
etcd -> Highly-avaliable key value store for shared configuration and service discovery
The name "etcd" originated from two ideas, the unix "/etc" folder and "d"istributed systems. The "/etc" folder is a place to store configuration data for a single system whereas etcd stores configuration information for large scale distributed systems. Hence, a "d"istributed "/etc" is "etcd".
Overview
etcd is a distributed key value store that provides a reliable way to store data across a cluster of machines. It's open-source and avaliable on GitHub.etcd gracefully handles leader elections during network partitions and will tolerate machine failure, including the leader.
your applications can read and write data into etcd. A simple use-case is to store database connection details or feature flags in etcd as key value pairs. these values can be watched, allowing your app to reconfigure itself when they change. advanced uses take advantage of the consistency guarantees to implement database leader elections or do distributed locking across a cluster of workers.
Use cases
Kubernets stores configuration data into etcd for service discovery and cluster management; etcd's consistency is crucial for correctly scheduling and operating services. The Kubernetes API server persists cluster state into etcd. It uses etcd's watch API to monitor the cluster and roll out critical configuration changes.
Features
- 简单:基于Http+Json的API让你用curl命名即可轻松使用,使用Go语言编写部署简单。
- 安全:可选SSL客户认证机制。
- 快速:每个实例每秒支持1000次写操作。
- 可信:使用Raft算法充分实现了分布式。
架构
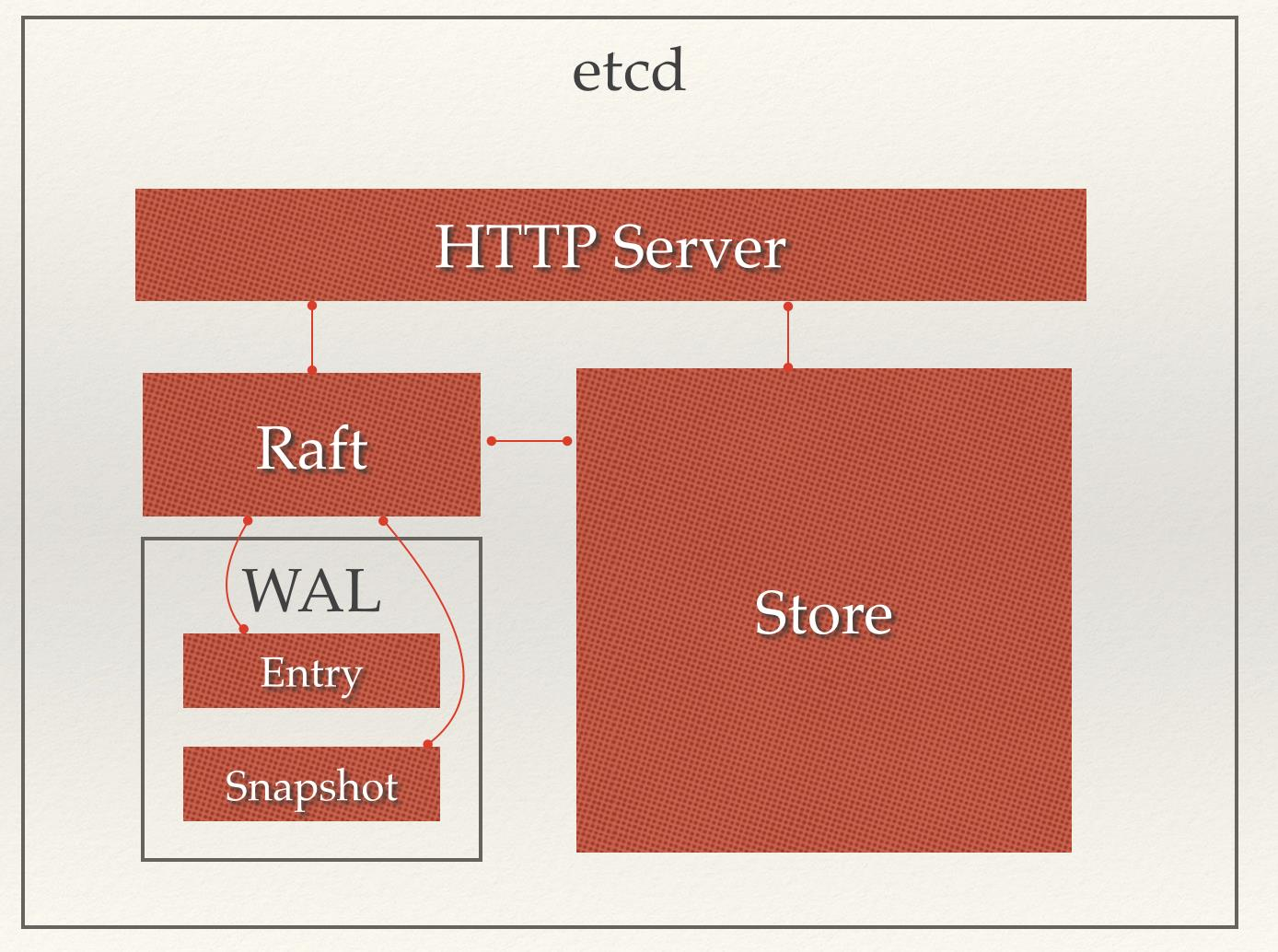
从etcd的架构图中我们可以看到,etcd主要分为四个部分:
- HTTP Server: 用于处理用户发送的API请求以及其它etcd节点的同步与心跳信息请求。
- Store:用于处理etcd支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是etcd对用户提供的大多数API功能的具体实现。
- Raft:Raft强一致性算法的具体实现,是etcd的核心。Raft算法介绍:http://www.jdon.com/artichect/raft.html
- WAL:Write Ahead Log(预写式日志),是etcd的数据存储方式。除了在内存中存有所有数据的状态以及节点的索引以外,etcd就通过WAL进行持久化存储。WAL中,所有的数据提交前都会事先记录日志。Snapshot是为了防止数据过多而进行的状态快照;Entry表示存储的具体日志内容。
通常,一个用户的请求发送过来,会经由HTTP Server转发给Store进行具体的事务处理,如果涉及到节点的修改,则交给Raft模块进行状态的变更、日志的记录,然后再同步给别的etcd节点以确认数据提交,最后进行数据的提交,再次同步。
场景1. Service Discovery
Service Discovery 要解决的是分布式系统中最创建的问题之一,即在同一个分布式集群中的进程或服务如何才能找到对方并建立连接。从本质上说,服务发现就是想要了解集群中是否有进程在监听TCP或UDP端口,并且通过名字就可以进行查找和连接,要解决Service Discovery的问题需要有下面三大支柱,缺一不可:
- 一个强一致性,高可用的服务存储目录。基于Raft算法的etcd天生就是强一致性高可用服务存储目录。
- 一种注册服务和监控服务监控状态的机制。用户可以在etcd中注册服务,并对注册的服务设置Key TTL, 定时保持服务的心跳以达到监控监控状态的效果。
- 一种查找和连接服务的机制。通过在etcd指定的主题下注册的服务也能在对应的主题下查找到,为了确保连接,我们可以在每个服务机器上都部署一个Proxy模式的etcd,这样就可以确保能够访问etcd集群的服务都能互相连接。
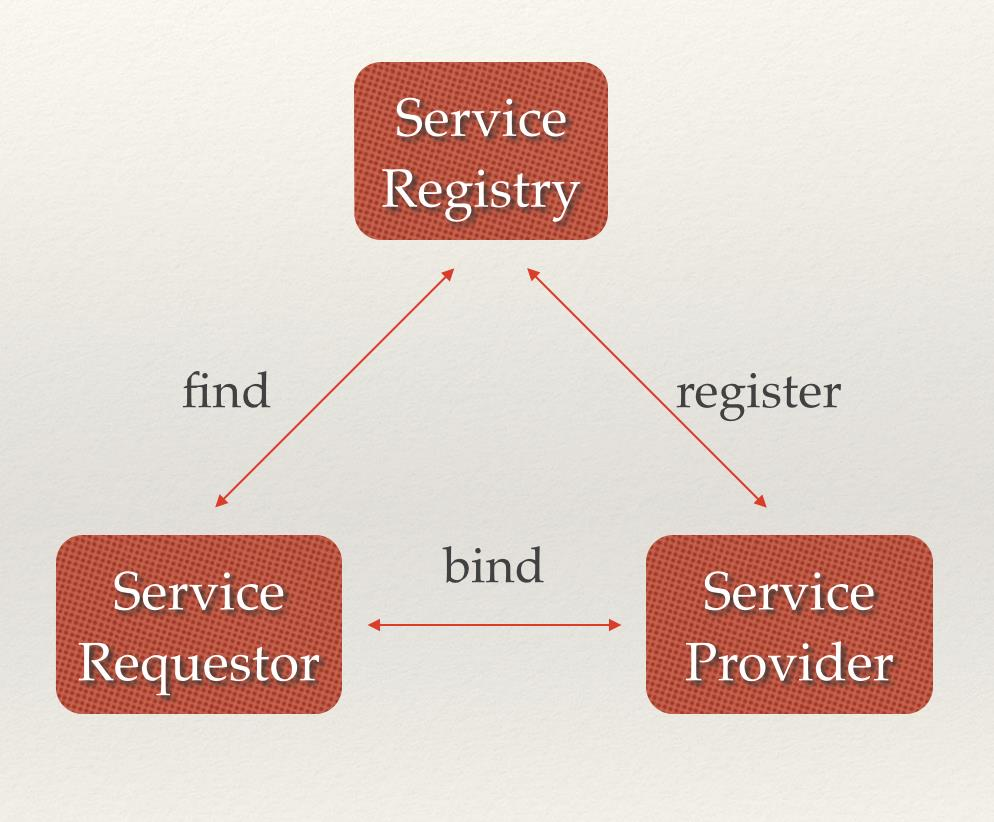
微服务协同工作架构中,服务动态添加。随着Docker容器的流行,多种微服务共同协作,构成一个相对功能强大的架构的案例越来越多。透明化的动态添加这些服务的需求也日益强烈。通过服务发现机制,在etcd中注册某个服务名字的目录,在该目录下存储可用的服务节点的IP。在使用服务的过程中,只要从服务目录下查找可用的服务节点去使用即可。

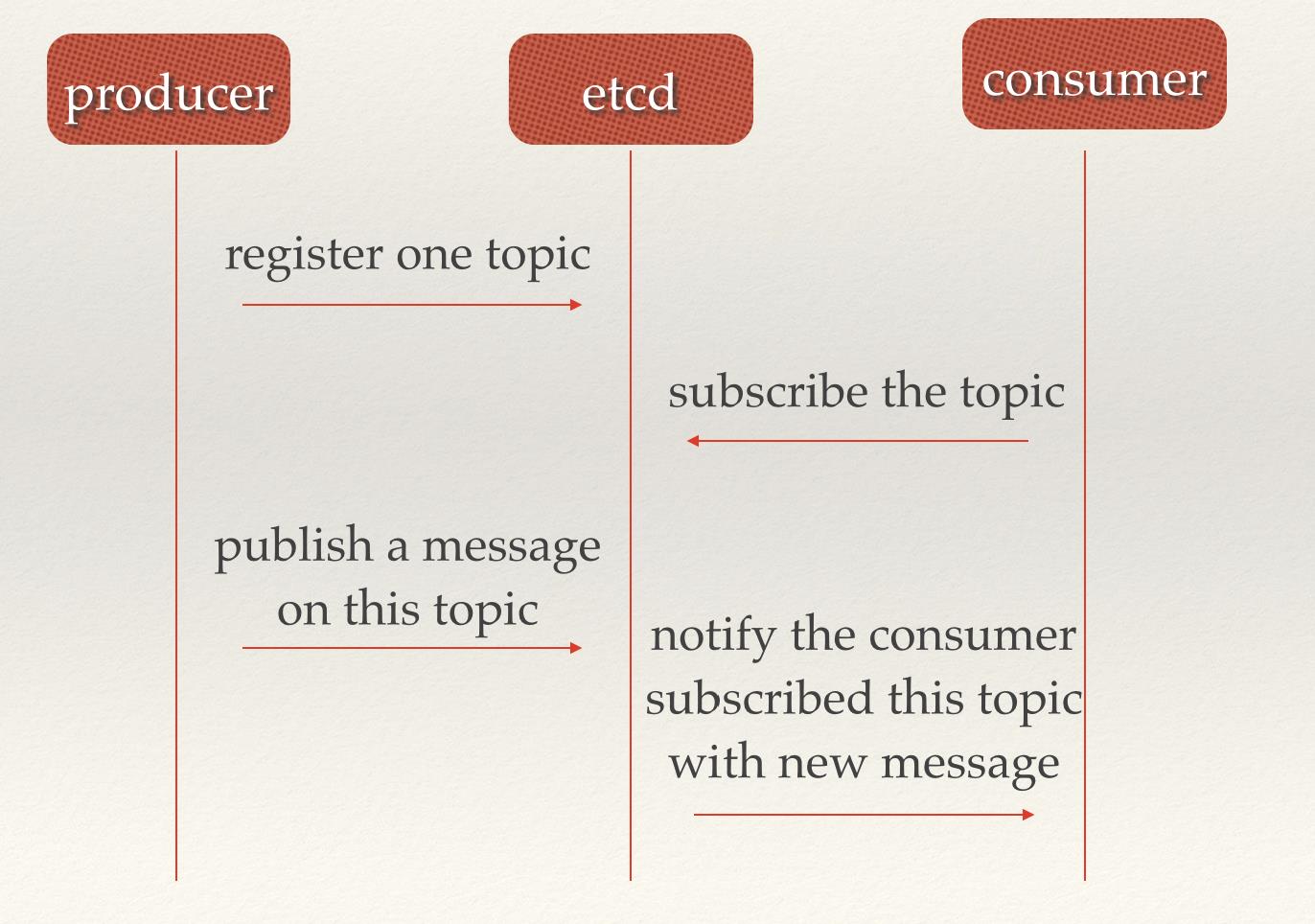
场景二:消息发布与订阅
在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅。即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者。通过这种方式可以做到分布式系统配置的集中式管理与动态更新。
场景三:分布式通知与协调
这里说到的分布式通知与协调,与消息发布和订阅有些相似。都用到了etcd中的Watcher机制,通过注册与异步通知机制,实现分布式环境下不同系统之间的通知与协调,从而对数据变更做到实时处理。实现方式通常是这样:不同系统都在etcd上对同一个目录进行注册,同时设置Watcher观测该目录的变化(如果对子目录的变化也有需要,可以设置递归模式),当某个系统更新了etcd的目录,那么设置了Watcher的系统就会收到通知,并作出相应处理。

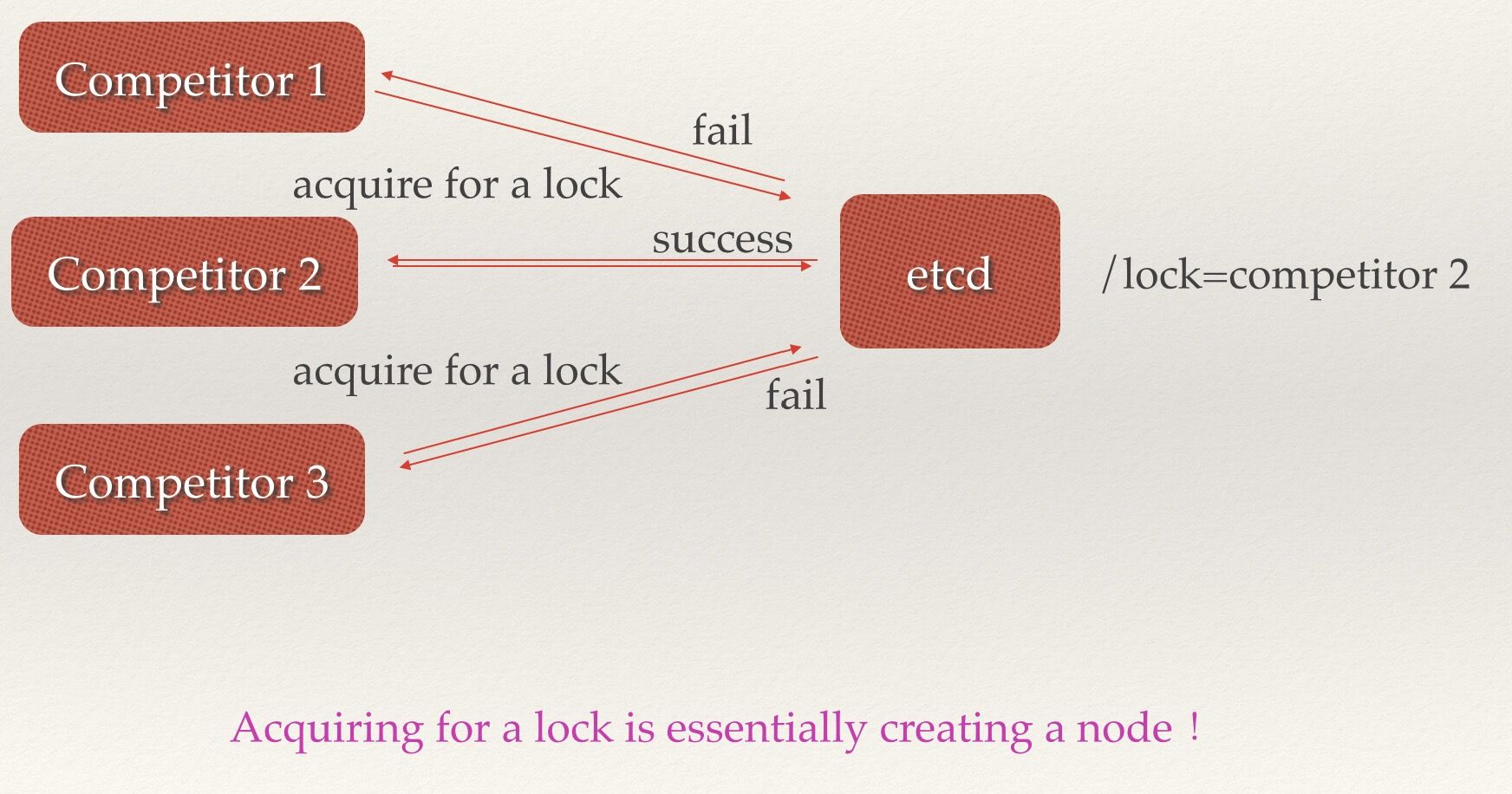
场景四:分布式锁
因为etcd使用Raft算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致的,所以很容易实现分布式锁。锁服务有两种使用方式,一是保持独占,二是控制时序。
- 保持独占即所有获取锁的用户最终只有一个可以得到。etcd为此提供了一套实现分布式锁原子操作CAS(CompareAndSwap)的API。通过设置prevExist值,可以保证在多个节点同时去创建某个目录时,只有一个成功。而创建成功的用户就可以认为是获得了锁。
- 控制时序,即所有想要获得锁的用户都会被安排执行,但是获得锁的顺序也是全局唯一的,同时决定了执行顺序。etcd为此也提供了一套API(自动创建有序键),对一个目录建值时指定为POST动作,这样etcd会自动在目录下生成一个当前最大的值为键,存储这个新的值(客户端编号)。同时还可以使用API按顺序列出所有当前目录下的键值。此时这些键的值就是客户端的时序,而这些键中存储的值可以是代表客户端的编号。
参考资料:
http://www.infoq.com/cn/articles/etcd-interpretation-application-scenario-implement-principle

