPN网络的指标。损失函数是以下组合:
- RPN生成的bounding boxes被正确分类为前景/背景的比例。
- 预测和目标回归系数之间的距离度量。
- Proposal Target Layer:proposal target layer的目标是修剪proposal layer生成的anchor列表,并生成特定类的bounding box回归目标,可用于训练分类层以生成良好的类别标签和回归目标
- ROI Pooling Layer:实现空间转换的网络,在给定proposal target layer生成的region proposals的bounding boxes坐标的情况下对输入feature map进行采样。这些坐标通常不在整数边界上,因此需要基于插值的采样。
- Classification Layer:分类层采用ROI Pooling Layer生成的输出feature maps,并将它们传递给一系列卷积层。输出通过两个全连接层。第一层为每个region proposal生成类概率分布,第二层生成一组特定类的bounding boxes回归量。
- Classification Loss:类似于RPN损,分类损失是在优化过程中最小化以训练分类网络的指标。在反向传播期间,误差梯度也流向RPN网络,因此训练分类层也会修改RPN网络的权重。我们稍后会谈到这一点。分类损失是以下组合:
- RPN生成的bounding boxes被正确分类的比例(作为正确的对象类)。
- 预测和目标回归系数之间的距离度量。
我们现在将详细介绍这些层中的每一层。
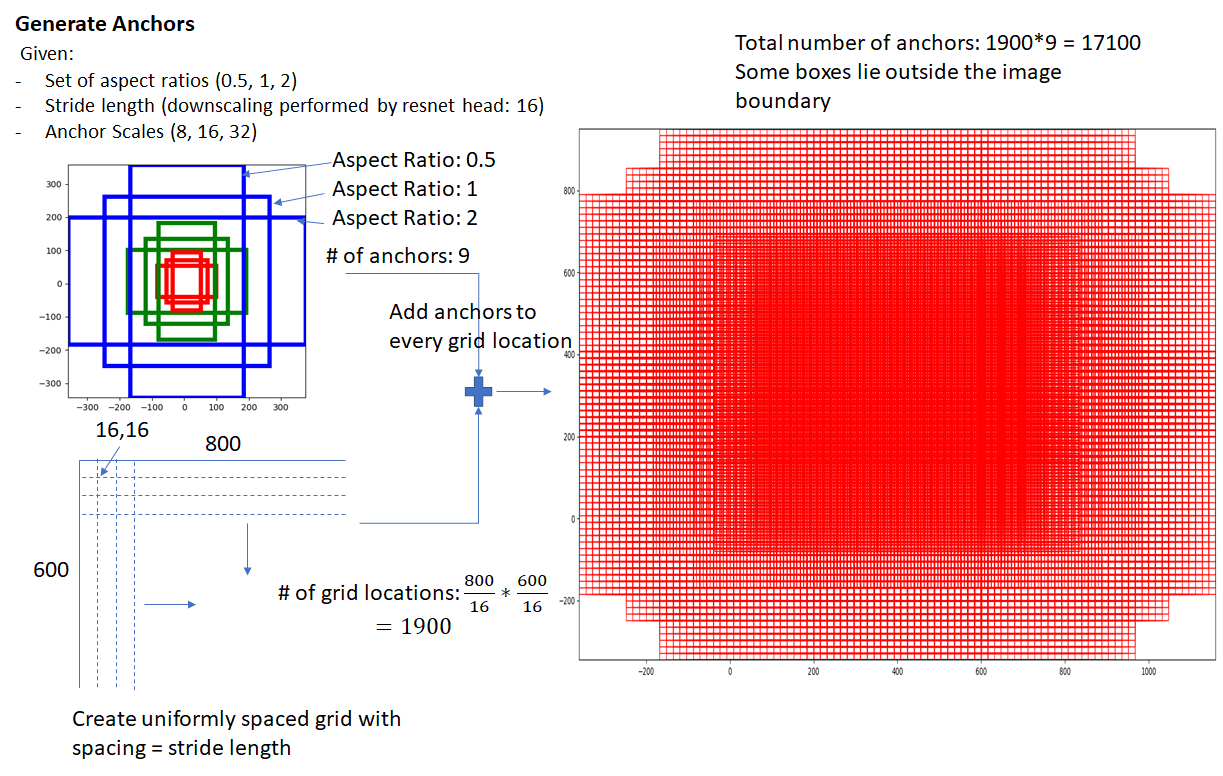
4.1. Anchor Generation Layer
anchor generation layer生成一组大小和纵横比不同的bounding boxes(称为“anchor boxes”),分布在输入图像上。这些bounding boxes对于所有图像是相同的,即它们不知道图像的内容。这些bounding boxes中的一些将包围前景对象,而大多数不会。RPN网络的目标是学习识别哪些框是好框 —即可能包含前景对象,并产生目标回归系数,当应用于anchor box时,将anchor box转换为更好的bounding boxes (更紧密地拟合所包含的前景对象)。
下图演示了如何生成这些anchor boxes。
4.2. Region Proposal Layer
物体检测方法需要一个“region proposal system”作为输入,它产生一组稀疏(例如seletive search(http://link.springer.com/article/10.1007/s11263-013-0620-5))或密集(例如在deformable part models( https://doi.org/10.1109/TPAMI.2009.167 “)中使用的特征)一组特征。R-CNN系统的第一个版本使用seletive search方法来生成region proposal。在当前版本(称为“Faster R-CNN”)中,使用基于“sliding window”的技术(在前一部分中描述)来生成一组密集候选区域,然后使用神经网络驱动的proposal network网络。根据region包含前景对象的概率对region proposals进行排名。region proposal layer有两个目标:
- 从anchors列表中识别背景和前景anchors。
- 通过应用一组“回归系数”来修改anchors的位置,宽度和高度,以提高anchors的质量(例如,使它们更好地适应对象的边界。
region proposal layer由Region Proposal Network和三个层组成 —Poposal Layer,Anchor Target Layer和Proposal Target Layer。以下各节将详细介绍这三层。
4.2.1. Region Proposal Network
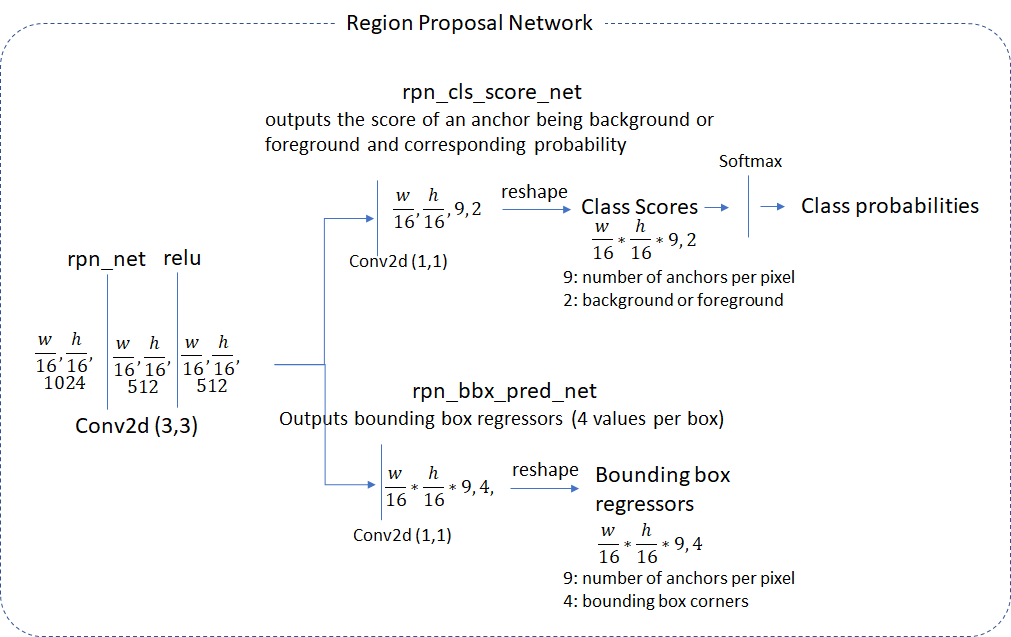
region proposal layer通过卷积层(代码中称为rpn_net)处理head网络生成的feature map,然后接着RELU。rpn_net的输出通过两个(1,1)卷积层运行,以产生背景/前景类分数和概率以及相应的bounding boxes回归系数。head网络的步长与生成anchor时使用的步长相匹配,因此anchor的数量与region proposal network产生的信息一一对应(anchor boxes数量 = 类别得分数 = bounding boxes回归系数的数量 = \(\frac{w}{16}\times\frac{h}{16}\times9\))
4.3. Proposal Layer
proposal layer采用anchor generation layer生成的anchor boxes,并通过基于前景分数应用非极大值抑制来修剪框数(有关详细信息,请参阅附录)。它还通过将RPN生成的回归系数应用于相应的anchor boxes来生成变换的bounding boxes。
4.4. Anchor Target Layer
anchor target layer的目标是选择可用于训练RPN网络的有希望的anchor:
- 区分前景区域和背景区域,
- 并为前景框生成良好的bounding boxes回归系数。
首先看一下如何计算RPN损失是很有用的。这将揭示计算RPN损失所需的信息,这使得易于遵循Anchor Target Layer的操作。
4.4.1. 计算RPN Loss
请记住,RPN层的目标是生成良好的bounding boxes。要从一组anchor boxes中执行此操作,RPN层必须学会将anchor box分类为背景或前景,并计算回归系数以修改前景anchor box的位置,宽度和高度,使其成为“更好”的前景框(更贴近前景对象)。RPN Loss的制定方式是鼓励网络学习这种行为。
RPN损失是分类损失和bounding box回归损失的总和。分类损失使用交叉熵损失惩罚错误分类的框,回归损失使用真实回归系数之间的距离函数(使用前景anchor最近匹配的ground truth计算)和网络预测的回归系数 (参见RPN网络架构图中的rpn_bbx_pred_net)。
分类损失:
cross_entropy(predicted_class,actual_class)
bounding boxes回归损失:
\(L_ {loc} = \ sum_{u \in all}foreground \ anchors \ l_u\)
对所有前景anchor的回归损失求和。为背景anchor执行此操作没有意义,因为背景anchor没有关联的ground truth。
\(l_u=\sum_{i\in x,y,w,h}smooth_{L1}(u_i(predicted)-u_i(target))\)
这显示了如何计算给定前景anchor的回归损失。我们采用预测(通过RPN)和目标(使用离anchor box最接近的ground truth box)的回归系数之间的差异。有四个组件—对应于左上角的坐标和bounding boxes的宽度/高度。smooth L1函数定义如下:
\(smooth_{L1}=\begin{cases} \frac{\sigma^2x^2}{2}&||x||\lt\frac{1}{\sigma^2}\\||x||-\frac{0.5}{\sigma^2}&otherwise\end{cases}\)
这里\(\sigma\)是任意选择的(在我的代码中设置为3)。请注意,在python实现中,前景anchor的mask数组(称为bbox_inside_weights)用于计算作为向量操作的损失并避免for-if循环。
因此,要计算损失,我们需要计算以下数值:
- 类标签(背景或前景)和anchor boxes的分数
- 前景anchor boxes的目标回归系数
我们现在将遵循anchor target layer的实现,以查看这些数值的计算方式。我们首先选择位于图像范围内的anchor boxes。然后,首先计算所有anchor boxes(在图像内)与所有ground truth的IoU重叠来选择好的前景框。使用此重叠信息,两种类型的框被标记为前景:
- 类型A:对于每个ground truth box,所有与ground truth box具有最大IoU重叠的前景框。
- 类型B:与某些ground truth box的最大重叠超过阈值的Anchor boxes。
这些框显示在下图中:
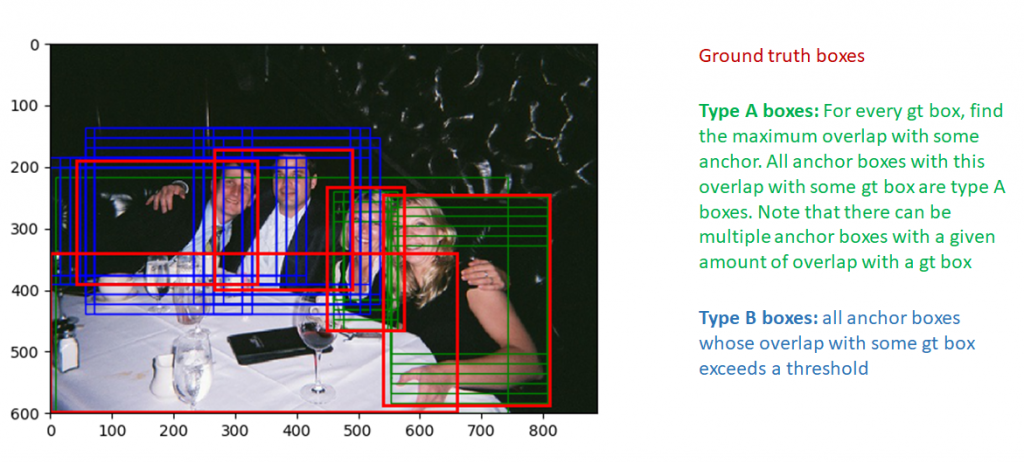
注意,仅选择与某些ground truth重叠超过阈值的anchor box作为前景框。这样做是为了避免向RPN提供“不可能的学习任务”即学习离最佳匹配ground truth box太远的回归系数。类似地,重叠小于负阈值的框被标记为背景框。并非所有不是前景框的框都标记为背景。既不是前景也不是背景的框被标记为“不关心”。这些框不包括在RPN损失的计算中。
有两个额外的阈值与我们想要实现的背景和前景框的总数相关,以及应该是前景的这个数字的分数。如果通过测试的前景框数超过阈值,我们会将多余的前景框随机标记为“不关心”。类似的逻辑应用于背景框。
接下来,我们计算前景框和相应ground truth之间的bounding box回归系数,最大重叠。这很容易,只需要按照公式计算回归系数。
这结束了我们对anchor target layer的讨论。回顾一下,让我们列出该层的参数和输入/输出:
参数:
TRAIN.RPN_POSITIVE_OVERLAP:用于选择anchor box是否为良好前景框的阈值(默认值:0.7)TRAIN.RPN_NEGATIVE_OVERLAP:如果anchor与groud truth的最大重叠低于此阈值,则将其标记为背景。重叠>RPN_NEGATIVE_OVERLAP但<RPN_POSITIVE_OVERLAP的框被标记为“不关心”。(默认值:0.3)TRAIN.RPN_BATCHSIZE:背景和前景anchor的总数(默认值:256)TRAIN.RPN_FG_FRACTION:batch size中前景anchor的比例(默认值:0.5)。
如果找到的前景anchors大于TRAIN.RPN_BATCHSIZE\(\times\)TRAIN.RPN_FG_FRACTION,则超出(索引是随机选择的)标记为“不关心”。
输入:
- RPN网络输出(预测的前景/背景类标签,回归系数)
- Anchor boxes(由anchor generation layer生成)
- Ground truth boxes
输出:
- 良好的前景/背景框和相关的类标签
- 目标回归系数
其他层,proposal target layer, ROI Pooling layer和分类层用于生成计算分类损失所需的信息。正如我们对anchor target layer所做的那样,让我们首先看一下如何计算分类损失以及计算分类损失需要哪些信息。
4.5. 计算分类层Loss
与RPN损失类似,分类层损失有两个组成部分— 分类损失和bounding box回归损失
RPN层和分类层之间的关键区别在于,虽然RPN层只处理两个类—前景和背景,但分类层处理我们网络用于训练分类的所有对象类(加上背景)。
分类损失是以实际对象类别和预测类别得分为参数的交叉熵损失。它的计算方法如下所示。


bounding boxes回归损失也与RPN类似地计算,除了现在回归系数是类特定的。
网络计算每个对象类的回归系数。目标回归系数显然仅适用于正确的类,该类是与给定anchor具有最大重叠的ground truth的bounding boxes的对象类。
在计算损失时,使用mask数组,该mask数组标记每个anchor的正确对象类。忽略不正确的对象类的回归系数。该mask数组允许将损失计算转变为矩阵乘法,而不是需要for-each循环。
因此,需要以下数量来计算分类层损失:
- 预测类标签和bounding box回归系数(这些是分类网络的输出)
- 每个anchor的类标签
- 目标bounding boxes的回归系数
现在让我们看看这些数值在proposal target和分类层是如何计算的。
4.6. Proposal Target Layer
proposal tarrget layer的目标是从proposal layer的ROI列表中选择有希望的ROI。这些有希望的ROI将用于从head layer产生的feature map执行crop pooling并传递到网络的其余部分(head_to_tail),其计算预测的类别得分和框回归系数。
与anchor target layer类似,重要的是选择好的proposals(与gt框重叠的那些)以传递给分类层。否则,我们将要求分类层学习“无望的学习任务”。
proposal target layer以proposal layer计算的ROI开始。使用每个ROI与所有groud truth boxes的最大重叠,它将ROI分类为背景和前景ROI。前景ROI是最大重叠超过阈值的那些(TRAIN.FG_THRESH,默认值:0.5)。背景ROI是最大重叠落在TRAIN.BG_THRESH_LO和TRAIN.BG_THRESH_HI之间的值(默认值分别为0.1,0.5)。这是用于向分类器提供困难背景样本的“难例挖掘”的示例。
还有一些额外的逻辑试图确保前景和背景区域的总数是恒定的。如果找到的背景区域太少,它会尝试通过随机重复一些背景索引来填补批次,以弥补不足。
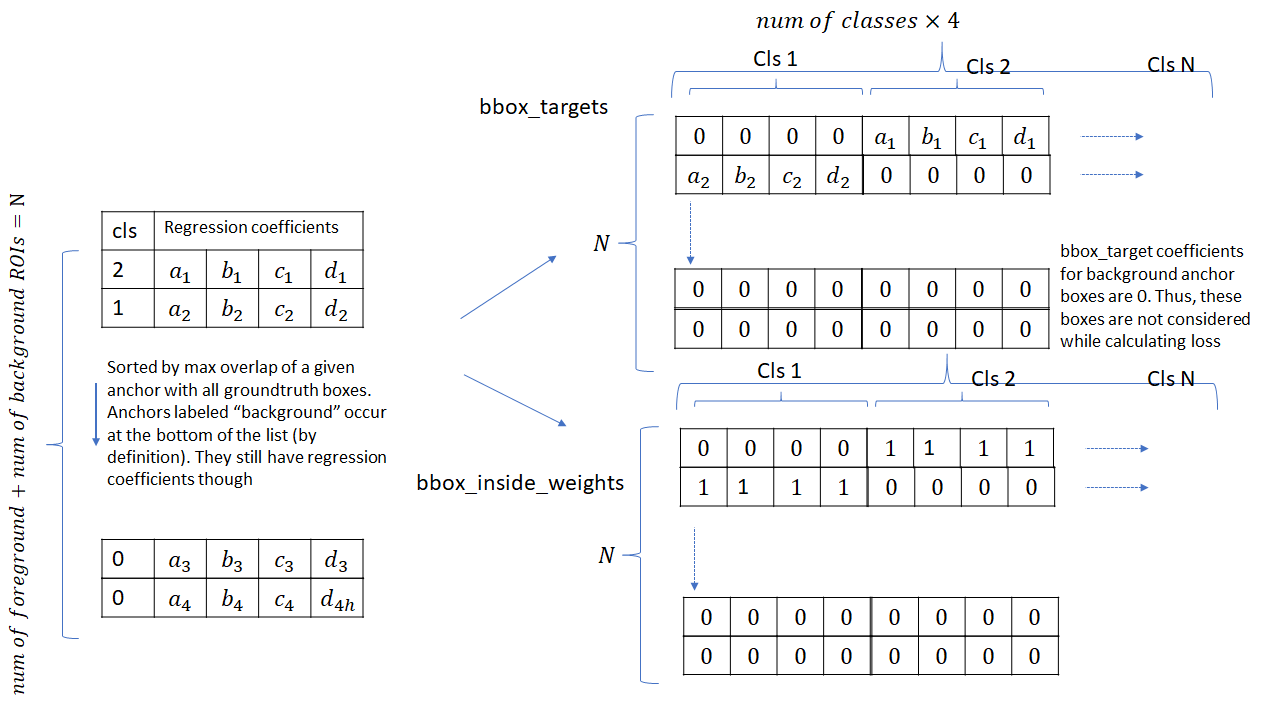
接下来,在每个ROI和最接近的匹配ground truth box之间计算bounding box目标回归目标(这也包括背景ROI,因为这些ROI也存在重叠的ground truth)。这些回归目标针对所有类进行了扩展,如下图所示。
输入:
- proposal layer生成的ROI
- ground truth信息
输出:
- 选择符合重叠标准的前景和背景ROI。
- ROI的类特定目标回归系数
参数:
TRAIN.FG_THRESH:(默认值:0.5)用于选择前景ROI。与ground truth最大重叠超过FG_THRESH的ROI标记为前景TRAIN.BG_THRESH_HI:(默认为0.5)TRAIN.BG_THRESH_LO:(默认为0.1)这两个阈值用于选择背景ROI。
最大重叠位于BG_THRESH_HI和BG_THRESH_LO之间的ROI标记为背景TRAIN.BATCH_SIZE:(默认为128)所选的前景和背景框的最大数量。TRAIN.FG_FRACTION:(默认为0.25)。
前景框的数量不能超过BATCH_SIZE * FG_FRACTION
4.7. Crop Pooling
Proposal tarrget layer为我们提供了有希望的ROI,以便在训练期间使用相关的类标签和回归系数进行分类。下一步是从head网络产生的卷积feature map中提取对应于这些ROI的区域。然后,提取的特征图通过网络的其余部分(上面所示的网络图中的“尾部”)运行,以产生每个ROI的对象类概率分布和回归系数。Crop Pooling层的工作是从卷积feature maps执行区域提取。
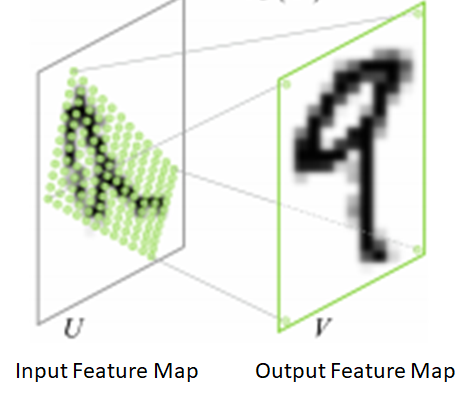
crop pooling的关键思想在关于“空间变换网络”(Anon.2016)*的论文中有所描述。目标是将warping函数(由\(2\times3\)的仿射变换矩阵描述)应用于输入feature map以输出warped feature map。如下图所示
crop pooling涉及两个步骤:
-
对于一组目标坐标,应用给定的仿射变换以生成源坐标。
\(\left[\begin{matrix}x^s_i\\y^s_i\end{matrix}\right]=\left[\begin{matrix}\theta_{11}&\theta_{12}&\theta_{13}\\\ \theta_{21}&\theta_{22}&\theta_{23}\end{matrix}\right]\left[\begin{matrix}x^t_t\\y^t_i\\1\end{matrix}\right]\)。其中\(x^s_i,y^s_i,x^t_i,y^t_i\)是高度/宽度标准化坐标(类似于图形中使用的纹理坐标),所以\(-1\leq x^s_i,y^s_i,x^t_i,y^t_i\leq1\)。
-
在第二步中,在源坐标处对输入(源)map进行采样以产生输出(目标)map。在此步骤中,每个\((x^s_i,y^s_i)\)坐标定义输入中的空间位置,其中应用采样内核(例如双线性采样内核)以获取输出feature map中特定像素的值。
空间变换中描述的采样方法提供了可微分的采样机制,允许损失梯度流回传feature map和采样网格坐标。
幸运的是,crop pooling在PyTorch中实现,API包含两个镜像这两个步骤的函数。torch.nn.functional.affine_grid采用仿射变换矩阵并生成一组采样坐标,并且torch.nn.functional.grid_sample对这些坐标处的网格进行采样。反向步骤中的反向传播梯度由pyTorch自动处理。
要使用裁剪池,我们需要执行以下操作:
-
将ROI坐标除以“头部”网络的步长。由proposal target layer产生的ROIs的坐标在原始图像空间(800$\times$600)中。为了将这些坐标代入由“head”产生的输出feature map的空间中,我们必须将它们除以步长(当前实现中的16)。
-
要使用上面显示的API,我们需要仿射变换矩阵。计算该仿射变换矩阵如下所示。
-
我们还需要目标特征图上的和点的数量。这由配置参数
cfg.POOLING_SIZE(默认为7)提供。因此,在crop pooling期间,非方形ROI用于从卷积特征图中裁剪出区域,这些区域被warped成恒定大小的方形窗口。当crop pooling的输出被传入进一步的卷积和全连接层,这种warping必须进行。
4.8. 分类层
crop pooling采用proposal target layer输出的ROI框和“head”网络输出的卷积feature maps,并输出方形feature maps。然后通过沿空间维度的aaverage pooling,将feature map传递到ResNet的layer 4。结果(代码中称为“fc7”)是每个ROI的一维特征向量。此过程如下所示。

然后,特征向量通过两个全连接—bbox_pred_net和cls_score_net。cls_score_net层为每个bounding box生成类别分数(可以通过应用softmax将其转换为概率)。bbox_pred_net层生成类特定的bounding box回归系数,该回归系数与proposal target layer产生的原始bounding box坐标组合以产生最终bounding box。这些步骤如下所示。
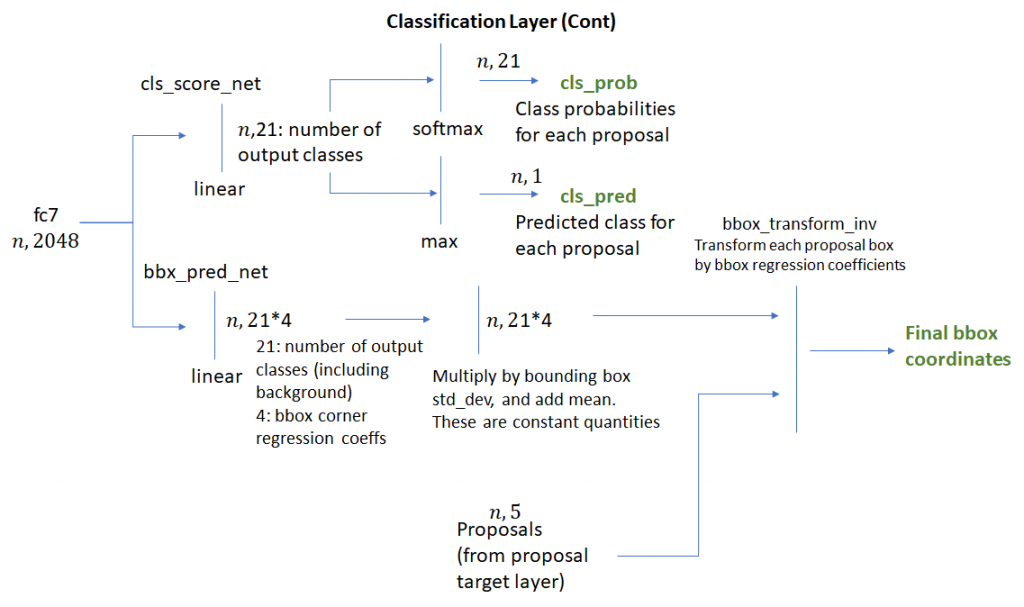
回想一下两组bounding box回归系数之间的差异是很好的 — 一组由RPN网络产生,另一组由分类网络产生。第一组用于训练RPN层以产生良好的前景bounding boxes(更紧密地围绕对象边界)。目标回归系数,即将ROI框与其最接近的ground truth的bounding box对齐所需的系数由anchor target layer生成。很难准确识别这种学习是如何工作的,但我想象RPN卷积和全连接层学习如何将神经网络生成的各种图像特征解释为解码好的对象bounding boxes。当我们在下一节中考虑推理时,我们将看到如何使用这些回归系数。
第二组bounding box系数由分类层生成。这些系数是类特定的,即对于每个ROI框,每个对象类生成一组系数。这些目标回归系数由proposal target layer生成。注意,分类网络在方形feature map上操作,该方形feature map是应用于head网络输出的仿射变换(如上所述)的结果。然而,由于回归系数对于没有剪切的仿射变换是不变的,因此可以将由proposal target layer计算的目标回归系数与由分类网络产生的目标回归系数进行比较,并且充当有效学习信号。事后看来这一点显而易见,但花了我一些时间来理解。
有趣的是,在训练分类层时,误差梯度也传播到RPN网络。这是因为在crop pooling期间使用的ROI框坐标本身是网络输出,因为它们是将RPN网络生成的回归系数应用于anchor boxes的结果。在反向传播期间,误差梯度将通过crop pooling传播回RPN层。计算和应用这些梯度将非常棘手,但幸运的是,crop pooling API由PyTorch作为内置模块提供,计算和应用梯度的细节在内部处理。这一点在Faster RCNN论文(Ren et al.2015)*的第3.2(iii)节中讨论。
5. 实现细节:Inference
推理期间执行的步骤如下所示:
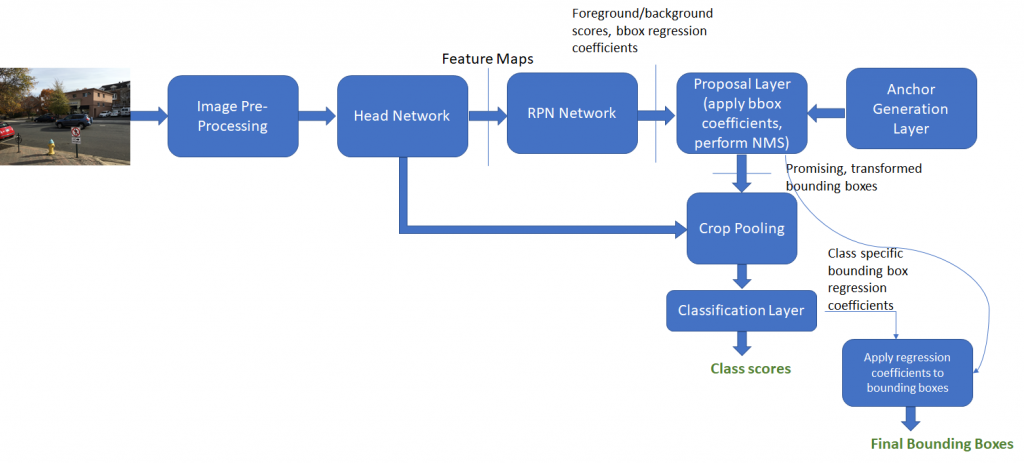
不使用anchor target layer和proposal target layer。RPN网络应该学习如何将anchor分类为背景框和前景框并生成良好的bounding box系数。proposal layer简单地将bounding box系数应用于排名靠前的anchor boxes并执行NMS以消除具有大量重叠的框。为清楚起见,下面显示了这些步骤的输出。生成的框被发送到分类层,在该分类层中生成类分数和类特定的bounding boxes回归系数。
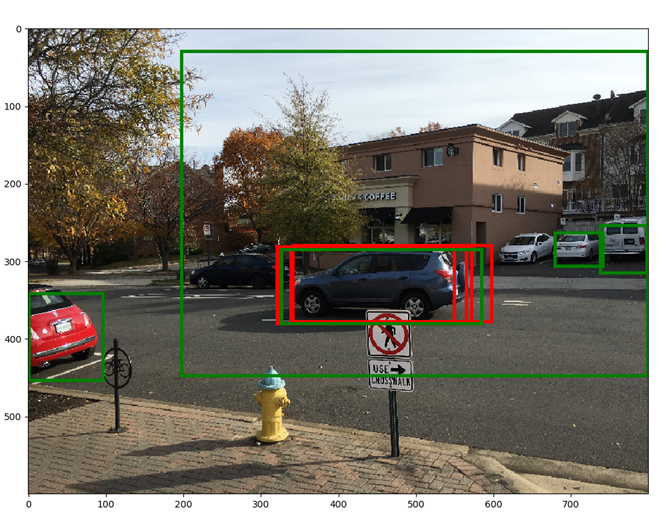
红色框显示按分数排名的前6个anchor。绿框显示应用RPN网络计算的回归参数后的anchor boxes。绿色框似乎更紧密地贴合潜在的对象。注意,在应用回归参数之后,矩形仍然是矩形,即没有剪切。还要注意矩形之间的重要重叠。通过应用非极大值抑制来解决该冗余
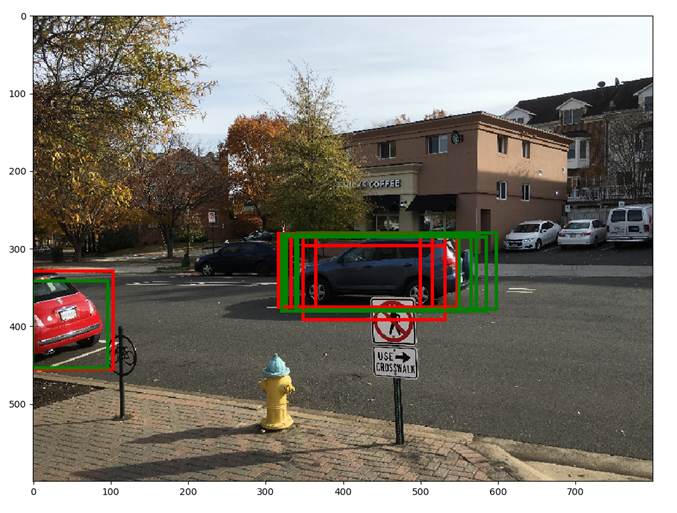
红色框显示NMS前的前5个bounding boxes,绿色框显示NMS之后的前5个框。通过抑制重叠的方框,其他方框(得分列表中的较低位置)有机会向上移动

从最终的分类得分数组(dim:n,21),我们选择对应于某个前景对象的列,比如说汽车。然后,我们选择与此数组中最大分数对应的行。此行对应于最有可能是汽车的proposal。设这个行的索引为car_score_max_idx现在,让最终bounding boxes坐标数组(在应用回归系数之后)为bbox(dim:n,21 * 4)。从这个数组中,我们选择对应于car_score_max_idx的行。我们期望对应于汽车列的bounding box应该比其他bounding box(对应于错误的对象类)更好地适合测试图像中的汽车。确实如此。红色框对应于原始proposal,蓝色框是计算的汽车类bounding boxes,白色框对应于其他(不正确的)前景类。可以看出,蓝色盒子比其他盒子更适合实际的汽车。
为了显示最终的分类结果,我们应用另一轮NMS并将目标检测阈值应用于类别分数。然后,我们绘制对应于满足检测阈值的ROI的所有变换的bounding box。结果如下所示。
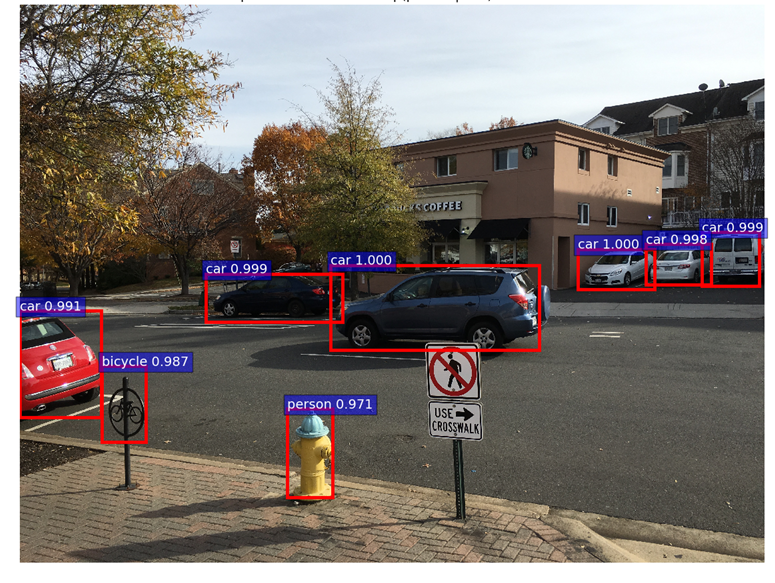
6. 附录
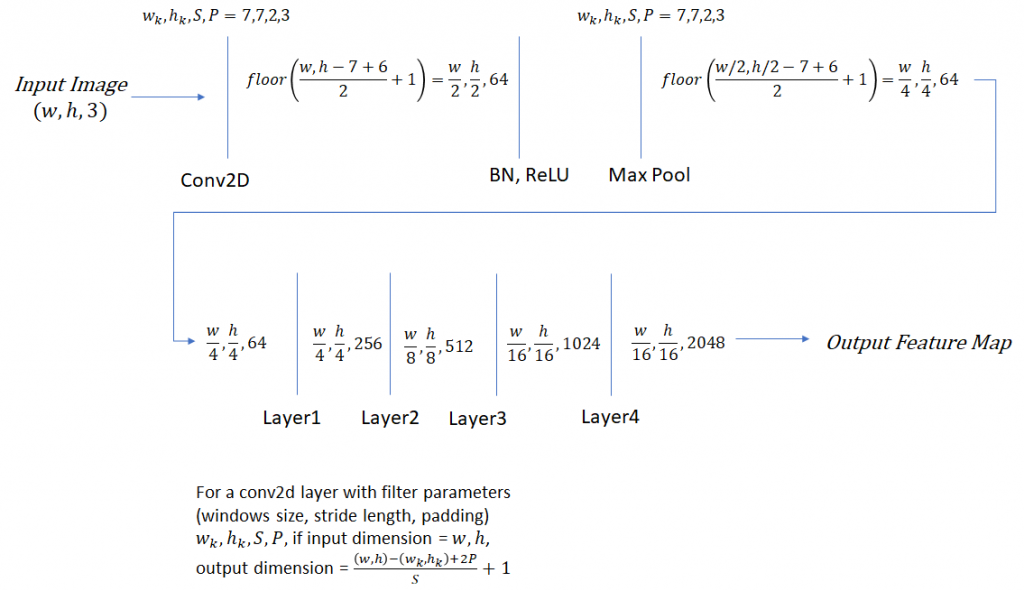
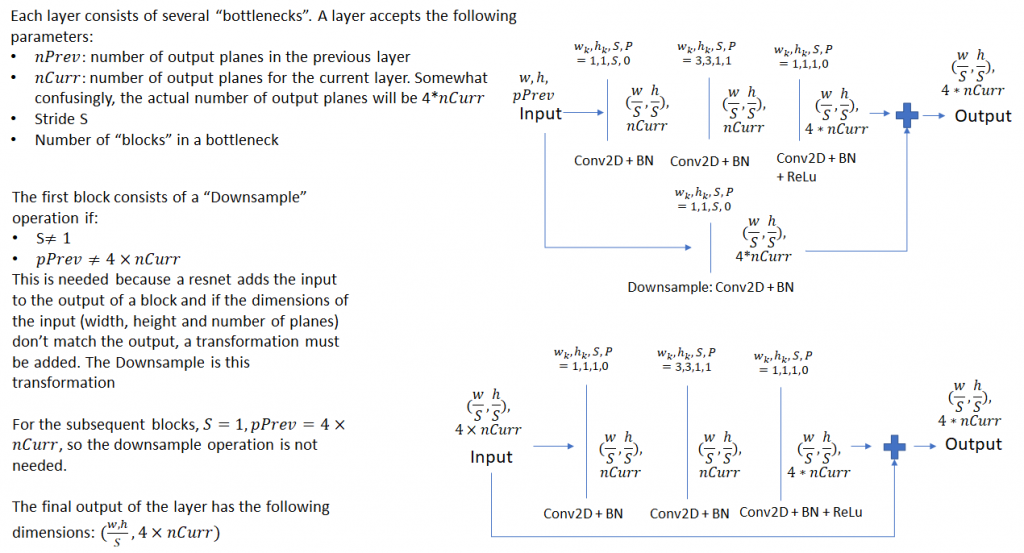
6.1. ResNet 50网络架构
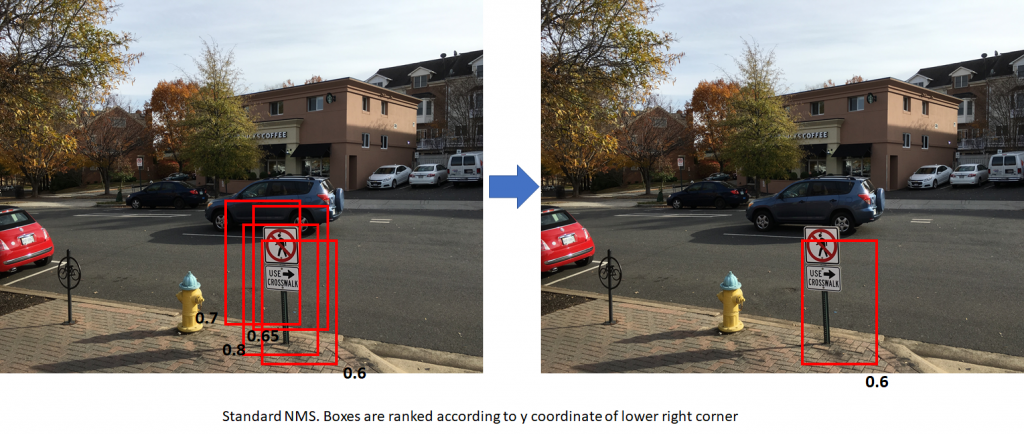
6.2. 非极大值抑制(NMS)
非极大值抑制是一种通过消除重叠大于一个数值的框来减少候选框数量的技术。这些框首先按一些标准排序(通常是右下角的y坐标)。然后,我们浏览框的列表并禁止与所考虑框IoU重叠超过阈值的框。按y坐标对框进行排序会导致保留一组重叠框中的最低框。这可能并不总是理想的结果。R-CNN中使用的NMS按前景分数对框进行排序。这导致保留一组重叠框中具有最高分数的框。下图显示了两种方法之间的差异。黑色数字是每个框的前景分数。右侧的图像显示了将NMS应用于左侧图像的结果。第一个数字使用标准NMS(方框按右下角的y坐标排列)。这导致保留较低分数的框。第二个数字使用修改的NMS(框按前景分数排名)。这导致保留具有最高前景分数的框,这是更期望的。在这两种情况下,假设框之间的重叠高于NMS重叠阈值。

7. 参考
Anon. 2014. . October 23. https://arxiv.org/pdf/1311.2524.pdf.
Anon. 2016. . February 5. https://arxiv.org/pdf/1506.02025.pdf.
Anon. . http://link.springer.com/article/10.1007/s11263-013-0620-5.
Anon. Object Detection with Discriminatively Trained Part-Based Models - IEEE Journals & Magazine. https://doi.org/10.1109/TPAMI.2009.167.
Girshick, Ross. 2015. Fast R-CNN. arXiv.org. April 30. https://arxiv.org/abs/1504.08083.
Girshick, Ross, Jeff Donahue, Trevor Darrell, and Jitendra Malik. 2013. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv.org. November 11. https://arxiv.org/abs/1311.2524.
Ren, Shaoqing, Kaiming He, Ross Girshick, and Jian Sun. 2015. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv.org. June 4. https://arxiv.org/abs/1506.01497.
Yosinski, Jason, Jeff Clune, Yoshua Bengio, and Hod Lipson. 2014. How transferable are features in deep neural networks? arXiv.org. November 6. https://arxiv.org/abs/1411.1792.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号