


Celery 最佳实践
转载:https://www.jianshu.com/p/7029a449b4de
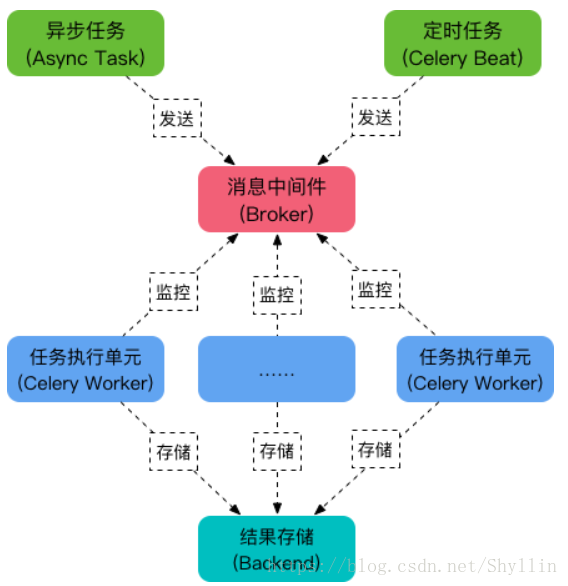
Celery架构
1.用好celery beat
如果你想更好的管理项目的定时任务,可以用celery beat代替crontab管理。celery不仅支持动态的异步任务(通过delay调用),也支持定时任务执行。当然我们可以用crontab实现任务的定时执行,但是crontab是与项目代码隔离的,为了更方便地管理定时任务用celery beat代替也是一个不错的选择。celery beat是celery额外起的一个进程,具体命令行:
celery -A yourApp beat
该进程开启后会根据配置定期的发送任务到broker中,最终任务的执行还是由worker执行:
celery -A yourApp worker
2.参数传递
大多数场景下传递任意数据时可行的,但是如果数据内容本身是可变的,那么这时候就要仔细考虑了。假定参数是一个对象,这个对象映射到数据库中的一行数据,如果任务在等待执行的过程中该行数据有改变,那么在任务执行的时候,使用到的这个对象就是一个过期数据。所以尽量传递不变(这里的不变与python不可变数据类型不是一个概念)的参数。
3.序列化方式
celery支持多种序列化方式,但是每种序列化方式产生的数据大小是不同的,如果在broker吞吐量存在瓶颈的情况下,可以选择产生数据较小的序列化方式
4.使用计划任务
假定有这样一个场景,用户创建了订单,减少了商品库存,但是还未支付,这时候需要给用户一个限定的支付时间如半个小时,如果半个小时之后这笔订单还未支付,那么就撤销该订单,重置商品库存。这个时候可以用到celery的计划任务,也就是任务发出后并不会马上执行,会在指定的时间点执行。我们可以用countdown或者eta参数实现该功能:
task.apply_async(countdown=300)
task.apply_async(eta=datetime.now() + timedelta(minutes=30) - timedelta(hours=8))
eta给到的时间有时区的问题,所以我在上述代码中减去了八个小时。
5.任务优先级
如果执行的任务相同,但是这些相同的任务会有不同的优先级,如果想使某个任务具有更高的优先级,那么可以使用priority参数来完成。
task.apply_async(priority=9)
这里会存在一个问题。redis broker的priority只支持0、3、6、9四个级别,底层的实现方式是用不同的队列来实现的。大致的做法是为每个优先的任务生成一个队列,更高优先级的任务投递到更高优先级的队列,worker工作的时候更倾向于从高优先级队列获取任务。
6.broker的选择
不要使用mysql作为broker。虽然celery支持mysql作为broker,但我们还是不要用mysql,因为如果任务量一旦上来,mysql会存在大量的磁盘io,不利于任务系统良好的运行。rabbitmq是官方推荐的broker,也是完全实现了amqp协议的broker。相比较而言,redis更轻量级,但也是一个较好的选择。
7.worker命名
给celery worker指定一个唯一的名字,可以让我们更好的区分不同的worker。可以用-n参数指定name
8.为不同的队列开启不同的worker
我们尽量给不同的任务指定不同的队列,有的任务具有更高的优先级,有的反而没那么重要,所以分开来是有必要的。在开启的worker的时候指定队列,执行一组相同的任务。
9.选择合适的并发方式
celery提供了几种并发方式,包括prefork、gevent、eventlet等,如果执行的任务是cpu密集型的可以选择prefork的方式(也是默认的方式),如果是网络io密集型的可以选择gevent或者eventlet,这两者都用到了io多路复用的技术。选择恰当的并发方式可能可以极大的提升处理能力。并发数的选择也需要考虑一下,并不是越多越好,多了需要处理大量的上下文切换,少了不能明显提高性能,这里可能需要一个测试。
10.执行的幂等性
对于broker而言,任务重复下发是存在的,虽然这种可能性微乎其微。所以对于同一个任务,即使多次执行,不会也不应该产生数据异常。这需要在代码层面实现。
11.小心使用retry
retry的机制未深入研究,但是在我工作初期,因为不当地使用retry,导致任务指数级的增长,最终整个broker塞满了消息。大致是因为任务失败后同时retry了两次,并且下一次执行还是失败,继续两次retry(此时总的是4次retry),如此指数增长。
12.给任务设置timeout
如果不给单个任务设置超时时间,一旦某个任务卡死(比如产生死锁),整个worker将一直不可用,除非重启。可以使用--time-limit参数指定超时时间。
13.接入sentry
接入sentry可以让我们快速定位错误,解决问题。
14.backend设置
celery的backend是指任务执行结果的存储服务,一般用redis作为backend即可。执行task.apply_async()方法后生成一个result对象,调用result.get()可以从backend中读取结果。当然如果对执行的结果不关心可以配置celery为ignore result,此时不会存储结果。如果需要存储结果,也需要给结果设置一定的超时时间。
15.flower监控
flower是celery的一个可视化监控工具。我们可以从上面看到如worker工作情况、队列长度等信息,也可以执行远程控制等操作。出现问题时,celery监控系统可能会帮助使用者更快的定位问题。
作者:Devops_cheers
链接:https://www.jianshu.com/p/7029a449b4de
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

